 Anonymous
Anonymous


https://www.mongodb.com/blog/post/making-the-most-of-monitoring-mongodb
Anonymous
https://www.mongodb.com/blog/post/making-the-most-of-monitoring-mongodb
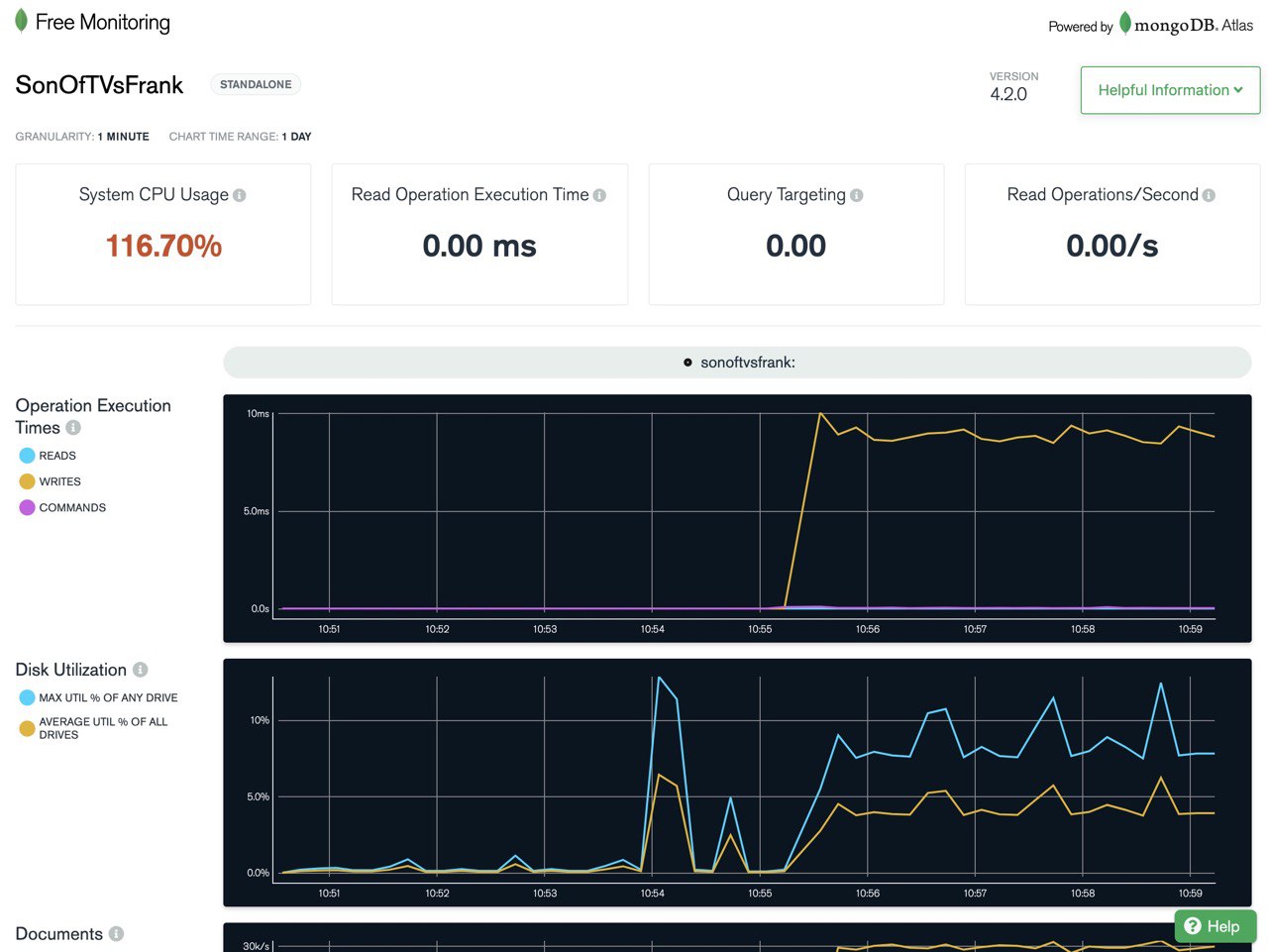
вот здесь у чувака 166.70% как так?
Anonymous
 Andrey
Andrey
в приложении readConcern для транзакций выставлен в majority, а в логах БД пишет что snapshot, индивидуально для команд - по дефолту, вопрос по какой логике и кто перезаписывает настройки?
код приложения используется mongo-go-driver 1.1.2:
go func(op func(mongo.SessionContext) error) {
session, err: = m.db.Client().StartSession()
if err != nil {
log.Println(err)
return
}
ctx, cancel: = context.WithTimeout(context.Background(), 10 * time.Second)
defer cancel()
err = mongo.WithSession(ctx, session, func(sessionCtx mongo.SessionContext) error {
sessionCtx.StartTransaction(
options.Transaction().SetReadConcern(readconcern.Majority()).SetWriteConcern(writeconcern.New(writeconcern.WMajority())),
)
err: = op(sessionCtx)
if err != nil {
return err
}
return session.CommitTransaction(sessionCtx)
})
if err != nil {
log.Println("ERROR COMMIT TRANSACTION")
}
session.EndSession(ctx)
}(op)
лог бд (4.2.1)
2019-11-08T15:46:26.987+0000 I TXN [conn24] transaction parameters:{ lsid: { id: UUID("3d28064e-5269-49d9-8185-d8ca909950aa"), uid: BinData(0, 830872FC3F605AFFB6F640ED87DB86D55DCD03BE1E29155D54CDA151B743588A) }, txnNumber: 7, autocommit: false, readConcern: { level: "snapshot" } }, readTimestamp:Timestamp(0, 0), keysExamined:83 docsExamined:87 terminationCause:committed timeActiveMicros:4958 timeInactiveMicros:213710 numYields:0 locks:{ ReplicationStateTransition: { acquireCount: { w: 2 } }, Global: { acquireCount: { w: 1 } }, Database: { acquireCount: { w: 1 } }, Collection: { acquireCount: { w: 3 } }, Mutex: { acquireCount: { r: 3 } } } storage:{} wasPrepared:0, 218ms
 Nick
Nick
вечерние приветики
поставил монгу (> 4 версия)
несколько CPU
не могу понять по статистике
system cpu usage - 190%
как так?
я из чатика по девопса
предположим что может 190% - это загрузка по нескольким cpu, но как тогда? у меня 3 cpu к примеру
как расчет тогда ведется?
Если данная метрика снимается стандартными линуксовыми методами то оно считает утилизацию.одного ядра за 100%, соответственно 2 ядра загруженные в полку выдадут 200%. Как и почему так не знаю, но стандартный top и ps работают так
Nick
Ну я пока пришел к такому решению:
{
"_id":"5dc5b135f0ffa627dc24ac8d",
"properties": [
{
"numeric_id":"210",
"title":"Serial number of the application",
"value":"0119852150592"
},
{
"numeric_id":"220",
"title":"Date of filing of the application",
"value":"2019-12-17"
}
]
}
Для начала хорошо, пара замечаний, если вы говорите что нумерик ид то тип далжен быть числом, а не строкой. Так же совету добавить поле type, чтобы при необходимости знать в какой программный тип нужно кастануть значение. И третье погуглите хранение пропертей в монге, думаю чтото для себя подчерпнете. И сразу изучите операторы в монге для работы с массивами, они вам поеадобятс
El
Приветствую.
В БД лежит массив объектов вида
{
"name": "002134e1-267c-418a-9e0f-4b5ee7fc111c",
"timestamp": 1567296480,
"price": 100
}
timestamp не уникальны, на каждый приходится несколько price. Нужно отправить в Монгу запрос с массивом значений timestamp и вернуть ответ с массивом объектов вида
{
"timestamp": ... ,
"prices": ...
}
, где timestamp это каждый индивидуальный timestamp и prices это сумма значений price для каждого timestamp.
Как?
 yopp
yopp
Load Average это размер очереди операций. Больше 100% это нормально, значит что очередь операций размером больше чем может выполнить одно ядро
https://scoutapm.com/blog/understanding-load-averages
yopp
Ты сам себе злобный буратино
В нашей группе такое отношение неприемлемо. Read-only на неделю, в следующий раз бан.
yopp
Ну я пока пришел к такому решению:
{
"_id":"5dc5b135f0ffa627dc24ac8d",
"properties": [
{
"numeric_id":"210",
"title":"Serial number of the application",
"value":"0119852150592"
},
{
"numeric_id":"220",
"title":"Date of filing of the application",
"value":"2019-12-17"
}
]
}
Зависит от того, как часто меняется title и как вы по нему хотите искать.
На мой взгляд проще вынести атрибуты в отдельную коллекцию и в массиве хранить только id атрибута и его значение.
Если нужно искать по названию атрибута, то сначала сделать запрос в коллекцию с атрибутами, а потом уже отфильтровать коллекцию со значениями по найденным id атрибутов
Artemy
Зависит от того, как часто меняется title и как вы по нему хотите искать.
На мой взгляд проще вынести атрибуты в отдельную коллекцию и в массиве хранить только id атрибута и его значение.
Если нужно искать по названию атрибута, то сначала сделать запрос в коллекцию с атрибутами, а потом уже отфильтровать коллекцию со значениями по найденным id атрибутов
Ну да, тоже интересный вариант, спасибо
yopp
Скорее всего атрибутов будет на порядки меньше чем значений, а значит поиск будет требовать меньше ресурсов
El
AF
$match c $in
$group по $price с $sum
Попробовал так:
const entries = await Subscription
.aggregate([
{ $match: { timestamp: { $in: req.body.timestamps } } },
{ $group: { _id: timestamp, sum: { $sum: "$price" } } },
{ $project: {
_id: true,
sum: true
}},
{ $limit: parseInt(req.params.limit, 10) }
])
res.status(200).json({ entries });
В Rested вижу бесконечный спиннер.
Подаю, помимо логина и пароля юзера, массив timestamps вида [1567296480, 1567296600].
yopp
$limit какую цель тут имеет?
yopp
И сколько у вас записей в коллекции?
El
В коллекции около 300 записей. $limit для ограничения размера отдаваемого массива.
yopp
Сам пайплайн выглядит корректно, скорее всего проблемы с промисом или во что там это завёрнуто
El
Там голый запрос на беке.
Промежуточный фикс:
const entries = await Subscription
.aggregate([
{ $match: { timestamp: { $in: req.body.timestamps } } },
{ $group: { _id: "$timestamp", sum: { $sum: "$price" } } },
{ $project: {
_id: false,
sum: true
}},
{ $limit: parseInt(req.params.limit, 10) }
])
res.status(200).json({ entries });
В сравнении с предыдущим запросом изменён $group: { _id: "$timestamp", ... .
Получаю массив вида
"entries": [
{
"sum": 173400
},
{
"sum": 167400
}
]
Теперь в каждый объект нужно добавить timestamp, для которого подсчитано поле sum.
El
Похоже, готово. в $project поменял _id на true, получаю
"entries": [
{
"_id": 1567296600,
"sum": 173400
},
{
"_id": 1567296480,
"sum": 167400
}
]
Спасибо за содействие.
El
Интересно, как теперь в ответе вместо _id видеть timestamp.
El
Решение:
{ $project: {
_id: false,
sum: true,
"timestamp": "$_id"
}},
Найдено в https://stackoverflow.com/a/49402236.
 Josh
Josh
https://docs.mongodb.com/manual/reference/operator/update/setOnInsert/
не получается, для массивов дичь выходит
Josh
 Josh
Josh
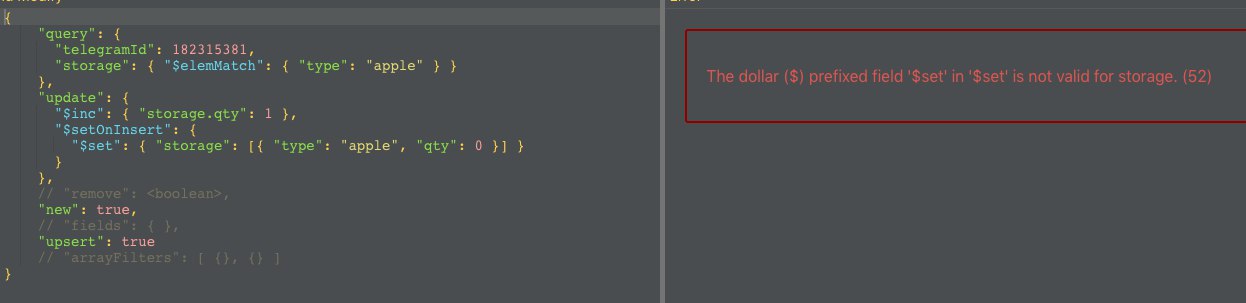
storage.$.qty нельзя при инсерте, крч в итоге плодит новые записи так при апсерте
yopp
storage.$.qty нельзя при инсерте, крч в итоге плодит новые записи так при апсерте
Откуда storage.$.qty?
yopp
Запрос покажите пожалуйста
Josh
yopp
Слился с фоном)
Josh
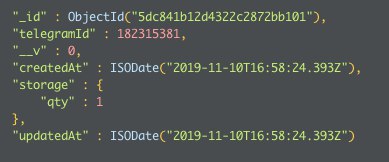
если в корзине нет предмета определенного типа, то вставлять, в одной операции пытаюсь сделать, чет примеры всюду с коллекциями, не с массивами, аналога не найду
yopp
А AF pipeline с upsert работает?
Josh
 Josh
Josh
как бы вставку сделать, чтобы отрабатывала до инкремента
Josh
а то он storage.qty потому и создает, я уж элемматч в квери сделал, потому что без него еще и storage.type добавлялось, но также не в массив
yopp
Не очень понимаю вашу схему
yopp
У вас корзина это один документ в котором массив документов товаров?
Josh
У вас корзина это один документ в котором массив документов товаров?
да
UserSchema
userId: Number,
...
storage: [ItemSchema]
ItemSchema
type: String,
qty: Number
yopp
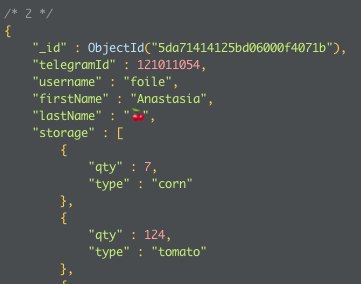
Тогда почему на картинке у вас там не массив?
Josh
это не корзина по-сути а инвентарь, количество предметов очень мало и конечно проще было бы сделать вообще все тупо полями с 0
Josh
Тогда почему на картинке у вас там не массив?
потому что неправильно отрабатывает, в том и прикол
Josh
 yopp
yopp
Вместо push сделайте set с массивом из одного документа
Josh
Вместо push сделайте set с массивом из одного документа
так пуш будет отрабатываться же после инк
yopp
Попробуйте
Josh
 yopp
yopp
Я не понимаю как это все относиться к вашему случаю
yopp
У вас это 10 секунд займёт
yopp
А я в метро
Josh
Я не понимаю как это все относиться к вашему случаю
ну там пример на setOnInsert и сказано, что сначала апсерт отработает, потом основная операция и только потом setOnInsert
Josh
Вместо push сделайте set с массивом из одного документа
попробовал, все в точности также, ну потому что апсерт отработал и сделал новый документ
yopp
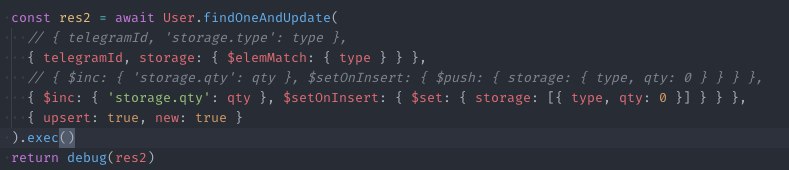
Покажите? А ещё лучше на play.db-ai.co бросьте
Josh
 yopp
yopp
А, вижу. У вас проблема с $elemMatch в условии.
yopp
Я пропустил этот момент. Попробуйте на AF pipeline и вместо $elemMatch делайте внутри пайплайна проверку
yopp
Чтоб у вас в условии остался только telegramId
yopp
Это какая-то старая история. Первым же вообще создаются поля из условия и там какая-то дичь с $elemMatch
yopp
По этому и документ получается, а не массив
Josh
Это какая-то старая история. Первым же вообще создаются поля из условия и там какая-то дичь с $elemMatch
именно для этого я доку и кинул, что сначала апсерт отработает и новый док сделает
yopp
Смысл я так понял чтоб на один telegramId был один документ, так?
Josh
а как внутри пайпа то проверить
yopp
Тогда необходимо чтоб в условии был только он
Josh
 Josh
Josh
Тогда необходимо чтоб в условии был только он
это да, я понял мысль, только как проверку внутри сделать не допер
Josh
https://play.db-ai.co/m/XchJemjklgABiNab
 Сергей
Сергей
 Josh
Josh
+
yopp
bcrypt scrypt
yopp
Ищите современный устойчивый к gpu алгоритм хеширования паролей
yopp
Там в документации будет все
yopp
Там и соль и ресурсная стоимость настаиваться
Сергей
А вот эта тема с express sessions актуальна для авторизации?