 yopp
yopp


вам нужен count
 Anonymous
Anonymous
вам нужен count
const entries = await Subscription
.find({ timestamp: req.params.timestamp })
.count();
Спасибо.
yopp
вам стоит добавить по timestamp индекс
Anonymous
В этом запросе интересно количество записей для каждого timestamp.
 Ilya
Ilya
Господа, а в монге есть что-то вроде асинхронного запроса на чтение?
Ilya
Мне надо разок выполнить тяжёлый запрос с агрегацией, а у меня на 18М записей никак не укладывается в 10 минут
yopp
а почему 10 минут?
yopp
https://jira.mongodb.org/browse/SERVER-8188
ого
yopp
> db.runCommand({getParameter:1, cursorTimeoutMillis: 1})
{ "cursorTimeoutMillis" : NumberLong(600000), "ok" : 1 }
yopp
уот это да
yopp
а, нет, не щастье "for idle cursors»
yopp
от find({}) по шардированной коллекци не спасёт
yopp
Ilya
Просто будет долго долго висеть, пока не отдаст?
yopp
да
yopp
A value of 0 explicitly specifies the default unbounded behavior.
Ilya
Спасибо
Ilya
а почему 10 минут?
Пытаюсь выбрать записи, у которых строки в массиве дублируются, делаю это через агрегацию
Ilya
Мб быстрее можно, но я не нашел как
yopp
я невнятно задал вопрос, почему именно в 10 минут, но уже кажется нашёл ответ :)
Ilya
я невнятно задал вопрос, почему именно в 10 минут, но уже кажется нашёл ответ :)
Это я по возрастающей таймаут в роботе увеличиваю, пока до 10 минут дошел)
yopp
а, так отключите таймаут вообще
yopp
один раз так сделать – нормально :)
Ilya
Попробую, спс
 Alexey
Alexey
Привет, народ) Помогите, с запросом:
пытаюсь в коллекции config.chunks посчитать jumbo чанки. Делаю так:
db.chunks.aggregate(
[
{
"$group" :
{
_id : { collection: "$ns", shard: "$shard"},
chunks:{$sum:1},
jumbo:{$sum: "$jumbo"},
}
},
],
{
cursor: { batchSize: 0 }
}
)
На выходе ......"jumbo" : 0......
хотя они точно есть. Что я делаю не так?
 Daria
Daria
ок
Ilya
Господа, нид хэлп, так сказать
Что-то у меня вот такой запрос уже полчаса висит, где можно оптимизировать?
db.getCollection('candidate').aggregate([
{"$project": {"account.skillorder":1}},
{"$unwind":"$account.skillorder"},
{"$group": {"_id":{"_id":"$_id", "cid":"$account.skillorder"}, "count":{"$sum":1}}},
{"$match": {"count":{"$gt":1}}},
{"$group": {"_id":"$_id._id", "tags":{"$push":"$_id.cid"}, "count":{"$sum":1}}}
]).maxTimeMS(0)
Ilya
Идея в том, что есть массив account.skillorder, состоящий из строк, и у некоторых сущностей могут быть дубликаты в этом массиве
Я хочу найти все записи, у которых есть дубликаты (первый group) и вывести их в виде {_id, массив ключей-дубликатов} (второй group)
Ilya
На трех записях это очень хорошо отрабатывает
Ilya
А вот на 18М записей - похуже
Ilya
Я постоянно это выполнять не буду, мне только один раз нужно найти эти записи
Ilya
Поэтому не очень чуствителен к скорости, но 30 минут это явно дофига
Ilya
Хмм, отвалился через 55 минут с пустой ошибкой 🙁
Ilya
А можно как-то без агрегаций найти записи с дубликатами в массиве?
 Sardor
Sardor
Попробуй с флажком allowDiskUse : true
Sardor
частично будет записывать на диск чтоб память не нагружать
Sardor
Во время выполнения pipeline stages
Dmitry
Ребят, есть задача хранить записи в mongoDB atlas в зашифрованном виде,
то есть документ будет вида
{login: hashedLogin…,
password: hashedPassword
}
В какую сторону смотреть? Я так понимаю дешифровка перед отправкой клиенту тоже должна быть реализована на стороне сервера??
Ilya
Ребят, есть задача хранить записи в mongoDB atlas в зашифрованном виде,
то есть документ будет вида
{login: hashedLogin…,
password: hashedPassword
}
В какую сторону смотреть? Я так понимаю дешифровка перед отправкой клиенту тоже должна быть реализована на стороне сервера??
Обычно это на стороне приложения делается
Ilya
То есть не в бд
Ilya
А просто в приложении шифруешь - дешифруешь
Ilya
Хорошо. Можешь подсказать в сторону каких инструментов смотреть?
Обычно в каждом ЯП есть стандартные либы для криптографии. Их и юзай
Dmitry
Обычно в каждом ЯП есть стандартные либы для криптографии. Их и юзай
 Dmitry
Dmitry
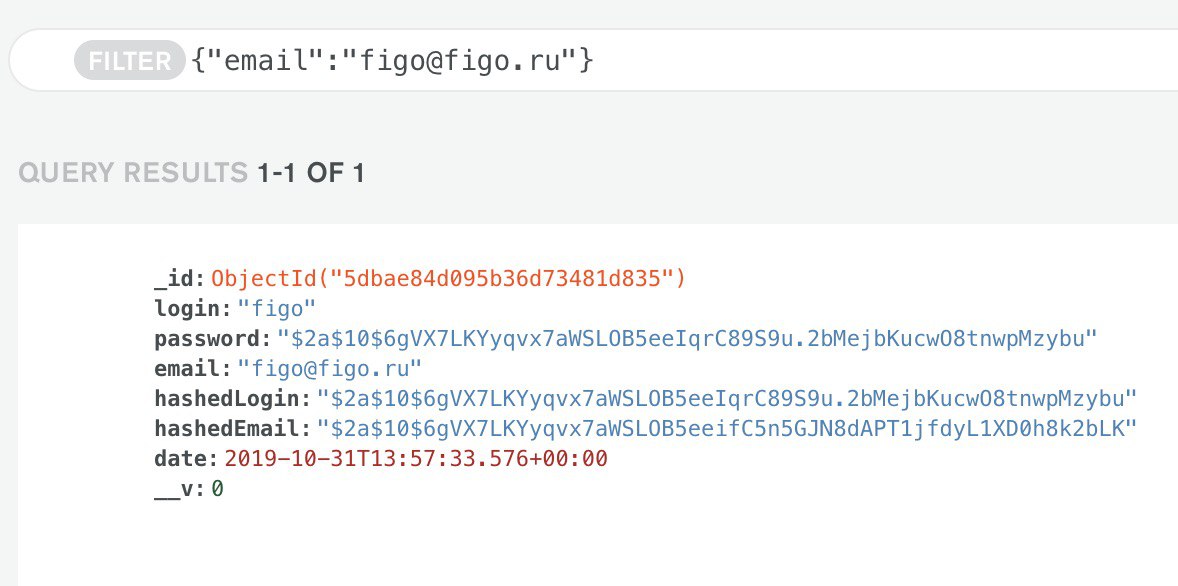
Как я себе это представляю - должны быть в базе одни хеши - разве нет?
 stay
stay
stay
stay
В чем проблема хешировать перед отправкой в БД ?
Ilya
Как я себе это представляю - должны быть в базе одни хеши - разве нет?
Будешь класть в базу хеши - будут лежать хеши
Dmitry
В чем проблема хешировать перед отправкой в БД ?
Проблем нет, я не пойму в итоге я делаю правильно или ты говоришь делать на клиенте?
stay
Ну хешировать на клиенте это не особо имеет смысл, как я понимаю
stay
Тебе пытаются сказать, что хешировать надо на сервере, но не средствами базы данных
Dmitry
Тебе пытаются сказать, что хешировать надо на сервере, но не средствами базы данных
ааа, ну значит я не так выразился, я хеширую NodeJS (bcrypt)
stay
Ну и нормально, не важно какой либой хешировать, главное надежно хранить ключи
Ilya
Если это пара пользовательских логин:пароль, то пароль нужно одностороним шифрованием шифровать
Ilya
Чтобы из дампа нельзя было пароль восстановить
Ilya
Емейл достаточно двусторонним шифровать, чтобы в чистом виде не лежал
Dmitry
Мне пока сделать нужно максимально быстро и просто, у меня куча коллекций/документов, нужно все шифровать, вплоть до возраста :’(
Dmitry
Не могу найти в bcryptjs как дешифровываать… bcrypt похоже умеет только делать сравнение введенного пользователем пароля и зашифрованного, а дешифровывать не умеет
Ilya
Господа, нид хэлп, так сказать
Что-то у меня вот такой запрос уже полчаса висит, где можно оптимизировать?
db.getCollection('candidate').aggregate([
{"$project": {"account.skillorder":1}},
{"$unwind":"$account.skillorder"},
{"$group": {"_id":{"_id":"$_id", "cid":"$account.skillorder"}, "count":{"$sum":1}}},
{"$match": {"count":{"$gt":1}}},
{"$group": {"_id":"$_id._id", "tags":{"$push":"$_id.cid"}, "count":{"$sum":1}}}
]).maxTimeMS(0)
Гайс, а как можно сделать, чтобы агрегация применялась только к записям, у которых поле account не null?
stay
Не могу найти в bcryptjs как дешифровываать… bcrypt похоже умеет только делать сравнение введенного пользователем пароля и зашифрованного, а дешифровывать не умеет
Есть огромная разница между хешированием и шифрованием
 Maksim
Maksim
Хеш нельзя расхэшировать
stay
туплю.. А в чем разница?
Если коротко, то функция хеширования невозвратная
А Шифрование предполагает преобразование а обе стороны
 Alexander
Dmitry
Maksim
Alexander
Dmitry
Maksim
А зачем вообще пароли расшифровывать?
Ilya
Пароли не нужно
yopp
хеши не должны быть
yopp
зависит от того что вы хотите
yopp
в 4.2 появился field level encryption
yopp
но с ним есть проблема: вы лишаетесь поиска по этим полям
yopp
в первую очередь вам необходимо понять от кого вы защищаетесь, почему, на какой срок, сколько вы готовы на это потратить и чем вы готовы пожертвовать
yopp
и тут есть две проблема:
1) скорее всего вы не сможете корректно реализовать ту схему, которая будет подходить под ваши требования
2) на рынке будет полтора специалиста, которые смогут
yopp
ну и конечно стоить это будет как боинг