 Semyon V
Semyon V


{
_id: ObjectId(“1”),
subItem: {
field1: 123,
}
}
{
_id: ObjectId(“2”),
duplicateOf: ObjectId(“1”),
subItem: {
field5: “string”,
}
}
 yopp
yopp
{
_id: ObjectId(“1”),
subItem: {
field1: 123,
}
}
{
_id: ObjectId(“2”),
duplicateOf: ObjectId(“1”),
subItem: {
field5: “string”,
}
}
Какую сущность описывает этот объект?
Semyon V
продукт
yopp
И у разных видов продуктов разные поля?
 Sergey
Sergey
Поищите от чего у вас шард нагибается. Вероятно это праймари шард и ему не хватает ресурсов
С этим проблем нет. Мы словили неприятный баг с балансировкой, который приводил к зависанию части запросов на одной из реплик в одном из шардов. Эти запросы тупо забили весь пул. Хотя там даже не primary реплика была. https://jira.mongodb.org/browse/SERVER-42737, очень ждём релиза 4.0.14 с фиксом.
Были ещё случаи, когда неосторожные действия в продакшене приводила к перегрузке одной из secondary с аналогичным результатом.
Semyon V
да. у каких-то есть duplicateOf, у каких-то есть subitem.field5
Sergey
Передо мной сейчас стоит вопрос, стоит ли упарываться в сторону устойчивости сервиса при подобных проблемах. Или ограничиться исправлением первопричин и мерами вроде увеличения пулов.
yopp
Первопричины и пулы
yopp
да. у каких-то есть duplicateOf, у каких-то есть subitem.field5
для продуктов эффективнее использовать Attribute Type паттерн
products:
{
_id: ...,
<common_fields>,
attrs: [
{type: ObjectId(...), value: "foo"},
{type: ObjectId(...), value: "bar"},
{type: ObjectId(...), value: 53},
]
}
attribute_types:
{
_id: ObjectId(...),
value_type: "String",
name: "Color"
}
yopp
а вот duplicateOf это сложный вопрос
Semyon V
может как один из атрибутов?
yopp
зависит от вашей бизнес-логики
Semyon V
хотя выборка по ней опять же вряд ли будет эффективной…
yopp
если duplicateOf это просто признак, то это одна история
если это механизм наследования, то это другая
Semyon V
ну чаще всего я использую { duplicateOf: { $exists: false } } как первый шаг агрегации для отсеивания ненужных.
yopp
а зачем и какая логика у duplicateOf?
Semyon V
но да, это ещё и признак, по которому я также могу делать запрос вроде, получить все дубликаты такого-то ObjectId
Semyon V
@dd_bb, а что если duplicateOf будет одним из атрибутов?
Semyon V
ах, тогда наверное поиск по конкретному значению будет не очень эффективным...
 Anonymous
Anonymous
ребят в каком формате лучше хранить html в mongodb?
Anonymous
есть выбор между мнемоникой и json или же обычным html
 Denis
Denis
ребят в каком формате лучше хранить html в mongodb?
не хранить html в базе
а хранить ссылку на cdn
Denis
непонял
ну html это статика, а хорошая практика статику класть в cdn (например amazon s3, или самому захостить опенсорсный аналог)
Anonymous
ну html это статика, а хорошая практика статику класть в cdn (например amazon s3, или самому захостить опенсорсный аналог)
хз геморой я хочу у себя в базе
Denis
у тебя в базе будут лежать прямые url на эти файлы
Anonymous
у тебя в базе будут лежать прямые url на эти файлы
я понял, а хранить html в базе это безопасно?
yopp
@dd_bb, а что если duplicateOf будет одним из атрибутов?
какая логика у duplicateOf и какую задачу вы решаете черещ $exists: true?
Anonymous
какая логика у duplicateOf и какую задачу вы решаете черещ $exists: true?
спасибо но решил вопрос по другому, у редактора есть кроме html формат json. я его просто через strinify буду добовлять а вытаскивать через parse и через htmlparser добовлять
Semyon V
какая логика у duplicateOf и какую задачу вы решаете черещ $exists: true?
1) https://t.me/MongoDBRussian/64540
2) https://t.me/MongoDBRussian/64542
yopp
а, exists: false. а почему именно так?
Semyon V
ну, чтобы отсеить группу ненужных объектов в выборке
yopp
а почему они ненужные?
Semyon V
ну, такая задача возникает, производить поиск по объектам, в которых этого свойства нет. или в другой раз, где оно есть
yopp
а сколько у вас документов сейчас?
Semyon V
~80000
yopp
сделайте индекс и не парьтесь пока
Semyon V
он есть
yopp
тогда не парьтесь
Semyon V
😐
Semyon V
1 секунда только на первый шаг агрегации уходит
yopp
что говорит explain?
yopp
explain({executionStats: 1})
Semyon V
{
"stage" : "IXSCAN",
"keyPattern" : {
"duplicateOf" : 1
},
"indexName" : "duplicateOf_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"duplicateOf" : []
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"duplicateOf" : [
"[MinKey, MaxKey]"
]
}
}
Semyon V
{
"executionSuccess" : true,
"nReturned" : 23768,
"executionTimeMillis" : 756,
"totalKeysExamined" : 85047,
"totalDocsExamined" : 85047,
"executionStages" : {
"stage" : "FETCH",
"filter" : {
"duplicateOf" : {
"$exists" : true
}
},
"nReturned" : 23768,
"executionTimeMillisEstimate" : 314,
"works" : 85048,
"advanced" : 23768,
"needTime" : 61279,
"needYield" : 0,
"saveState" : 664,
"restoreState" : 664,
"isEOF" : 1,
"invalidates" : 0,
"docsExamined" : 85047,
"alreadyHasObj" : 0,
"inputStage" : {
"stage" : "IXSCAN",
"nReturned" : 85047,
"executionTimeMillisEstimate" : 106,
"works" : 85048,
"advanced" : 85047,
"needTime" : 0,
"needYield" : 0,
"saveState" : 664,
"restoreState" : 664,
"isEOF" : 1,
"invalidates" : 0,
"keyPattern" : {
"duplicateOf" : 1
},
"indexName" : "duplicateOf_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"duplicateOf" : []
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"duplicateOf" : [
"[MinKey, MaxKey]"
]
},
"keysExamined" : 85047,
"seeks" : 1,
"dupsTested" : 0,
"dupsDropped" : 0,
"seenInvalidated" : 0
}
},
"allPlansExecution" : []
}
yopp
а что дальше в пайплайне?
Semyon V
а что дальше в пайплайне?
ничего. это db.items.find( { "duplicateOf": { $exists: true } } )
yopp
"nReturned" : 85047,
"keysExamined" : 85047,
а дальше вы читаете 85к документов
yopp
0.01ms на документ, вполне ничего
Semyon V
мне кажется 700 мс на 85000 документов это уже слишком много
Semyon V
и что-то явно не так
yopp
всё абсолютно так
yopp
попробуйте сделать covered query
yopp
db.items.find( { "duplicateOf": { $exists: true } }, {_id: 0, duplicateOf: 1})
Semyon V
~800 ms
yopp
а что explain показывает?
yopp
а какая у вас версия монги?
Semyon V
4.0.10
Semyon V
winning plan:
{
"stage" : "PROJECTION",
"transformBy" : {
"_id" : 0.0,
"duplicateOf" : 1.0
},
"inputStage" : {
"stage" : "FETCH",
"filter" : {
"duplicateOf" : {
"$exists" : true
}
},
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"duplicateOf" : 1
},
"indexName" : "duplicateOf_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"duplicateOf" : []
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"duplicateOf" : [
"[MinKey, MaxKey]"
]
}
}
}
}
Semyon V
{
"stage" : "PROJECTION",
"nReturned" : 23768,
"executionTimeMillisEstimate" : 435,
"works" : 85048,
"advanced" : 23768,
"needTime" : 61279,
"needYield" : 0,
"saveState" : 665,
"restoreState" : 665,
"isEOF" : 1,
"invalidates" : 0,
"transformBy" : {
"_id" : 0.0,
"duplicateOf" : 1.0
},
"inputStage" : {
"stage" : "FETCH",
"filter" : {
"duplicateOf" : {
"$exists" : true
}
},
"nReturned" : 23768,
"executionTimeMillisEstimate" : 416,
"works" : 85048,
"advanced" : 23768,
"needTime" : 61279,
"needYield" : 0,
"saveState" : 665,
"restoreState" : 665,
"isEOF" : 1,
"invalidates" : 0,
"docsExamined" : 85047,
"alreadyHasObj" : 0,
"inputStage" : {
"stage" : "IXSCAN",
"nReturned" : 85047,
"executionTimeMillisEstimate" : 148,
"works" : 85048,
"advanced" : 85047,
"needTime" : 0,
"needYield" : 0,
"saveState" : 665,
"restoreState" : 665,
"isEOF" : 1,
"invalidates" : 0,
"keyPattern" : {
"duplicateOf" : 1
},
"indexName" : "duplicateOf_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"duplicateOf" : []
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"duplicateOf" : [
"[MinKey, MaxKey]"
]
},
"keysExamined" : 85047,
"seeks" : 1,
"dupsTested" : 0,
"dupsDropped" : 0,
"seenInvalidated" : 0
}
}
}
yopp
попробуйте сделать sparse индекс по $exists: true
Semyon V
индекс по $exists?
yopp
https://docs.mongodb.com/manual/core/index-partial/#create-a-partial-index
yopp
да, $exists: true
yopp
у вас тут shape запроса [minkey, maxkey], а это получается весь индекс попадает в fetch
 Mikhail
Mikhail
/report
Mikhail
Да когдаж вы бота поставите
Anonymous
Как работает regex, точнее поиск.
Интересует выборка без учета регистра, это перебор возможных вариантов ?
То есть [ /^ foo /i), это поиск : FOO, FOo, Foo, foo, FoO, foO и т.д. ? или нет?
Если это перебор, то лучше завести поле <Field1UpperCase> ? и не делать выборку без учета регистра?
А если индекс составной, то он получается массив массивов ?
В таком случае может имеет место создать поле <FieldUpperCast> = <Field1toUpper> + <Field2toUpper> + …..
И делать поиск по нему ?
 Nick
Nick
Как работает regex, точнее поиск.
Интересует выборка без учета регистра, это перебор возможных вариантов ?
То есть [ /^ foo /i), это поиск : FOO, FOo, Foo, foo, FoO, foO и т.д. ? или нет?
Если это перебор, то лучше завести поле <Field1UpperCase> ? и не делать выборку без учета регистра?
А если индекс составной, то он получается массив массивов ?
В таком случае может имеет место создать поле <FieldUpperCast> = <Field1toUpper> + <Field2toUpper> + …..
И делать поиск по нему ?
Регулярки работают как и везде к значению поля применяется регулярка. Если же регулярка содержит символ начала строки, то там в некоторых случаях может быть использован индекс. В общем случае регулярки это зло и лучше поменять подход к хранению данных если это возможно
Nick
Как работает regex, точнее поиск.
Интересует выборка без учета регистра, это перебор возможных вариантов ?
То есть [ /^ foo /i), это поиск : FOO, FOo, Foo, foo, FoO, foO и т.д. ? или нет?
Если это перебор, то лучше завести поле <Field1UpperCase> ? и не делать выборку без учета регистра?
А если индекс составной, то он получается массив массивов ?
В таком случае может имеет место создать поле <FieldUpperCast> = <Field1toUpper> + <Field2toUpper> + …..
И делать поиск по нему ?
Не понял вопроса про составной индекс, если вы хотите чтото оптимизировать, то сначала упритесь в реальные проблемы производительности, чтобы понимать какой профит сможете получить от якобы лучшего вашего варианта составного индекса
Anonymous
Вопрос по созданию архитектуры(модели).
Какие есть альтернативы поиска по части текста ?
Только { $text: { $search: "foo"}}
Nick
Вопрос по созданию архитектуры(модели).
Какие есть альтернативы поиска по части текста ?
Только { $text: { $search: "foo"}}
Прочитайте очень внимательно как работает текстовый поиск в монге, возможно вам не подойдет
Nick
Альтернатив встроенных нет
 Mike
Mike
@yatoba Спам приехал ^
Nick
может вопросник при входе в группу ? как думаете?
Такие вопросы к @dd_bb, но его позиция это как раз то как сделано сейчас
 Alexey
Alexey
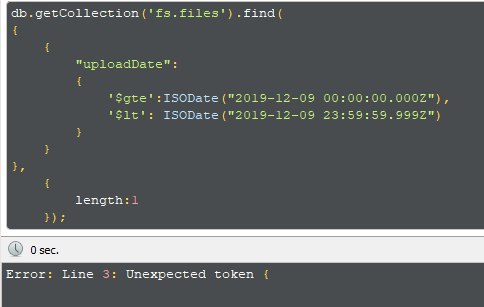 Nick
Nick
лишняя закрывающая скобка перед запятой