 Anonymous
Anonymous


и незнаю куда рыть
Anonymous
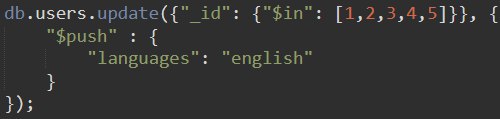
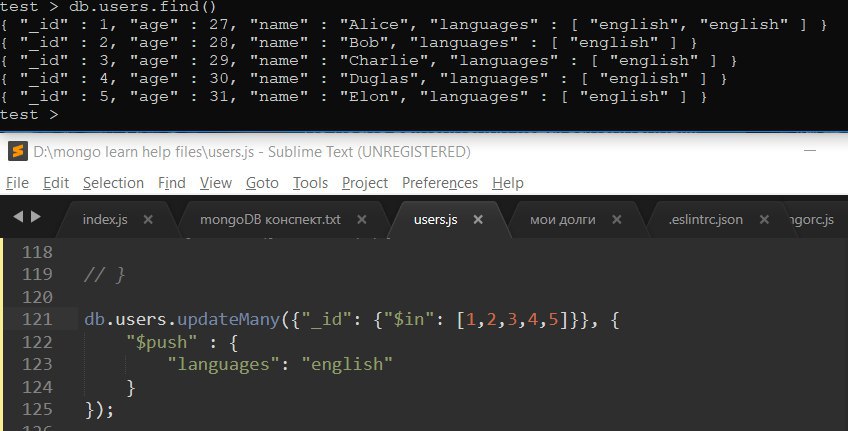
updateMany и update с multi: true это одно и тоже?
Daniil
Второе типа deprecated
Anonymous
благодарю
Anonymous
вроде нет, ест ьв доке
Daniil
ребят я чет упоролься, почему монго меняет допустим название колекции с category на categories?
Что используется? Язык/драйвер
Anonymous
Что используется? Язык/драйвер
незнаю что даже ответить, установил, пользуюсь. Вроде ангилйский
Anonymous
ребят я чет упоролься, почему монго меняет допустим название колекции с category на categories?
это видимо монгуз, он автоматом плюрализирует
Anonymous
mongoose.pluralize(null) если еще работает. я его не юзаю
Anonymous
погугли
Anonymous
https://mongoosejs.com/docs/api.html#mongoose_Mongoose-pluralize
Anonymous
клиент это любое ПО которое общается с монгой, сервер это монга
1 и 2 значит что вам надо в вашем языке програмирования сделать так, чтоб вы _один раз_ выбрали список тегов и их _id
3 значит что вам надо не каждый пост по отдельности обновлять, что потребует миллион запросов, а использовать multi document апдейт. самый простой вариант — сделать столько апдейтов, сколько у вас уникальных тегов.
var tags = find_all_tags();
tags.forEach(function(tag) {
videos.findAndUpdate(
{ tags: tag.name },
{
$addToSet: {
tag_ids: tag._id,
}
},
{
multi: true
}
);
});
благодарю за отличный совет. я мыслил зеркально противоположно, обновляя миллион записей, итерируя по каждой. с вашим подходом, я итерирую по сотне тегов и обновляю пачку записей за раз))
 Daniel
Daniel
Спокойной ночи, я из Венесуэлы и использую переводчик Google, у меня проблема с тем, чтобы узнать, можете ли вы мне помочь, моя база данных содержит приблизительно 10 миллионов записей, я должен пройти каждый ряд в обязательном порядке, попробуйте сделать это с помощью php / mariadb И это застряло в процессе. Как лучше всего быстро и стабильно просмотреть все эти записи? Какие инструменты я должен использовать?
 Nick
Daniel
Nick
Daniel
thanks
S
Изучаю mongo , поднял маленький проект, бд смотрю через nosqldriver. Пока что понять не могу одно, я использую lookup или populate, все работает через objectId. И когда я смотрю на эти связи я начинаю забывать что к чему относится, контролировать это пока что тяжело 😕.
Например, у юзера есть рейтинги, в рейтингах есть реф на юзера через objectIdЗаходя в таблицу рейтингов как мне понять с ходу что этот рейтинг принадлежит юзеру? Пока что я сравниваю по objectId юзера 😂
 Josh
Josh
где-то натыкался на примеры схем в оф доке вроде, но найти не получается, может у кого под рукой
а в поиске на экзампл километр лишнего
Konstantin
уже Robo 3T
CybernatiC
Доброго времени
Помогите пожалуйста с запросом, необходимо после сохранения в коллекцию объекта делать Agregate и возвращать новый объект с дополнительными запросами (lookup)
 Александр
Александр
кто с монгой работал знает как обновить запись без обновления автоматического updatedat
Bohdan
в c# драйвере для монги есть querybuilder, через него возможно, мб у тебя что-то такое есть в арсенале
Александр
я на ноде
Александр
mongoose
Bohdan
https://stackoverflow.com/questions/27157163/update-one-field-in-mongoose-model-node-js
Bohdan
ано?
Александр
мне нужно что бы при обновлении документа его updatedat оставался прежним
 Vova
Vova
Vova
Vova
Там есть теперь статический класс Builders<T>
 Alex
Alex
Всем привет. Есть вопрос. Задача проапдейтить коллекцию гигов на 300. Как более оптимально это сделать? Использовать bulk update?
Nick
мне нужно что бы при обновлении документа его updatedat оставался прежним
Делайте запросы напрямую через драйвер и ничего лишнего не изменится
Josh
Если во массиве объектов нет необходимого элемента, можно как-то дефолтом задать, чтобы inc отрабатывал с 0 на количество? Или только проверку писать и push нового элемента?
findOneAndUpdate(
{ telegramId: from.id, 'storage.type': harvestType },
{ $inc: { 'storage.$.qty': harvestQty } },
{ upsert: true, new: true }
)
Josh
прост проблемы атомарности возникают тогда
 critskiy
critskiy
Есть вопрос, связанный c NetworkInterfaceExceededTimeLimit. Реплика висит с состоянием STARTUP, в логах ошибка по указанному типу с сообщением: Couldn’t get a connection within the time limit. Я так понимаю, это надо копать в сторону соединения ?
 yopp
yopp
Есть вопрос, связанный c NetworkInterfaceExceededTimeLimit. Реплика висит с состоянием STARTUP, в логах ошибка по указанному типу с сообщением: Couldn’t get a connection within the time limit. Я так понимаю, это надо копать в сторону соединения ?
да, проверить что по всем адресам нод из rs.config любая нода может установить соединение
critskiy
да, проверить что по всем адресам нод из rs.config любая нода может установить соединение
primary нода пишет при проверке через mongo connection refused, равно как и реплика, но вот тут получается вот какое дело: к машинам подключаюсь через ssh, получается, для них тоже придется ssh настраивать?
но вот еще: если я удаляю реплику из настроек реплики на primary, и потом на primary чекаю коннект, то монга успешно подрубается к реплика серву. Как поступить в данном случае, ребутнуть настройки реплики сэта или настроить соединение?
 Артем
Артем
Коллеги, всём привет! Есть проект с монгой v3.4, wired tiger, 9 шардов, по 3 монги в реплике на шард, 16гб памяти на машину. До недавнего времени всё работало стабильно, свободной памяти было примерно по 7-8гб на машину, но за последнюю неделю стали наблюдаться просадки по памяти на машинах в разных шардах. Память проседает, пока процесс mongod не упадёт по oom'у, приходится поднимать сервис. Можете подсказать, по какой причине mongod может начинать отъедать память? Заранее спасибо.
Slavik
Ребята, как правильно в монге сделать документы для разных типов пользователей? Например есть Админы и Юзеры, правильно делать одну таблицу с полем статус и в зависимости от статуса смотреть тип юзера или два разных документа Админы и Юзеры?
yopp
primary нода пишет при проверке через mongo connection refused, равно как и реплика, но вот тут получается вот какое дело: к машинам подключаюсь через ssh, получается, для них тоже придется ssh настраивать?
но вот еще: если я удаляю реплику из настроек реплики на primary, и потом на primary чекаю коннект, то монга успешно подрубается к реплика серву. Как поступить в данном случае, ребутнуть настройки реплики сэта или настроить соединение?
Если у вас между нодами ssh тонель, то вам будет быстрее поднять vpn и обьединить все ноды в одну виртуальную сеть.
yopp
Коллеги, всём привет! Есть проект с монгой v3.4, wired tiger, 9 шардов, по 3 монги в реплике на шард, 16гб памяти на машину. До недавнего времени всё работало стабильно, свободной памяти было примерно по 7-8гб на машину, но за последнюю неделю стали наблюдаться просадки по памяти на машинах в разных шардах. Память проседает, пока процесс mongod не упадёт по oom'у, приходится поднимать сервис. Можете подсказать, по какой причине mongod может начинать отъедать память? Заранее спасибо.
Вероятнее всего изменилась структура нагрузки. Ищите проблемные запросы. Скорее всего появилось что-то с collscan по всему шарду.
Вторая проблема что у вас в монгу стреляет оом. Проверьте что монга корректно видит доступную ей память, что у вас под кэш wt выделено не больше половины этого объёма. Если кроме монге на хосте есть другие сервисы — уберите их. Если у вас на хосте больше одной монги — вынести их на отдельные хосты. Если на хостах с монгами есть монгосы, то вынести монгосы на отдельные хосты.
 Александр
Александр
Имеет ли смысл хранить небольшие пользовательские картинки, скажем аватарки, в БД?
Андрей
Народ, подскажите как правильно оформить stage для pipeline.
Суть в следующем, есть документ из логов с огромным массивом внутри.
http://joxi.ru/Y2Lp10pS7do872
Нужно данные из внутреннего массива вывести в виде отдельных документов для дальнейших манипуляций.
С помощью $unwind и $project вывод в отдельные документы сделал, оставил только data > sales массив
Вопрос, как данные из внутреннего массива вывести на первый уровень, то есть чтобы каждый документ отображал сожержимое массива data > sales без остальной иерархии
 Mike
Mike
прошу сильно не ругать но вот сделать distinct по субдокументам я пытаюcь через aggregate([{ "$match": {'publish': true, 'attribs.name':'color'} },
{ "$unwind": "$attribs" },
{ "$match": {'attribs.name':'color'} },
{ "$group": {
"_id": "$attribs.val"
}} на локальном компе 42 товара в базе - данная агрегация 2 секунды идет, на сервере 30 тысяч - тоже две секунды . Mongoose это. Как то быстрее нельзя это сделать ?
 Dmitry
Dmitry
прошу сильно не ругать но вот сделать distinct по субдокументам я пытаюcь через aggregate([{ "$match": {'publish': true, 'attribs.name':'color'} },
{ "$unwind": "$attribs" },
{ "$match": {'attribs.name':'color'} },
{ "$group": {
"_id": "$attribs.val"
}} на локальном компе 42 товара в базе - данная агрегация 2 секунды идет, на сервере 30 тысяч - тоже две секунды . Mongoose это. Как то быстрее нельзя это сделать ?
я новичек, но как по мне:
- второй $match не имеет смысла (в первом данное условие есть)
- нужны индексы для publish и attribs.name
Данный запрос, предпологаю, должен выполняться очень быстро. Может есть проблемы с серваком (его настройкой)?
Mike
я новичек, но как по мне:
- второй $match не имеет смысла (в первом данное условие есть)
- нужны индексы для publish и attribs.name
Данный запрос, предпологаю, должен выполняться очень быстро. Может есть проблемы с серваком (его настройкой)?
индексы поставил (хотя не знаю даже как это в субдокументах работает) . а по времени я сам не знаю сколько это должно занимать)). Просто у меня по идее динамический фильтр по 11 аттрибутам, а тут по одному дистинкт 2 секунды варится. Если второй матч убрать - то он все аттрибуты берет вообще. И их 20-40 у товара.
yopp
Народ, подскажите как правильно оформить stage для pipeline.
Суть в следующем, есть документ из логов с огромным массивом внутри.
http://joxi.ru/Y2Lp10pS7do872
Нужно данные из внутреннего массива вывести в виде отдельных документов для дальнейших манипуляций.
С помощью $unwind и $project вывод в отдельные документы сделал, оставил только data > sales массив
Вопрос, как данные из внутреннего массива вывести на первый уровень, то есть чтобы каждый документ отображал сожержимое массива data > sales без остальной иерархии
https://docs.mongodb.com/manual/reference/operator/aggregation/replaceRoot/#replaceroot-with-a-document-nested-in-an-array
yopp
прошу сильно не ругать но вот сделать distinct по субдокументам я пытаюcь через aggregate([{ "$match": {'publish': true, 'attribs.name':'color'} },
{ "$unwind": "$attribs" },
{ "$match": {'attribs.name':'color'} },
{ "$group": {
"_id": "$attribs.val"
}} на локальном компе 42 товара в базе - данная агрегация 2 секунды идет, на сервере 30 тысяч - тоже две секунды . Mongoose это. Как то быстрее нельзя это сделать ?
начните с explain, чтоб понять откуда эти две секунды.
вместо $unwind и $match используйте $filter
https://docs.mongodb.com/manual/reference/operator/aggregation/filter/#filter-aggregation
Андрей
👏спасибо знатоку
yopp
начните с explain, чтоб понять откуда эти две секунды.
вместо $unwind и $match используйте $filter
https://docs.mongodb.com/manual/reference/operator/aggregation/filter/#filter-aggregation
в принцпе, вместо $filter можно вообще использовать $reduce и там делать $addToSet по условию, чтоб пройтись по массиву за одну итерацию
yopp
Имеет ли смысл хранить небольшие пользовательские картинки, скажем аватарки, в БД?
почему бы и нет, если их потом будет разливать cdn
Mike
в принцпе, вместо $filter можно вообще использовать $reduce и там делать $addToSet по условию, чтоб пройтись по массиву за одну итерацию
огромное спасибо за подсказки. там суть в чем - на сайте висит фильтр. как раз по аттрибутам, мне надо соответственно его обновлять(?) каждый раз. ну или по крайней мере показывать уникальные значения в нем для атрибутов. Но пока я решил просто одноразово пробегать - искать уникальные значения только по триггерам - ну например товар добавляется в базу или снимается с продажи. тогда я снимаю все уникальные значения и куда-нибудь складываю, и уже оттуда беру, чтобы монго не мучать.
yopp
да, преагрегация таких значений звучит более разумно
yopp
в 4.2 есть materialized view
yopp
https://docs.mongodb.com/manual/core/materialized-views/index.html
yopp
жаль конечно что это нельзя на change stream повесить всё ещё
yopp
небось в 5.0 «серверные пайплайны на change stream» будет ынтерпрайз фичей
S
парни, как вы делаете auto dump mongodb?
 Aleksey
Aleksey
Добрый день. Столкнулся с проблемой. Снятие дампа происходило стандартной командой mongodump. Однако теперь при восстановлении дампа имею подобную ошибку. В инете особо ничего не нашёл, как корректно разрулить подобное. Сама ошибка : Failed: upload.orders: error restoring from upload/orders.bson.gz: an inserted document is too large
Если кто сталкивался с подобным, просьба подсказать с направлением.
Bohdan
парни, как вы делаете auto dump mongodb?
если ты юзаешь винду, можно написать bat скрипт и запускать его по виндовскому шедулеру
Serhii
Всем привет, кто-нибудь юзал pre хуки mongoose, нужно на одну из операций повесить хендлер который будет при некой операции инкремента в случае если сутки например прошли, обнулять некий каунтер, либо к этому каунтеру добавлять число
Serhii
к примеру: с 00 до 23:59 - counter: 50, выполняем $inc: 10 в 23:58, становится 60, выполняем $inc: 10 в 00:00 - counter = 10
Serhii
или легче будет просто с помощью jsa все посчитать и все?
Askhat
Ребят, кто встречался с такой ошибкой? Как решать?
(node:31) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 topologyDescriptionChanged listeners added to [NativeTopology]. Use emitter.setMaxListeners() to increase limit
Askhat
В инете просто пишут, что это к монге вроде как
Daniil
Это проблемы драйвера. Но вполне возможно, что так задумано. Нужно смотреть в issues вашего драйвера
 твій сусід зверху💢
твій сусід зверху💢
 твій сусід зверху💢
твій сусід зверху💢
 твій сусід зверху💢
твій сусід зверху💢
 yopp
твій сусід зверху💢
yopp
твій сусід зверху💢
 yopp
yopp
👍
Anonymous
Доброго времени, почему моя БД нереально медленно работает?
На Python отправляю запрос, ответ получаю через 3-5 чек
 Ilya
Ilya
может, скажите какой запрос, какие объемы данных?