 𝕬𝖗𝖙𝖊𝖒
𝕬𝖗𝖙𝖊𝖒


Вопрос такого плана, я создал док {"id": id,"bal":"0"}. Дальше с помощью кода ниже хочу вывести само значение bal.
for abc in coll.find({"id": id}, {"_id": 0, "bal": 1}):
print(abc)#принтует {"bal":"0"}
print(abc['bal'])
Мне кидает AttributeError: "dict" object has no attribute "bal". Работаю на питоне. Также можете на js пояснить.
 Dmitriy
Dmitriy
 Max
Max
Привет!
Подскажите, пожалуйста, какой сюда лучше индекс для этой квери?
`
const session = await Sessions.findOne({
userId,
}).sort({
createdAt: -1,
});
`
Один составной:
Sessions.index({userId: 1, createdAt: -1} )
Или два разных?
 yopp
yopp
yopp
yopp
тестируйте на своём датасете
yopp
и что?
yopp
в принципе составной индекс должен быть более эффективным чем пересечение индексов, но это _гипотеза_, которая зависит от фактической селективности индексов
yopp
то что у вас там objectid и дата это ничего абсолютно не значит, потому что это не говорит о фактической частоте значений в документах
Max
в принципе составной индекс должен быть более эффективным чем пересечение индексов, но это _гипотеза_, которая зависит от фактической селективности индексов
я просто не понимаю какой инфы не хватает чтобы предположить что лучше... что нужно пробовать то понятно
оба поля мандаторные, в поле userId могут быть дупликаты
Max
ок, буду проьовать
Max
спасиб
yopp
я просто не понимаю какой инфы не хватает чтобы предположить что лучше... что нужно пробовать то понятно
оба поля мандаторные, в поле userId могут быть дупликаты
в третий раз повторяю: фактического распределения значений
Max
можно на пальцах?
yopp
количество совпадающий ключей в индексах
yopp
т.е. насколько индекс селективный
yopp
но я ещё раз повторю: вам надо взять и протестировать ваши гипотезы на ваших _реальных_ данных
yopp
и на ваших _реальных_ запросах
yopp
вам надо взять в руки explain и ваш датасет
yopp
если у вас есть данные надо не рассуждать, а проверять. это самый эффективный способ

 Nick
Nick
Так кто знает что делать?
Проверьте тип возвращаемого объекта, скорее всего вы пытаетесь работать с курсором вместо дока
𝕬𝖗𝖙𝖊𝖒
Проверьте тип возвращаемого объекта, скорее всего вы пытаетесь работать с курсором вместо дока
Да, так и есть. Но как мне сделать именно док? Создаю с помощью insert_one
Nick
Да, так и есть. Но как мне сделать именно док? Создаю с помощью insert_one
Что значит "сделать"?
𝕬𝖗𝖙𝖊𝖒
coll.insert({"id": id, "bal": "0", "invite_people": "0", "username": username})
Вот такой вот строкой создавал подобно примеру. Почему возвращает курсор, а не док?
Nick
coll.insert({"id": id, "bal": "0", "invite_people": "0", "username": username})
Вот такой вот строкой создавал подобно примеру. Почему возвращает курсор, а не док?
Потому что вы сохраняете док, а не создаёте его. Создали вы объект в терминах вашего языка, который драйвером уже сохранится как док в базу. Причем в результате действия вставки вы получаете не сам документ а результат операции, хотя это лучше уточнить в доке по используемому драйверу
Nick
Чтобы получить док из базы, то используйте find и опять же в соответвии с докой по вашему драйверу начинайте с ним работать
𝕬𝖗𝖙𝖊𝖒
 Vladislav
Vladislav
Всем привет! Ребята, есть такая задача. В коллекции users есть документы такого рода:
{
"_id" : ObjectId("5d78edf6c58fa231cca1eec6"),
"visitCount" : 2,
"purchases" : [
{
"title" : "smartphone Samsung",
"price" : 120,
"bought" : ISODate("2019-09-13T09:44:00Z")
},
{
"title" : "smartphone iPhone",
"price" : 200,
"bought" : ISODate("2019-09-08T09:44:00Z")
}
],
"views" : [
{
"page" : "index.html",
"time" : ISODate("2019-09-13T09:44:00Z")
},
{
"page" : "smarthpones.html",
"time" : ISODate("2019-09-09T09:44:00Z")
},
{
"page" : "about.html",
"time" : ISODate("2019-09-08T09:44:00Z")
}
]
}
И с помощью Aggregation pipeline нужно выбрать таких (хотя бы их айдишники), которые удовлетворяют следующему условию: (СРЕДНЯЯ сумма покупок price из коллекции purchase в диапазоне между 9 и 14 сентября не больше 120 руб) И (
(Количество просмотров из коллекции views в диапазоне дат между 9 и 14 сентября не больше 3). Я хочу подсчитать эти показатели изначально с помощью стадии $addFields. Основная сложность возникла, связанная с поиском средней суммы покупок purchase за определенный диапазон.
Если обычную сумму покупок за опр. диапазон посчитать получилось:
$addFields: {
purchaseSum: {
$reduce: {
input: "$purchases",
initialValue: 0,
in: {
$add : [
"$$value",
{ $cond: {
if: { $gte: [ "$$this.bought", ISODate('2019-09-11')] },
then: "$$this.price",
else: 0
}}
]
}
}
}
}
},
Вопрос: Как вместо purchaseSum вычислить СРЕДНЕЕ арифметическое за диапазон в данном случае?
Vladislav
первым шагом посчитать сумму и количество суммируемых элементов, а вторым поделить сумму на количество
Понятно. Спасибо!) Ну, как вариант да. То есть, первая стадия - это $addFields с purchaseSum, вторая стадия - это $addFields purchaseCount? Но сейчас вот смотрю на этот код и создалось такое стойкое ощущение, что что-то тут не то. Как-то очень сложно выглядит. Нет случайно другого способа (возможно, без addFields) покороче? 😃
yopp
зачем
yopp
сделайте сначала чтоб работало
yopp
make it work, make it right, make it scale
yopp
в таком порядке
yopp
если есть желание оптимизировать количество буковок, то сливайте его в игру в код-гольф
Vladislav
сделайте сначала чтоб работало
Просто мне на Golang билдер надо будет написать, который будет по куче подобных вложенных условий должен билдить этот aggregation pipeline. А как по мне, у golang под MongoDB API слишком "многословное" 😃. Поэтому количество потенциальных буковок хочется ограничить) Ну, ладно)
yopp
время на поиск вариантов оптимизации буковок будет на несколько порядков больше чем время на стучание по клавиатуре чтоб набить существующее количество буковок
 Vlad🍁
Vlad🍁
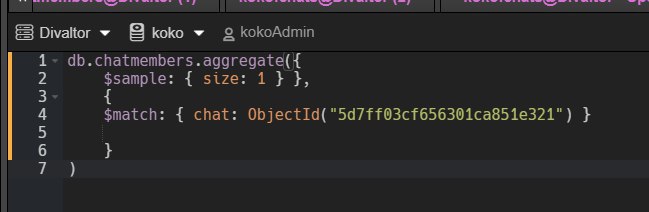
 Dmitry
Dmitry
Dmitry
Vlad🍁
Dmitry
Dmitry
Dmitry
Vlad🍁
С этим понял, поменял местами
Vlad🍁
Вроде работает
Vlad🍁
Спасибо)
 Dmitry
Dmitry
 Dmitry
Dmitry
 Dmitry
Dmitry
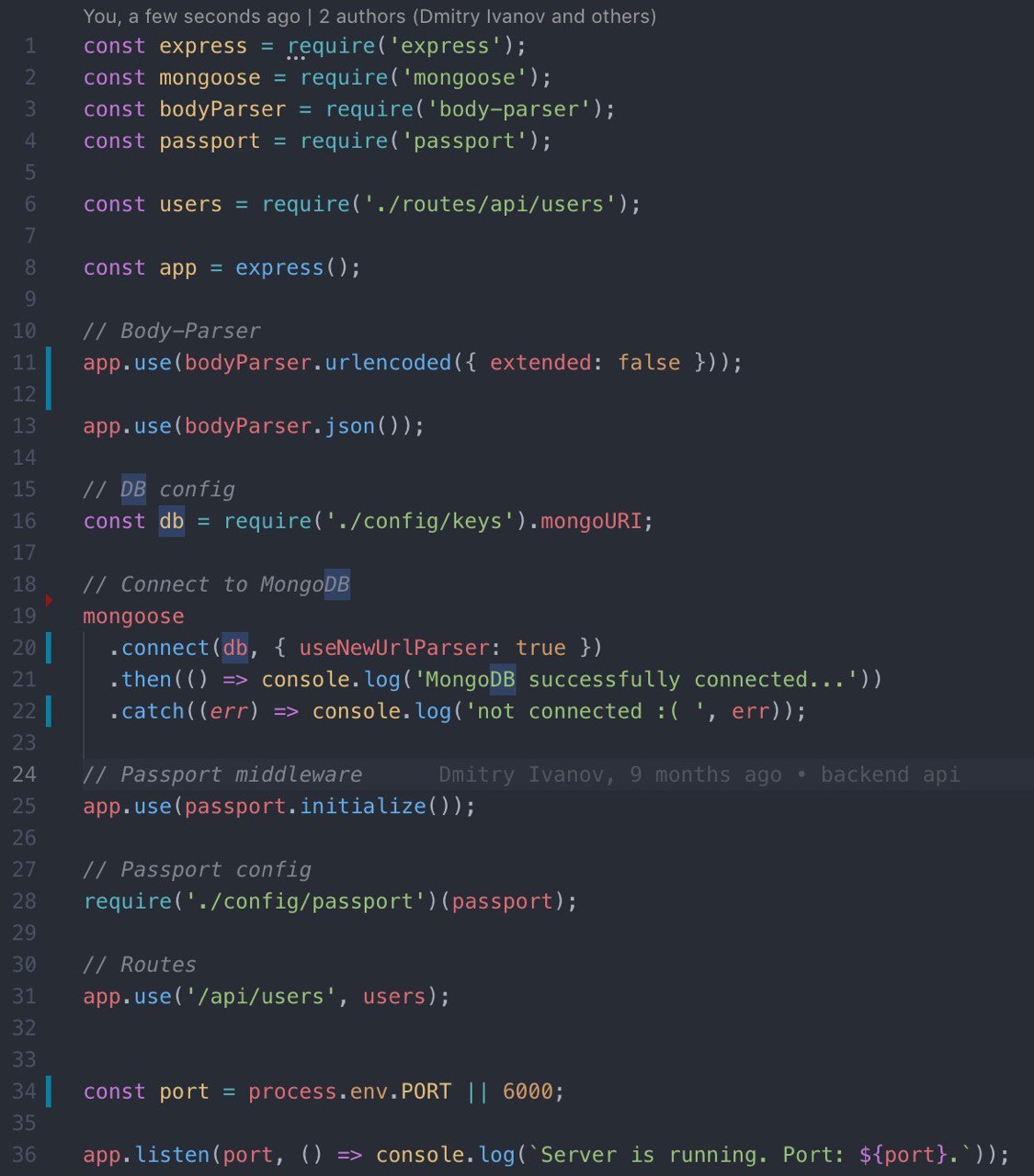
ну и собственно keys.js:
module.exports = {
mongoURI: "mongodb://username:qwerty@ds016118.mlab.com:16118/hghg»,
secretOrKey: "secret",
};
Anonymous
ну и собственно keys.js:
module.exports = {
mongoURI: "mongodb://username:qwerty@ds016118.mlab.com:16118/hghg»,
secretOrKey: "secret",
};
мб там есть хрень как на mongodb atlas, что в конфигах сети в вайтлист свой ип надо добавить
 MⅨ
MⅨ
А кто-то пробовал менять конфигурацию в рантайме в самом приложении. Допустим под экспрессом?
Dmitry
мб там есть хрень как на mongodb atlas, что в конфигах сети в вайтлист свой ип надо добавить
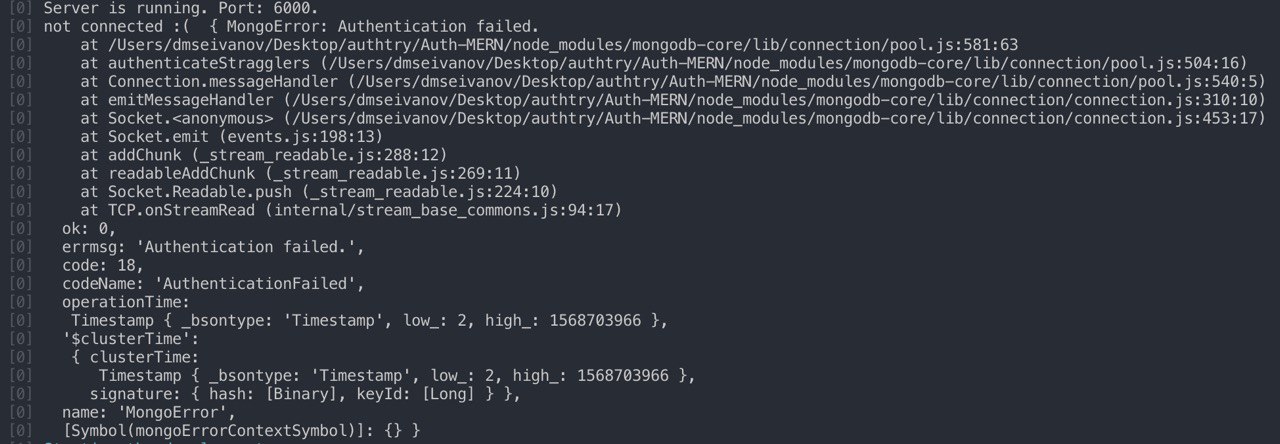
Да вот я и смотрю ща какой то атлас нагрянул. Когда последний раз юзал mlab (дек 2018) все работало, а сейчас выдаёт ошибку (склонировал свой старый реп)
Daniil
MⅨ
Ну допустим mongoDB Api access url
MⅨ
для MongoDB клиента
Гена
Подскажите пожалуйста, у нас монга в конфигу выставлено cacheSizeGB: 12 а ест он почти 40гб оперативы
Гена
в чем может быть дело
yopp
На остальные структуры это никак не влияет
Гена
то есть просто много запросов пошло?
yopp
Да, например большие агрегации или множество сортировок в памяти.
yopp
Какая версия?
Гена
4.0.4
yopp
Транзакции используются?
Гена
конечно
yopp
Тогда ещё снепшоты wt
Гена
понял) спасибо
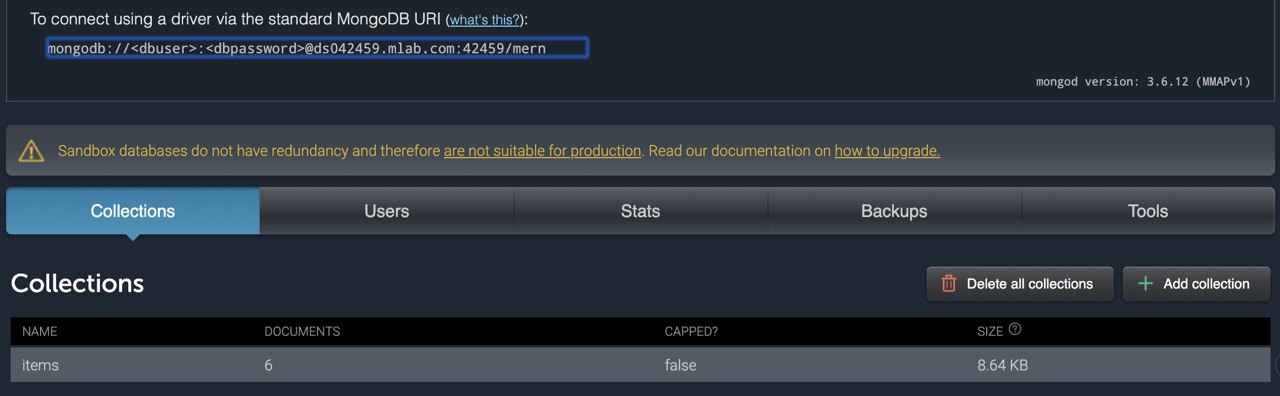
Dmitry
Парни, правильно я понимаю, что в файле server.js строчка
app.use('/api/items', items);
а именно «/api/items» указывает на коллекцию «items», если речь идет о бесплатной БД от mLab ?
Dmitry
 Dmitry
Dmitry
То есть если коллекция называется «profiles» то и путь будет «/api/profiles» верно?
 Alexander
Alexander
Всем привет!
Скажите, процесс Mongod - многонитиевый?
Если посадить один mongod (как участника replica set) на 16-ядерную машину и нагрузить хорошенько запросами, мы имеем шанс увидеть высокую степень утилизации CPU?