 Anonymous
Anonymous


поле tags (массив) состоит из айдишников из коллекции tags. хочу его заполнить
Anonymous
когда делаю findOne
Anonymous
ну так выше использовал
Anonymous
и написал про синтаксис
 Nick
Nick
а что не так?
Semeon
Переформулирую свой вопрос. Допустим, я нашёл документ по какому-нибудь полю. Могу ли я опираясь на это поле получить другие поля из этого документа?
 Mike
Mike
sort(Temoerature.Maximum).limit(1) не?
Jack 🎲
Всем привет!
Подскажите пожалуйста, как выделить записи за сутки?
дату записываю в timestamp
Уже на тостере вопросом задавался, гуглил. Никак не могу запрос составить
Сейчас осилил только общую сумму по колонке собрать:
db.logs.aggregate([{"$group": {"_id": "$uid", "total": {"$sum": "$count"}}}])
а нужно за N времени)
 RapidCodeLab
RapidCodeLab
$gt и $lt
RapidCodeLab
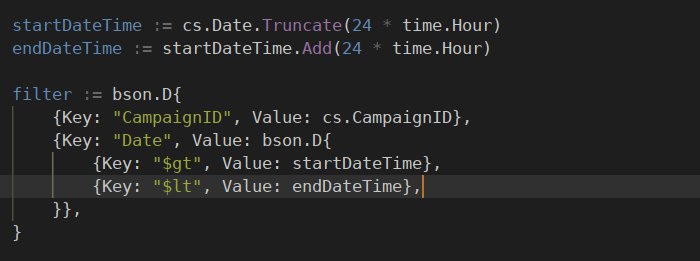 Daniil
Daniil
да, это я нашел. но я не могу никак рабочий запрос составить 🙁 вообще в край туплю
просто два элемента будет в aggregation pipeline:
1) $match по нужному вам полю с операторами $gt и $lt
2) $group с суммированием нужных вам значений
Jack 🎲
{ $match: { date: {$gte: timestamp сутки назад ,$lte: текущий timestamp} } }
правильно?
Daniil
ну это за последние 24 часа
Если речь идет о календарных днях, то таймстемп начала суток и таймстемп конца суток
Daniil
а так в целом все верно
Jack 🎲
спасибо большое)
Jack 🎲
ну это за последние 24 часа
Если речь идет о календарных днях, то таймстемп начала суток и таймстемп конца суток
разобрался наконец-то в логике составления запросов) больше тупил т.к. не понимал логику
 yopp
yopp
Дополню свой пример наглядно:
{
"LastUpdate": 1571438855,
"Temperature": {
"Minimum": 25.4,
"Maximum": 30.1,
"Average": 27.3
},
"Pressure": {
"Minimum": 748.6,
"Maximum": 749.4,
"Average": 749
}
}
Хочется по значениям Minimum и Maximum полчить получить timestamp из того же объекта. Это возможно?
Вы хотите найти «LastUpdated» у документа, у которого самый широкий диапазон min/max?
Semeon
Вы хотите найти «LastUpdated» у документа, у которого самый широкий диапазон min/max?
Я хочу найти timestamp документа у Minimum и Maximum. Это возможно?
Anonymous
Доброго времени, чтобы ускорить поиск мне порекомендовали использовать индексы, где можно про них прочитать на русском
Anonymous
Или кто нибудь объясните как индексировать, пожалуйста
yopp
Я хочу найти timestamp документа у Minimum и Maximum. Это возможно?
Документ это та структура, которую вы предоставили. Вы хотите найти документ с минимальным значением minimum среди других таких документов?
Или вы показали документ из AF пайплайна, после $group?
Semeon
Документ это та структура, которую вы предоставили. Вы хотите найти документ с минимальным значением minimum среди других таких документов?
Или вы показали документ из AF пайплайна, после $group?
[
{ $match:
{
Date: { $lt: time.setCurrentOrRange(), $gte: time.setCurrentOrRange(ms) }
}
},
{ $group:
{
_id: null,
LastUpdate : { $max: "$Date" },
minTemperature: { $min: "$Temperature" },
maxTemperature: { $max: "$Temperature" },
avgTemperature: { $avg: "$Temperature" },
minPressure: { $min: "$Pressure" },
maxPressure: { $max: "$Pressure" },
avgPressure: { $avg: "$Pressure" },
}
},
{ $project:
{
_id: null,
LastUpdate : 1,
Temperature: {
Min: ["$minTemperature", "$LastUpdate"],
Max: ["$maxTemperature", "$LastUpdate"],
Avg: { $round: ["$avgTemperature", 1] }
},
Pressure: {
Min: ["$minPressure", "$LastUpdate"],
Max: ["$maxPressure", "$LastUpdate"],
Avg: { $round: ["$avgPressure", 1] }
},
}
},
{ $project:
{
_id: 0,
Date: 0,
City: 0,
Street: 0
}
}
]};
У меня есть такая агрегация. Здесь я нахожу минимальные, максимальные и средние значения по полям. Хочется по минимальным и максимальным значениям ещё получать timestamp из того же документа, чтобы знать в какой момент времени было минимальное или максимальное значение. Я не понимаю, можно ли это сделать? )
yopp
Впрочем, можно попробовать $cond в $min
yopp
А, стоп. Дата же
Semeon
У меня timestamp не как дата, а как число
yopp
Да не важно
yopp
$cond поможет вернуть timestamp из документа?
Мне с ходу ее приходит в голову ни условие, ни в каком из операторов в $group можно использовать $cond
 critskiy
critskiy
Есть очень тупой вопрос, связанный с процессом репликации. Репликация просиходит через initial sync, но процесс сам постоянно падает с ошибкой ‘failed to clone 2 collections’; не помог даже перезапуск реплики. Придется лезть в oplog?
Semeon
Мне с ходу ее приходит в голову ни условие, ни в каком из операторов в $group можно использовать $cond
Вот я вчера до ночи пытался понять, как можно вернуть поле из найденого документа опираясь на другое поле.
yopp
$cond поможет вернуть timestamp из документа?
Может быть $max по maxTempTime, где $cond по $$CURRENT.Temperature и $maxTemperature
yopp
Т.е. если температура больше чем в $maxTemperature, то скорее всего она поменялась, значит в $max надо вставить текущую дату. Если не поменялась вставить 0
yopp
Тогда $max для $maxTempTime будет обновлять дату, только если условия истинное
Semeon
А я могу вернутья ObjectID, если нашёл минимальное или максимальное значение?
yopp
Но я не уверен что $maxTemperature будет правильный
yopp
А я могу вернутья ObjectID, если нашёл минимальное или максимальное значение?
Мне кажется вам нужно поменять схему
yopp
Она для ваших задач не подходит
yopp
Во-первых хранить такие значения в одном документе это очень дорого. Во вторых смешивать два разных показателя в одном документе, как видите, вызывает проблемы.
Агрегировать будет сложно, по большим диапазонам.
Я бы использовал бакеты: группировал значения одного параметра в одних документ, например по паре сотен. Если у вас даты значений строго возрастают и никогда не бывает значения из прошлого, это очень просто сделать сразу по дате
Обновление max/min/avg будут при вставке в бакет (avg как sum / count), там-же можно обновлять дату $min/$max
Anonymous
Или кто нибудь объясните как индексировать, пожалуйста
db.users.createIndex({"name" : 1})
yopp
Бакеты вам позволят решить вашу проблему одним запросом по индексу :)
Anonymous
Бакеты вам позволят решить вашу проблему одним запросом по индексу :)
Не понял вас, подробнее объясните пожалуйста
 stay
stay
Ребтя, подскажите, пожалуйста, как правильно настроить TTL в схемах mongoose, а то я в конец запутался где timestamps где индексы и где писать expires
yopp
Не понял вас, подробнее объясните пожалуйста
Индекс это как картотека в библиотеке. Представьте что книги это документы. Книги в библиотеке стоят в каком-то случайном порядке.
Если у вас нет индекса, чтоб найти все книги Стивена Кинга, вам нужно просмотреть абсолютно книги в библиотеке.
Если вы один раз пройдётесь по всем книгам и составите картотеку, где на каждого автора заведёте по карточке, а в карточке укажете на какой полке стоит книга, то чтоб найти все книги Стивена Кинга, вам надо будет найти Стивена Кинга в картотеке и дальше уже пойти за книгами на те полки, которые указаны в карточке.
Если не сортировать карточки в картотеке, то чтоб найти карточку Стивена Кинга, надо будет в худшем случае перебрать все карточки, что опять-же не очень эффективно. А вот если их упорядочить по алфавиту, то вам будет гораздо проще.
По этому у индекса всегда есть порядок. И вы можете выбрать, как сортировать: по увеличению или по уменьшению значений.
yopp
Сортировка помогает получать значения из индекса в каком-то порядке. Например с датами. Например вы ищите всех записи на конкретный день. По полю с датоц есть индекс и значения в индексе упорядочены по убыванию. Если вы в запросе укажете что вам нужны данные в таком-же порядке, то базе данных не надо будет дополнительно сортировать данные, так ка кони уже упорядочены в индексе.
Anonymous
Можете помочь в конкретном случае, есть коллекция пользователей и тг бот, при каждом получении сообщения отправляется запрос в БД, как использовать индексы в Python
critskiy
Есть очень тупой вопрос, связанный с процессом репликации. Репликация просиходит через initial sync, но процесс сам постоянно падает с ошибкой ‘failed to clone 2 collections’; не помог даже перезапуск реплики. Придется лезть в oplog?
в общем, можно ли найти 2 поврежденные коллекции через oplog или как действовать теперь?
yopp
yopp
на ноде на которую реплицируется, в логах, должна быть информация что пошло не так
critskiy
как раз collection failed
yopp
посмотрите весь лог
yopp
у вас окно репликации достаточное?
Anonymous
Как делается find_one + indexing??
yopp
вы сначала создаёте индекс по полю, которое позволяет максимально точно найти документ в коллекции, а потом просто в find указываете условие по этому полю
Anonymous
вы сначала создаёте индекс по полю, которое позволяет максимально точно найти документ в коллекции, а потом просто в find указываете условие по этому полю
Пример приведите для Python, пожалууууйста..
critskiy
у вас окно репликации достаточное?
по хардам? или по настройкам реплики? По хардам железо ОК, по настройкам replica member только buildIndexes false
Daniil
Ребтя, подскажите, пожалуйста, как правильно настроить TTL в схемах mongoose, а то я в конец запутался где timestamps где индексы и где писать expires
Вы имеете ввиду TTL-индекс в монге? В mongoose достаточно сделать как тут в примере - https://mongoosejs.com/docs/api.html#schematype_SchemaType-index
Но я рекомендую ничего не индексировать с помощью mongoose, а добавлять индексы вручную через шелл.
stay
critskiy
по хардам? или по настройкам реплики? По хардам железо ОК, по настройкам replica member только buildIndexes false
крч нашлось по логам две таблицы
Daniil
А почему именно через шел?
Ну не через шелл, через любой инструмент для взаимодействия с базой. Главное чтобы это осуществлялось вручную
stay
Ну не через шелл, через любой инструмент для взаимодействия с базой. Главное чтобы это осуществлялось вручную
А какой в этом смысл? Почему не там же, где описываются модели?
Daniil
Для спокойствия и уверенности)
 antofa
antofa
Всем привет. Кто может подсказать, что это за логи идут постоянно и как их убрать (на прошлых выходных закончилось место на диске из-за них)? http://dpaste.com/3WYKFR2
yopp
по хардам? или по настройкам реплики? По хардам железо ОК, по настройкам replica member только buildIndexes false
нет, я имею ввиду
The difference between the primary’s replication oplog window and the secondary’s replication lag meets your specified threshold. A secondary can go into RECOVERING if this value goes to 0.
yopp
что у вас размер оплога позволяет secondary завершить репликацию
critskiy
yopp
👍
Semeon
yopp
я не про $bucket, а про паттерн bucket
yopp
{_id: OID, attribute: Attribute_OID, time_from: 1, time_to: 2, count: 2, values: [{t: 1, _v: 12.0}, {t: 2, _v: 33.44} …], min: 12.0, min_t: 1 …}
…