 Alexey
Alexey


Просто написано, что в mongos это не определено
Alexey
Прошу прощения за тупые вопросы, не спал всю ночь из-за этого
 yopp
yopp
For a sharded cluster that has access control enabled, to run the command against a member of the shard replica set, you must connect to the member as a shard local user.
yopp
А шард доступен?
yopp
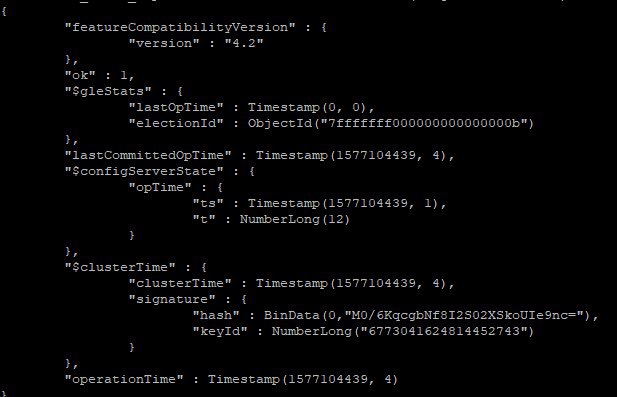
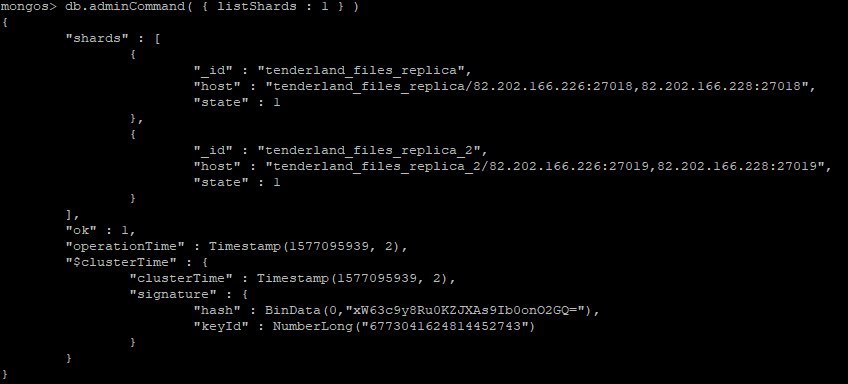 Alexey
Alexey
Проверьте что mongos может сделать запрос в sharded коллекцию
Я не думаю, что хоть одна коллекция у меня шардирована. Первая реплика весит очень много, а вторая 350 мб
Alexey
делал enableSharding() для каждой бд, но не помогло
yopp
Убедитесь что у вас все ноды, монгосы и шеллы в кластере на одной минорной версии. Идеально на 4.2.2
Alexey
Убедитесь что у вас все ноды, монгосы и шеллы в кластере на одной минорной версии. Идеально на 4.2.2
все кроме mongos 4.2.1, mongos - 4.2.2
Alexey
Нежели разница в минорной версии может дать такие проблемы?
yopp
Обновитесь до 4.2.2
yopp
Всё может быть
Alexey
А какая процедура обновления для докера? Остановить контейнер, сделать пулл и дальше создавать контейнер заново?
yopp
Примерно, да. Убедитесь что разделы не в сам контейнер смонтированы
Alexey
Примерно, да. Убедитесь что разделы не в сам контейнер смонтированы
Да, данные я замаппил на внешнюю от контейнера папку. Примерно понятно. Спасибо за помощь, обязательно отпишусь!
 Murena
Murena
Всем привет подскажите как правильно сделать запрос есть например документ типа
name: 'Alex',
emails: [
{ addres: sdsds@uk.net, comments: 'asdasd', emailName: 'first' },
{ addres: sdsds2@uk.net, comments: 'asd2asd', emailName: 'first' },
{ addres: sdsds3@uk.net, comments: 'asd2asd', emailName: 'first' }
]
я хочу найти в документе определенный email и получить результат только с одним email с массива - по типу что то примерно такого
name: 'Alex',
emails: [
{ addres: sdsds3@uk.net, comments: 'asd2asd', emailName: 'first' }
]
без остальных имею ввиду, или так
name: 'Alex',
emails: { addres: sdsds3@uk.net, comments: 'asd2asd', emailName: 'first' }
как это правильно сделать ?
 Dmitriy
Dmitriy
должно помочь
Murena
спасибо, попробую
Murena
еще такой вопрос, можно ли в монге делать ссылку/связь на елемент массива другого документа в другой схеме ?
Murena
или связываются только целые документы - без возможности связывать конкретно ихние вложености ?
Dmitriy
в монго вообще нет как таковых связей, уточните конкретную бизнес задачу, чтобы можно было понять, что вы имеете в виду
Murena
в монго вообще нет как таковых связей, уточните конкретную бизнес задачу, чтобы можно было понять, что вы имеете в виду
задача следующая: Есть книги (их например 10 тыс), в каждой книге по 20 тыс слов (каждое слово это обьект со значением что за слово и где оно находится в книге). Задача сделать поиск по всем словам и фразам во всех книгах.
То к чему я пришел как это сделать с помощью монги - это создать две схемы - в первой схеме находятся документы с уникальными словами - в каждом документе есть массив елементов со ссылкой на книги в которых это слово встречалось и где именно встречалось. Вторая схема это схема в которой будут документ - это книга с массивом всех слов которые есть в книге (слова это обьекты - что за слово и где находится)
И для первой схемы там где слова включить Mongo full text search индексацию чтоб быстро искать слова.
Murena
И хотелось бы чтоб можно было в первую схему где уникальные слова находятся - с массивом слов в котором ссылка на книгу в которой это слово стречалось и где - сделать просто массив ссылок/связей прямо на конкретное слово в книге - которая в другой схеме - а не на всю книгу делать ссылку и потом делать выборку по словам в книге
Murena
Или может есть какой то другой подход к реализации подобного
yopp
У вас текст хранится как массив слов?
Murena
У вас текст хранится как массив слов?
в первоначальном виде текст хранится как массив обьектов в котором каждое слово это { value: 'привет', indexPosition: 567, page: 10 }
Murena
indexPosition потом может использоватся для поиска фраз
yopp
А зачем вам тогда ссылка на элемент в массиве?
Murena
А зачем вам тогда ссылка на элемент в массиве?
я чтоб не проходится по всему массив слов в книге - сделал с этого массива обьект (по типу шех таблицы) где слово это key а значение это массив этих обьектов { value: 'привет', indexPosition: 567, page: 10 } получается можно не проходясь по всему массиву сразу получить все слова привет в книге например
yopp
А какую задачу вы пытаетесь решить?
yopp
Вы храните оригинальное слово или основание?
yopp
Или лемму?
Murena
я хочу в бд хранить оригинальное слово (уникальное) - и массив ссылок/связей на те места в книгах где это слово встречалось.
Murena
первая схема это схема с уникальными словами / а вторая схема это схема где каждый документ это книга с массивом слов
yopp
Самый простой вариант хранить обратную ссылку в том виде, в котором у вас хранится прямая. Т.е. BookId, PageId, WordIndex со стороны слова и Word, PageId, WordIndex со стороны книги.
Сразу рекомендую книгу хранить постранично, раз у вас уже есть page
Murena
получается я хочу в первую схему где уникальное слово - передавать просто ссылки/связь на книгу а именно на елемент массива где конкренто это слово.
yopp
Тоже самое со словами, хранить обратные ссылки сгруппировав в бакеты, например по книгам
Murena
в монге можно создавать ссылку на вложеность документа (А именно на массив) ?
Murena
вроде я читаль что нельзя - только на целый документ
yopp
Т.е. в духе
pages:
{
book_id: ObjectId,
page_number: Integer,
words: [{word: String, offset: Integer}...]
}
words:
{
word: String,
book_id: ObjectId,
locations: [{page_id:, offset: Integer}],
bucket: Integer
}
yopp
В монге нет ссылок
yopp
Ссылка это уровнь приложения
yopp
Т.е. в духе
pages:
{
book_id: ObjectId,
page_number: Integer,
words: [{word: String, offset: Integer}...]
}
words:
{
word: String,
book_id: ObjectId,
locations: [{page_id:, offset: Integer}],
bucket: Integer
}
Вот тут схему возможно можно улучшить храня слова по страницам, вместо простого бакета
yopp
но это надо смотреть на реальное частотное распределение слов по страницам
yopp
Тогда будет что-то в духе
words:
{
word: String,
book_id: ObjectId,
page_number: Int,
offsets: [Integer, ...]
}
Murena
понял, спасибо ! Буду пробовать.
yopp
Такая схема во-первых решить проблему с большими документами, во-вторых позволит очень компактно сделать оба индекса
yopp
У второго варианта ещё плюс иерархичность индекса
yopp
Т.е. найти страницы на которых было слово можно только по индексу
yopp
На мой взгляд не обязательно хранить смещение
yopp
Можно упростить и хранить только номера страниц, а там уже на самой странице найти слова
yopp
Понимаю почему вы хотите хранить оригинальные слова в массиве, но я бы попробовал хранить ObjectId/Int64 слова и посмотрел бы насколько дорого выбирать слова из базы чтоб восстановить их по ацдишнику
yopp
Плюс такого подхода в ощутимом уменьшении размера индекса по слову
yopp
Ну и главное, что если сделать отдельную коллекцию со словам, то вы уже будете в одном шаге от самопального полнотекстового поиска. Надо будет только добавить стеммер и в слово добавить его нормальную форму и по этому всему сделать индекс :)
yopp
Т.е.
words:
{ _id: ObjectId|Int64, word: String, lemma: ObjectId|Int64 }
books:
{
title: Stirng,
<other_metadata>
}
books_words:
{
book_id: ObjectId,
page_id: Integer,
words: [{word_id: , offset: Integer}]
}
words_books:
{
word_id: ,
book_id: ObjectId,
pages: [ObjectId]
}
Или
{
word_id:
book_id:
page_id:
offsets: [Integer],
}
Или
{
word_id:
book_id:
pages: [{
page_id: ObjectId,
offsets: [Integer, ...]
}]
}
yopp
Что лучше видно будет только если протестировать
yopp
Т.е.
words:
{ _id: ObjectId|Int64, word: String, lemma: ObjectId|Int64 }
books:
{
title: Stirng,
<other_metadata>
}
books_words:
{
book_id: ObjectId,
page_id: Integer,
words: [{word_id: , offset: Integer}]
}
words_books:
{
word_id: ,
book_id: ObjectId,
pages: [ObjectId]
}
Или
{
word_id:
book_id:
page_id:
offsets: [Integer],
}
Или
{
word_id:
book_id:
pages: [{
page_id: ObjectId,
offsets: [Integer, ...]
}]
}
А что самое интересное, с Integer64 можно нижние несколько бит, например 12, оставить под номер словоформы и для леммы делать с номер с битами выставленными в ноль
 Boris
Boris
✋господа, привет! Подскажите плиз, существует ли ограничение на кол-во элементов в массиве, которые передаются в оператор $in при find() запросе? В официальной доке инфы по этому поводу не нашел (или плохо искал) в остальных интернетах тоже ничего.
yopp
✋господа, привет! Подскажите плиз, существует ли ограничение на кол-во элементов в массиве, которые передаются в оператор $in при find() запросе? В официальной доке инфы по этому поводу не нашел (или плохо искал) в остальных интернетах тоже ничего.
В wire protocol все команды упаковываются в BSON, так что размер одного запроса ограничен примерно 16мб (за вычетом метаданных, там до десятка полей)
Boris
В wire protocol все команды упаковываются в BSON, так что размер одного запроса ограничен примерно 16мб (за вычетом метаданных, там до десятка полей)
хм, действительно. Не с той стороны искал. Спасибо!
yopp
В 4.2 добавили фрагментацию документов в оплоге, чтоб транзакции больше 16мб можно было вставлять, так что возможно в wire protocol тоже добавили фрагментацию, я не смотрел ещё
Boris
В 4.2 добавили фрагментацию документов в оплоге, чтоб транзакции больше 16мб можно было вставлять, так что возможно в wire protocol тоже добавили фрагментацию, я не смотрел ещё
ага, добавили https://jira.mongodb.org/browse/SERVER-36330
yopp
Не всё так очевидно с Op_msg. Там есть document sequence type
yopp
Сами команды внутри транзакции отправляются не одним документом
yopp
Они отправляются как отдельные команды в рамках конкретной сессии
yopp
Я бы рассчитывал на 16мб
Murena
https://docs.mongodb.com/manual/reference/operator/aggregation/filter/
Подскажите есть ли что то подобное как filter для массива, только нужно с обьекта отфильтровать определенные поля ? Или только через $reduce (aggregation) ?
Dmitriy
Подскажите есть ли что то подобное как filter для массива, только нужно с обьекта отфильтровать определенные поля ? Или только через $reduce (aggregation) ?
что вы имеете под отфильтровать с массива только определенные поля? получить на выходе только определенные поля объекта?
Murena
да - на выходе получить определенные елементы с массива - это делается через $filter насколько я понял
Murena
а нужно тоже самое - но нужно только на выходе получить определенные поля с обьекта
Dmitriy
ну как вариант сделайте после $filter еще $unwind и по полученному набору записей $project