ну а так то, все мы были когда-то джунами и тупили над элементарными вещами. просто многие быстро об этом забывают :)
дык я не просто троллю я по-своему пытаюсь понудить матчасть почитать
 Mike
Mike


 yopp
yopp
Не туда извиняетесь ;)
 Сергей
Сергей
 Сергей
Сергей
 Dmitriy
Сергей
Dmitriy
Сергей
 Bohdan
Bohdan
 Max
Max
Привед. есть необходимость вырубить монгу в докере и поставить на хосте как сервис. если я просто покажу новой монге директорию от старой это будет работать?
Dmitriy
Daniil
Успішний Андрій
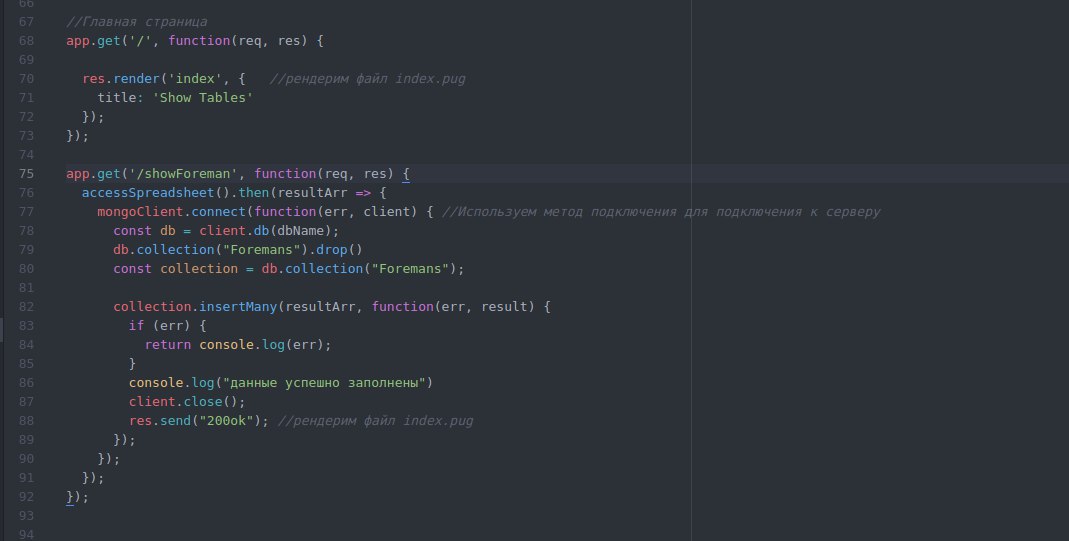
Почему когда я пытаюсь создать индекс для ttl chat.createIndex({ 'createdAt': 1 }, { expireAfterSeconds: 21600 }), я получаю ошибку nhandledPromiseRejectionWarning: MongoError: Index with name: createdAt_1 already exists with different options?
Почему если я прописываю chat.dropIndex('createdAt') перед попыткой создать этот индекс, я получаю ошибку MongoError: index not found with name [createdAt]?
 Suworow
Suworow
а что будет если спросить getIndexes()?
Suworow
(про то что оно пишет "createdAt_1 already exists", а не createdAt я пока молчу)
Успішний Андрій
а что будет если спросить getIndexes()?
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "mongochat.chats"
},
{
"v" : 2,
"key" : {
"expireAt" : 1
},
"name" : "expireAt_1",
"ns" : "mongochat.chats",
"expireAfterSeconds" : 20
},
{
"v" : 2,
"key" : {
"createdAt" : 1
},
"name" : "createdAt_1",
"ns" : "mongochat.chats",
"expireAfterSeconds" : 10
}
]
Dmitriy
Почему когда я пытаюсь создать индекс для ttl chat.createIndex({ 'createdAt': 1 }, { expireAfterSeconds: 21600 }), я получаю ошибку nhandledPromiseRejectionWarning: MongoError: Index with name: createdAt_1 already exists with different options?
Почему если я прописываю chat.dropIndex('createdAt') перед попыткой создать этот индекс, я получаю ошибку MongoError: index not found with name [createdAt]?
Имя индекса для удаления правильное пропишите, у вас и ошибка про это и в списке индексов это видно
Успішний Андрій
Имя индекса для удаления правильное пропишите, у вас и ошибка про это и в списке индексов это видно
А почему создался индекс с именем createdAt_1, если я создавал createdAt?
Suworow
А почему создался индекс с именем createdAt_1, если я создавал createdAt?
а где ты там имя индекса указал?
Сергей
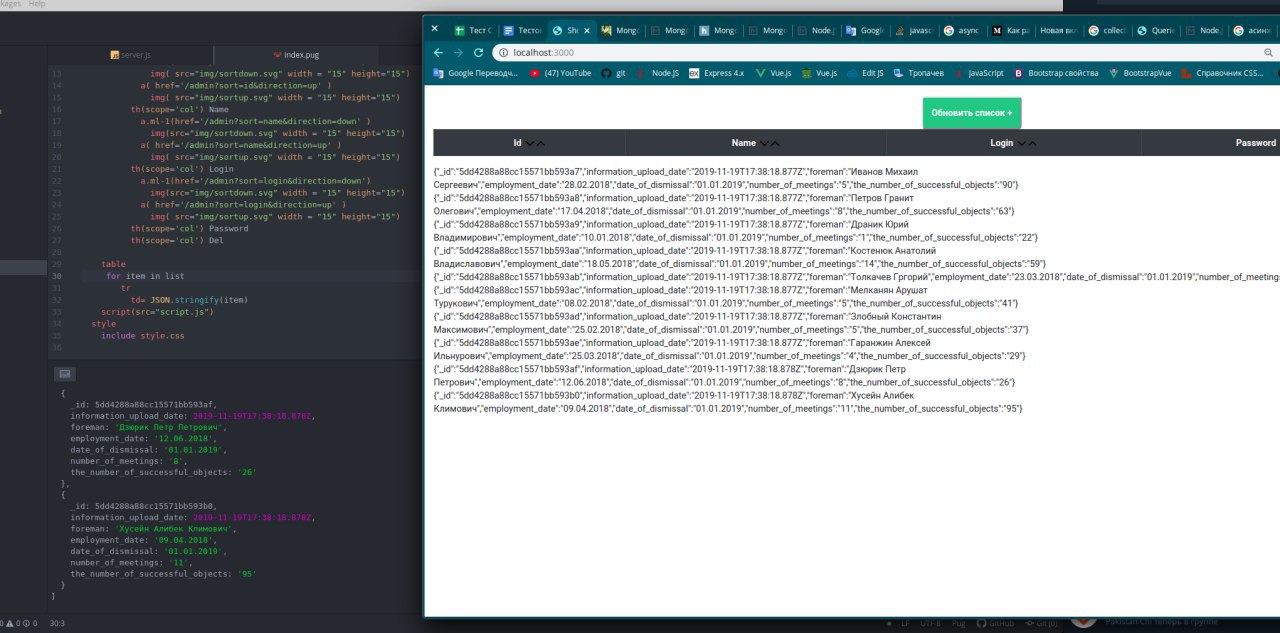
проблема с асинхроностью .find
Сергей
 Сергей
Сергей
 Сергей
Сергей
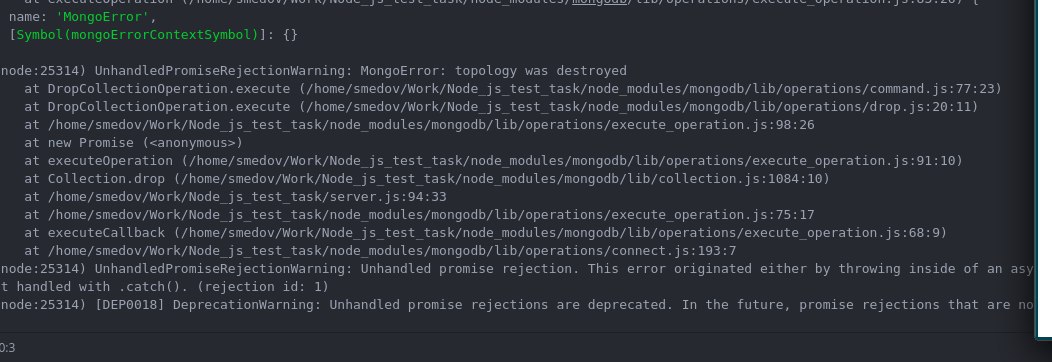
один раз загружается как нажимаю обновить ломается приложение
Сергей
а все
Сергей
удивлен но сам решил
Сергей
хорошо
 Ivan
Ivan
Спасибо =)
 Nick
Nick
Привед. есть необходимость вырубить монгу в докере и поставить на хосте как сервис. если я просто покажу новой монге директорию от старой это будет работать?
Да можно, если версии монги будут одинаковые. Но в любом случае перед экспериментом сделайте резервную копию
Max
Да можно, если версии монги будут одинаковые. Но в любом случае перед экспериментом сделайте резервную копию
Увы, после неуспешной настройки реплика сета нода перешла в состояние other, а теперь вообще не пускает в шелл. Там правда ещё router и mongod в режиме config srv. Каждый в своем докере. Все это очень хочется выключить и запустить mongod на хосте с нормальным конфигом.
Max
Может подскажете - состояние реплики пишется в базу или оно сессионное? Поможет ли рестарт контейнера вернуть mongod из other в primary?
Nick
Может подскажете - состояние реплики пишется в базу или оно сессионное? Поможет ли рестарт контейнера вернуть mongod из other в primary?
По репликасетам вменяемо ничего не подскажу. @dd_bb подскажи
Max
В таком состоянии уже несколько дней, через роутер нормально работает чтенте/запись, но попасть в шелл и подиагностить/переконфигурировать не удаётся.
Max
Mongodump тоже не коннектится.
yopp
Может подскажете - состояние реплики пишется в базу или оно сессионное? Поможет ли рестарт контейнера вернуть mongod из other в primary?
Состояние динамическое, зависит от настроек и текущей топологии. У вас реплика или шард?
Max
Состояние динамическое, зависит от настроек и текущей топологии. У вас реплика или шард?
На текущий момент 3 докер контейнера на первом хосте - mongod с данными, mongod config srv с "заделом" под будущий шард и mongos router. из мира доступен только mongos. Я недостаточно разобравшись, будучи в шелле mongod сделал rs.init и add mongod с другого хоста, но т.к. их было два, кворум не прошел и была ошибка недоступности или не корректного конфига реплики. в итоге первый mongod стал other, второй вроде тоже. попытка сделать его primary с force не удалась, добавление третьего в роли арбитра тоже. я сейчас не очень помню детали, завтра продолжу разбираться.
Max
такое вот legacy мне досталось)
yopp
Самый простой способ это перезапустить самую «свежую» ноду в stand-alone, сделать резервную копию admin базы и удалить ее. После чего настроить реплику по новой
yopp
Не используйте mongos и конфиг сервер в такой топологии, если у вас ноды не запущены в режиме shardsrv
Max
Не используйте mongos и конфиг сервер в такой топологии, если у вас ноды не запущены в режиме shardsrv
да не моё это творение, что вы. я на проекте 2 месяца, а это добро морочили 1,5 года назад.
yopp
Либо настраивайте сразу шард
Max
Самый простой способ это перезапустить самую «свежую» ноду в stand-alone, сделать резервную копию admin базы и удалить ее. После чего настроить реплику по новой
свежая нода? нода с данными одна. предпологал сделать окно на maintanance (в монге данные кабинета пользователей, надо вывешивать объявление заранее) и пробовать перезапуск. плюс хотел сразу убрать mongos & config srv, а дальше добавлять шард на новом хосте, реплицироваться туда и переключать на него мастер.
yopp
Вы писали что «их было два»
Max
Вы писали что «их было два»
да, второй Mongod это новый dedic, который я предпологал подключить репликой и бесшовно переехать, но ошибся в конфигурировании
yopp
Но не суть важно. Если нода одна, то перезапустить без replset, сделать дамп и удалить local базу (не admin, перепутал)
Max
т.к. нет опыта с монгой и нет актуального бэкапа ( до меня их вообще не делали), то разрабы несколько ссу** переживают и не дают с пинка перезагружать докеры, поэтому жду выделения окна и буду разбираться дальше
yopp
После чего реплику можно будет настроить по новой
yopp
Она клиентов сейчас не обслуживает, как я понимаю?
Max
Но не суть важно. Если нода одна, то перезапустить без replset, сделать дамп и удалить local базу (не admin, перепутал)
т.е. восстановить на новую ноду из бэкапа? mongodump не коннектит. надеюсь перезапуск докеров поможет, иначе только rsync, а в прошлый раз он вис на одном из файлов коллекций даже при остановленном Mongod
yopp
Если вы в неё можете и писать и читать, то mongodump должен работать. Потому что он просто тупо открывает курсор в каждую коллекцию и пишет на диск прочитанные документы
yopp
т.е. восстановить на новую ноду из бэкапа? mongodump не коннектит. надеюсь перезапуск докеров поможет, иначе только rsync, а в прошлый раз он вис на одном из файлов коллекций даже при остановленном Mongod
Нет, бэкап тут исключительно на случай если что-то пойдёт не так
yopp
Если удалить local базу, то сбросятся настройки репликации
yopp
А значит нода будте в non initialized state и вы сможете её корректно настроить
Max
Если вы в неё можете и писать и читать, то mongodump должен работать. Потому что он просто тупо открывает курсор в каждую коллекцию и пишет на диск прочитанные документы
возможно я его как-то не так запускал в спешке, но брал команду из хистори, должно быть аналогично прошлому запуску. завтра отпишу точнее, если вы готовы еще поотвечать на дурацкие вопросы)
Max
Если удалить local базу, то сбросятся настройки репликации
вот! это мне и нужно. хотя бы вернуть primary из other в primary, а то даже с force не даёт менять настройки. может и реплику сет соберу безболезненно
Max
Нет, бэкап тут исключительно на случай если что-то пойдёт не так
видимо после перезапуска и удаления локал базы
Max
А значит нода будте в non initialized state и вы сможете её корректно настроить
это мне и нужно, спасибо)
yopp
А что в случае с force происходит?
Max
А что в случае с force происходит?
чтоб я помнил) хотел заняться этим завтра днём, на свежую голову. первые пару месяцев, разгребаю конюшни, каждый день весело) возможно я просто не так её запускал, но он ругался на аргумент. хотя делал по ману.
Max
@dd_bb завтра в течении дня у вас будет время на ответы?
Max
окно то мне в любом случае раньше 21го не дадут, но хоть первичную инфу соберу и подиагностирую.
Max
@dd_bb в любом случае спасибо за ответы, становится понятнее куда копать дальше.
 D
D
Здрасьте. Скажите, а монга до сих пор кушает память размером с себя? Можно ли запустить базу (с примерно 50 тыщ рпм) размером 300 гигов, на машине с 64 гигами без боли? Я не работал с ней уже несколько лет, такого рода инфа плохо ищется.
 Светомеч
yopp
Светомеч
yopp
Здрасьте. Скажите, а монга до сих пор кушает память размером с себя? Можно ли запустить базу (с примерно 50 тыщ рпм) размером 300 гигов, на машине с 64 гигами без боли? Я не работал с ней уже несколько лет, такого рода инфа плохо ищется.
Если вы не используете MMAPv1, и не крутите ручку с размером Кеша в WiredTiger, то вероятнее всего размер используемой памяти стабилизируется на какой-то отметке.
Но кроме использования памяти под кэш для данных, есть ещё память которая используется для обработки запросов: буфферы курсоров, буфферы для сортировок и агрегаций, сетевые буфферы и т.д.
Размер этих структур никак не ограничивается, так как они являются критически важными для обработки запросов и реальное потребление памяти будет зависеть ещё и от вас, а именно от того какие именно запросы и в каких количествах у вас выполняются.
D
Если вы не используете MMAPv1, и не крутите ручку с размером Кеша в WiredTiger, то вероятнее всего размер используемой памяти стабилизируется на какой-то отметке.
Но кроме использования памяти под кэш для данных, есть ещё память которая используется для обработки запросов: буфферы курсоров, буфферы для сортировок и агрегаций, сетевые буфферы и т.д.
Размер этих структур никак не ограничивается, так как они являются критически важными для обработки запросов и реальное потребление памяти будет зависеть ещё и от вас, а именно от того какие именно запросы и в каких количествах у вас выполняются.
спасибо за ответ, но я до сих пор не уверен, видимо придется делать тестовую систему с ботами
yopp
Вторая часть обычно имеет существенно меньший эффект, чем размера кэша для данных. Но если у вас есть какие-то тяжелые запросы с точки зрения memory complexity, например большие сортировки (по-моему до 32мб на курсор) или тяжёлые агрегации (до 100мб на пайплайн), то очевидно что 1000 параллельных запросов будут требовать значительного объёма памяти
D
частые запросы не агрегатные, агрегатные с огромными сортировками тоже есть, но редкие.
yopp
Я сомневаюсь что я сможете ботами получить какую-то близкую к реальности картину
D
монга умеет работать с коллекцией не загружая ее в память целиком?
yopp
Самый простой способ это записать реальный флоу с системы и проиграть его на тестовом столе, так как реальное потребление будет в первую очередь от распределения запросов во времени
yopp
Не понимаю ваш вопрос
D
в ранних версиях ей это вроде бы требовалось, от того она и жрала жадно память
yopp
Всё равно не понимаю ваш вопрос :)
D
ну она не могла сделать скан по коллекции или поиск по индексу, если они не загружены в оперативку
D
то есть по диску, частями, с временными файлами, как это делает постгрес
yopp
В любом хранилище данные с диска не возможно прочитать мимо памяти
yopp
Просто потому что так устроена вычислительная архитектура