На этот вопрос только вы сами можете ответить. Смотрите логи, берите в руки отладочные инструменты
У меня есть подозрение что в бесплатной версии Атлас специально «мозги е;;т»
 Dmitry
Dmitry


 yopp
yopp
yopp
yopp
У меня несколько сервисов которые очень долго работают на бесплатных тайерах в атласе и там нет никаких проблем
yopp
В том числе play.db-ai.co. Там вообще 0 ошибок связанных с атласом.
yopp
Так что ищите проблему с вашей стороны
Dmitry
почему если в моей программе я 10 раз выполняю авторизацию и выход из приложения все может летать - а на 11 раз весит 30 секунд в статусе ожидания? При чем я сам свой ‘server.js’. вообще не трогаю
yopp
почему если в моей программе я 10 раз выполняю авторизацию и выход из приложения все может летать - а на 11 раз весит 30 секунд в статусе ожидания? При чем я сам свой ‘server.js’. вообще не трогаю
Это не группа про JS. Как я вам выше написал, только вы можете найти причину. Возьмите в руки отладочные инструменты и ищите где конкретно у вас проблемы. Как минимум посмотрите на логи запросов в монгу
Dmitry
Dmitry
Это не группа про JS. Как я вам выше написал, только вы можете найти причину. Возьмите в руки отладочные инструменты и ищите где конкретно у вас проблемы. Как минимум посмотрите на логи запросов в монгу
До этого 3 года фронтом занимался, а тут за пару недель выпала необходимость запилить бек, много вопросов возникает.А теоретически статус Pending может висеть из-за того, что неустойчивое соединение с инетом (3Г) ?
Pafa
почему если в моей программе я 10 раз выполняю авторизацию и выход из приложения все может летать - а на 11 раз весит 30 секунд в статусе ожидания? При чем я сам свой ‘server.js’. вообще не трогаю
Потому что limit запросов к API чего-то там у вас может быть, идите в @nodejs

 Nikita
Nikita
ребзи, а подскажите как быть с айдишниками монги в пхп
при передаче на фронт их преобразуют в строку, а в бд они лежат в таком виде: ObjectId("5d8b754cb3829ada94a05902") найти в бд по строковому id, а там ObjectId, и наоборот, ищу по ObjectId. а там случайно строковые id с фронта сохранились
как правильно это организовать? нельзя в бд просто хранить строковые id и не мучаться?
Nikita
чем ObjectId лучше строки вообще?
yopp
чем ObjectId лучше строки вообще?
Тем, что занимает всего 12 байт и по-умолчанию назначается многой, если _id не передан при создании. Использование собственных индетификаторов оправданно в крайне редких случаях
Aleksandr
Как лучше организовать проверку на валидность DBRef при сохранении модели? Что _id был релеватным.
yopp
Как лучше организовать проверку на валидность DBRef при сохранении модели? Что _id был релеватным.
Внутри транзакции find и потом insert/update
Igor
Привет всем.
Если у меня есть документы вида:
{
_id: 123,
name: "sample",
events: [
{state: "attached"},
{state: "processed"},
{state: "broken"}
]
}
И я выполняю поиск:
{
"events.state": "broken"
}
То есть ли возможность понять какой по счёту event совпал при поиске документа?
 𝕬𝖗𝖙𝖊𝖒
𝕬𝖗𝖙𝖊𝖒
Привет всем.
Если у меня есть документы вида:
{
_id: 123,
name: "sample",
events: [
{state: "attached"},
{state: "processed"},
{state: "broken"}
]
}
И я выполняю поиск:
{
"events.state": "broken"
}
То есть ли возможность понять какой по счёту event совпал при поиске документа?
Тебе нужно уточнять по какому-либо параметру из какого документа тебе доставать.
𝕬𝖗𝖙𝖊𝖒
Привет всем.
Если у меня есть документы вида:
{
_id: 123,
name: "sample",
events: [
{state: "attached"},
{state: "processed"},
{state: "broken"}
]
}
И я выполняю поиск:
{
"events.state": "broken"
}
То есть ли возможность понять какой по счёту event совпал при поиске документа?
Вообще можно через find, потом через for вывести значения, но дальше что ты с ними делать будешь, эт хз
Igor
Тебе нужно уточнять по какому-либо параметру из какого документа тебе доставать.
Вот тут не понял. Чем именно я могу так сделать?
𝕬𝖗𝖙𝖊𝖒
Вот тут не понял. Чем именно я могу так сделать?
coll.find({...})
Это даст курсор.
Потом через for x in coll.find({...}) делать принт х. И тебе в консоль кинет значения.
𝕬𝖗𝖙𝖊𝖒
Вообще мне кажется лучше искать по доп. параметру, если нужен конкретный.
Igor
Окей, тут короче фокус в том, что я сильно-сильно упростил задачу. На самом деле в events лежит монстр в котором 40 ключей. Под этого монстра пишутся запросы вида events.monster_value: {$in: [a, b]}, lte, gte, in, nin, neq, eq и всё остальное.
Мне нужно, по хорошему, оставить в массиве events только те элементы, которые были причиной, почему документ попал в результаты
yopp
Igor
Окей, пойду убьюсь об мануалы. Спасибо
Nikita
 Nikita
Nikita

 Ilya
Ilya
Здравствуйте. Хотелось бы узнать, возможна ли реализация в монге или в мангусе capped-массивов? То есть ограниченнных массивов, работающих по принципу очереди: при превышении лимита размера массива, при добавлении нового элемента первый элемент в массиве удаляется. Пока что смог найти лишь метод validate для мангуса, но в данном случае он может только выкидывать ошибку.
Можно конечно это сделать, запихнув в update метод aggregation pipeline, и ручками добавить элемент, проверить размер и удалить старый, если лимит превышен. но какое-то это неэлегантное решение, и мне кажется, это тяжелая с точки зрения производительности функция, так что если есть какие-нибудь нативные решения или лайвхаки, я бы их лучше использовал.
Ilya
Здравствуйте. Хотелось бы узнать, возможна ли реализация в монге или в мангусе capped-массивов? То есть ограниченнных массивов, работающих по принципу очереди: при превышении лимита размера массива, при добавлении нового элемента первый элемент в массиве удаляется. Пока что смог найти лишь метод validate для мангуса, но в данном случае он может только выкидывать ошибку.
Можно конечно это сделать, запихнув в update метод aggregation pipeline, и ручками добавить элемент, проверить размер и удалить старый, если лимит превышен. но какое-то это неэлегантное решение, и мне кажется, это тяжелая с точки зрения производительности функция, так что если есть какие-нибудь нативные решения или лайвхаки, я бы их лучше использовал.
вопрос решился быстро, просто еще раз заглянул в документацию и нашел метод $slice))
 Bandikoot
Bandikoot
вопрос решился быстро, просто еще раз заглянул в документацию и нашел метод $slice))
а можно изначально сделать capped collection и не мучаться
 Alexander
Alexander
Коллеги, а как будет по-русски multikey indexes ?
 Tatar
Tatar
Составной индекс?
Гена
+
Alexander
не, на годится )) - когда индекс по нескольким обычным полям, это вполне традиционно, и разумно называть это составным индексом.
Alexander
https://docs.mongodb.com/manual/core/index-multikey
yopp
Или индекс по перечислимым типам
yopp
Или индекс по массивам
Alexander
Мммм...и на том спасибо. Не то чтобы они отличались изяществом, но уж лучше так, чем никак ))
Oleksandr
Здравствуйте,
Есть 3 сервера (MongoDB 2.6, Debian 7) в replicaSet. Я ранее здесь спрашивал как их обновлять (Rollings upgrades). Для тестов я сделал в VMware клон Primary сервера, вынес в отдельную подсеть, поменял IP адрес. Возникла следующая проблема - MongoDB находиться в статусе STARTUP2 и не принимает соеденения.
Пытался делать:
STARTUP2> rs.reconfig(configuration, force)
> ReferenceError: configuration is not defined
STARTUP2> rs.reconfig(force)
> ReferenceError: force is not defined
STARTUP2> rs.remove(prod-mongo2)
> ReferenceError: prod is not defined
Гугл подсказал что это за статус, но как из него выйти - пока не понял
 Ivan
Ivan
Я не знаю как в 2.6, но в 3.4+ я удалял репликасет и инитил его снова, потому что изменить параметры репликасета не являясь мастером нельзя с помощью rs.conf
Ivan
Запускал монгу без репликасета, дропал инфу о нем в local, запускаем с репликасетом, инитим с верными адресами
Oleksandr
Я не знаю как в 2.6, но в 3.4+ я удалял репликасет и инитил его снова, потому что изменить параметры репликасета не являясь мастером нельзя с помощью rs.conf
Т.е. из конфига убрать строчку, которая задает replicaset?
 Timoschenko
Timoschenko
Ребят, всем пример.
Подскажите,
Я вообще могу делать Object of Object в монго.
К примеру:
{
_id: 'abc',
descr: '...',
myObjects: { type: Object },
}
А потом что то вроде $push =>
abc.myObjects[ 'myKey_A' ] = {}
abc.myObjects[ 'myKey_B' ] = {}
Timoschenko
или это не правильно будет ?
 Anton
Anton
всем 👋 возможно, сейчас спрошу что-то нубское, но всё же:
допустим, мне нужны транзакции (и, насколько я понимаю, таким образом replica-set), но я не хочу заниматься администрированием распределённой системы, да и, в принципе, некоторое время даунтайма меня устраивает, если что-то там упадёт.
могу ли я (учитывая эти условия) запускать в продакшене replica-set из одного инстанса и будет ли это концептуально то же самое, что и запуск standalone версии монги? например, так (с последующим `rs.initiate()`):
docker run mongo:latest mongod --replSet rs0
yopp
всем 👋 возможно, сейчас спрошу что-то нубское, но всё же:
допустим, мне нужны транзакции (и, насколько я понимаю, таким образом replica-set), но я не хочу заниматься администрированием распределённой системы, да и, в принципе, некоторое время даунтайма меня устраивает, если что-то там упадёт.
могу ли я (учитывая эти условия) запускать в продакшене replica-set из одного инстанса и будет ли это концептуально то же самое, что и запуск standalone версии монги? например, так (с последующим `rs.initiate()`):
docker run mongo:latest mongod --replSet rs0
После запуска необходимо инициализировать реплика-сет
https://docs.mongodb.com/manual/tutorial/deploy-replica-set/
Anton
После запуска необходимо инициализировать реплика-сет
https://docs.mongodb.com/manual/tutorial/deploy-replica-set/
это да, например, так:
rs.initiate({ _id: 'rs0', members: [{ _id: 0, host: 'localhost:27017' }] })
yopp
localhost по-моему у вас не получится использовать
Anton
localhost по-моему у вас не получится использовать
получилось,
rs0:PRIMARY> rs.conf()
{
"_id" : "rs0",
...
"members" : [
{
"_id" : 0,
"host" : "localhost:27017",
...
}
],
...
}
Anton
а работает?
я попробовал подключиться монгусом и создать документ, используя сессию. получилось. без реплика-сета кидало ошибку, что нужен реплика-сет.
Anton
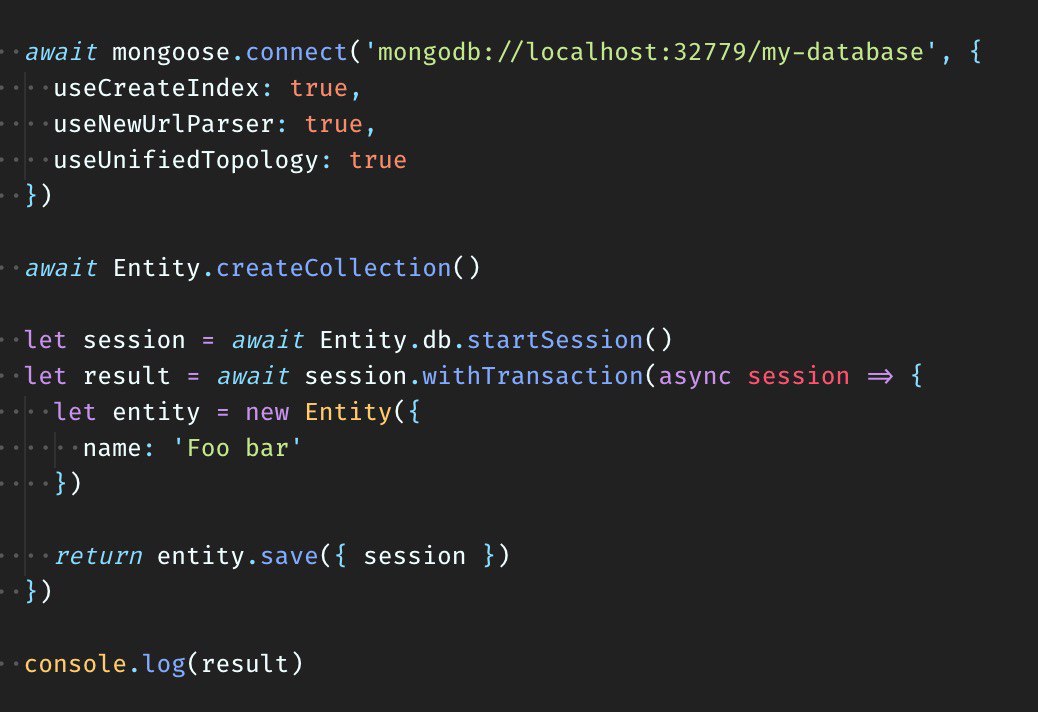 Timoschenko
Timoschenko
Ребят, всем пример.
Подскажите,
Я вообще могу делать Object of Object в монго.
К примеру:
{
_id: 'abc',
descr: '...',
myObjects: { type: Object },
}
А потом что то вроде $push =>
abc.myObjects[ 'myKey_A' ] = {}
abc.myObjects[ 'myKey_B' ] = {}
Я попробовал, и оно работает.
Теперь такой вопрос, хранить Object of Object, будет ли это быстрее с точки зрения поиска ?
тоесть вот так
{
<unieque-key>: { ... },
<unieque-key>: { ... },
}
ли вот так будет быстрее
[
{<unieque-key>: { ... }},
{<unieque-key>: { ... }},
]
Timoschenko
поидеи же первый вариант должен быть быстрее
Timoschenko
А какой лучше из 2х ? поидеи первый же не брютфорсе ?
yopp
Оба варианта не стоит использовать из-за динамических имён ключей. Вы останенетесь без индекса и поиск будет требовать просмотра всех документов. Используйте [{field: <unique value>}]
yopp
И ещё: в bson массив отличается от документа только типом и тем, что в виде ключа используется строковое представление индекса элемента в массиве.
Timoschenko
я про это и говорю что первый вариант будет быстрее. так как он имеет вот такой вид
{
<unique-key>: {},
<unique-key>: {},
}
В второй
[
{<unique-key>: {}},
{<unique-key>: {}},
]
Timoschenko
Это как бы работает, но я не понимаю как мне дать дефолтное описание сземы тогда
yopp
yopp
я ещё раз повторю: если у вас динамические уникальные имена — у вас будут проблемы с индексированием
yopp
а без индексов поиск будет требовать прочитать всю коллекцию документов. а затраты на десериализацию в обоих случаях — ничтожны
Timoschenko
Понял, Большое спасибо что "разжевал" мне .....
yopp
[{
_id: <uuid>,
value: <…>
}…]
yopp
тогда вы сможете сделать индекс и по _id и по value
Timoschenko
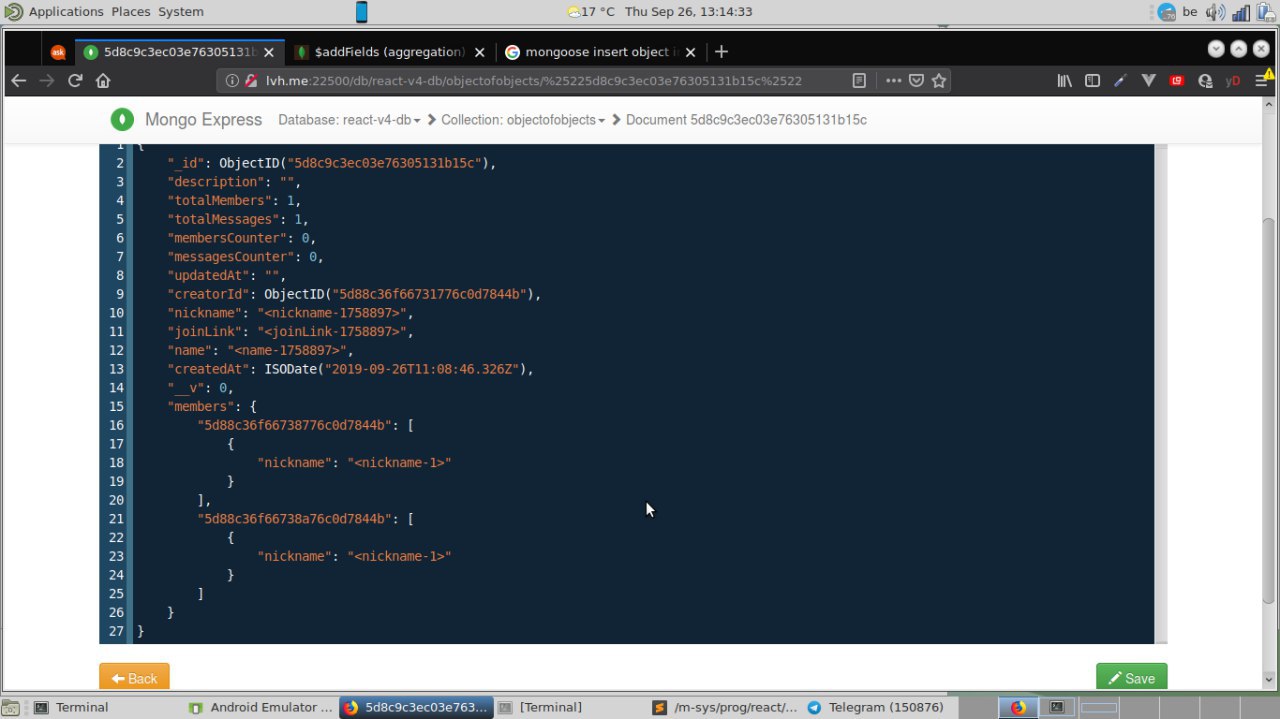 yopp
yopp
я понял, да. это неэффективная идея
yopp
members: [{_id: …, nick: …}]
Timoschenko
да, именно так и было до этого.
как по учебнику.
)) ок .спасибо еще раз
Oleksandr
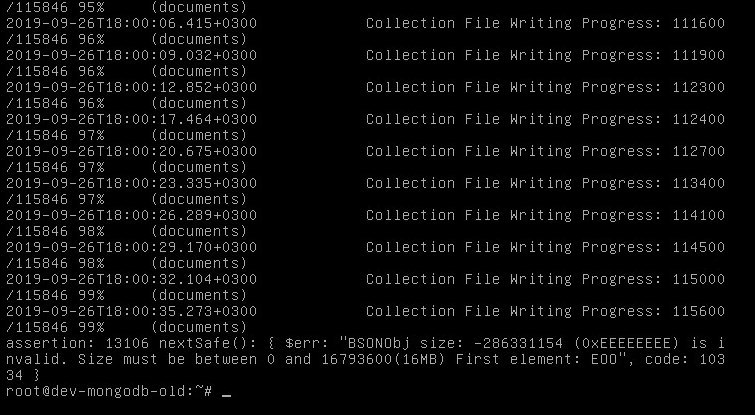 Dmitriy
Dmitriy
Добрый вечер,не подскажите какой оператор выборки необходимо использовать,что бы вывод осуществлялся только если подтверждается одно из двух условий?
 Dmitriy
Dmitriy
Добрый вечер,не подскажите какой оператор выборки необходимо использовать,что бы вывод осуществлялся только если подтверждается одно из двух условий?
https://docs.mongodb.com/manual/reference/operator/query/or/ ?