 Alexander
Alexander


Но это всё очень плохо пахнет.
 Anonymous
Anonymous
Ну вот у меня сработал маленький батч и чтение с мастера (примари преверред).
А праймари преферред стоит не по дефолту?
Alexander
А праймари преферред стоит не по дефолту?
У меня по дефолту секондари. Иначе ляжет всё нахрен. :-)
Anonymous
У меня по дефолту секондари. Иначе ляжет всё нахрен. :-)
А у меня только рид-онли права на монгу, поэтому не волнуюсь)
Хотя мне советовали указать секондари преферрд (я попробовал и ничего не поменялось), праймари преферрд я еще не указывал, стоит попробовать
Alexander
А у меня только рид-онли права на монгу, поэтому не волнуюсь)
Хотя мне советовали указать секондари преферрд (я попробовал и ничего не поменялось), праймари преферрд я еще не указывал, стоит попробовать
Проблема не в правах, а в нагрузке. Если у меня все начнут читать из мастера, то он долго не проживёт.
Anonymous
 Nikita
Nikita
ребят, а как определить, массив с инвайтами хранить внутри сущности, к которым они относятся, или в отдельной коллекции ?)
 MⅨ
MⅨ
добрый как искать с использованием шарда
 yopp
yopp
рассматривал $setDifference но он не подходит, так как мне нужно отфильтровать входной от юзера массив удаляя из него записи которые присутствуют в коллекции, а не вернуть для каждой из записейв в монге разницу между входным массивом и массивом в каждом документе...
Вероятно только если все 6м записей сделать отдельными документами и через $nin по индексированному атрибуту те записи которых нет (или через $in которые есть, что будет быстрее) и на клиенте уже фильтровать.
Но это если 1к фиксированный.
Как много таких запросов?
yopp

 Oleg
yopp
Oleg
yopp
ребят, а как определить, массив с инвайтами хранить внутри сущности, к которым они относятся, или в отдельной коллекции ?)
Если сущность без инвайтов не имеет смысла, то тогда рядом с сущностью. Если продолжает иметь смысл и инвайтов не сотни, то как удобнее. Если инвайтов неограниченное количество, то в отдельной коллекции.
yopp
find, aggregate
yopp
Бонусные баллы за шард ключ в условиях запроса
alex
Вероятно только если все 6м записей сделать отдельными документами и через $nin по индексированному атрибуту те записи которых нет (или через $in которые есть, что будет быстрее) и на клиенте уже фильтровать.
Но это если 1к фиксированный.
Как много таких запросов?
ну сейчас на клиенте и фильтрую... ладно, видимо лучшего способа нету. Спасибо за помощь :)
yopp
ну сейчас на клиенте и фильтрую... ладно, видимо лучшего способа нету. Спасибо за помощь :)
В принципе $nin и есть то что вы хотите. Если в проекции оставить только искомый атрибут, то вы и получите массив, правда документов с одним атрибутом.
alex
В принципе $nin и есть то что вы хотите. Если в проекции оставить только искомый атрибут, то вы и получите массив, правда документов с одним атрибутом.
мне надо наоборот выбрать то, что справа от $nin
alex
не слева... то есть из массива входного вычесть то, что в базе есть и вернуть входной массив обратно
yopp
А, тьфу. Понял. Не из базы достать того что нет, а отфильтровать того что нет в базе.
alex
дада
yopp
Тогда да, $in и отрезать на клиенте
alex
угу... ну лан, думал может можно за одну операцию на базе это сделать
alex
думал через $lookup + match по size
alex
но это как-то геморно
yopp
$lookup тут не нужен. Вы можете попробовать сделать $match по $in, сгруппировать в один массив и потом в $project сделать $setdiffirence
alex
мм... не, не подойдет
yopp
Вам возможно потребуется $let чтоб передать весь список
alex
не буду мучать, спасибо в любом случае
alex
сейчас проверю...
alex
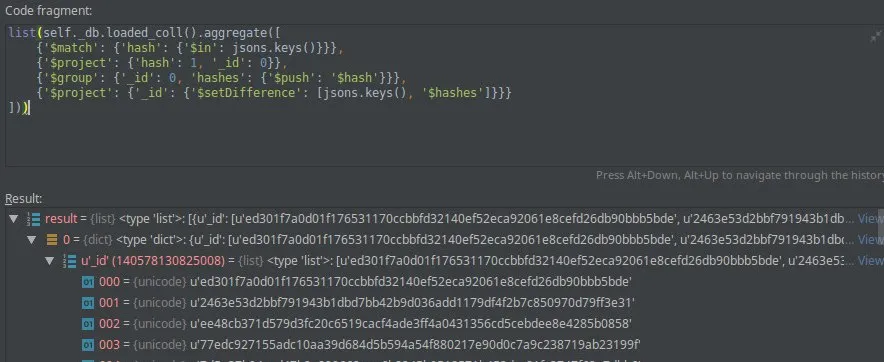 yopp
yopp
работает :) спасибо) вопрос нужен ли $project перед группировкой ?
я не помню умеет ли AF в covered query, можете проверить
yopp
у вас по hash есть индекс?
yopp
умеет. попробуйте оставить hash: 1, _id: 0 и посмотреть на explain с executionStats чтоб убедится что оно по документам не сканирует
alex
да IXSCAN, я думаю запрос выполнялся бы гораздо дольше если не индекс
alex
спасибо )
yopp
и ещё рассмотрите возможность хеши хранить в двоичном представлении
yopp
у вас они у вас там в десятки байт и вероятно конвертировав из hex в bin и храня их как Binary вы можете на 45% размер сократить
alex
потом будет не удобно в консоли писать запросы...
alex
кстати замерил скорость выполнения, в монге аггрегейт в два раза дольше чем find/$in и вычитание сетов в рантайме в питоне...
yopp
это какие порядки?
alex
0.011 сек против 0.0052
yopp
не заморачивайтесь даже
alex
ок) спасибо за помощь
yopp
11 мс против 5 мс даже нет смысла более точно сравнивать
yopp
у вас запрос получается в два раза больше, потому что дважды дублируются данные. так что разница может быть обусловлена исключительно сетевой задержкой :)
alex
на тестовой тачке база прямо на ней стоит, думаю просто из-за большего запроса, может через $let было бы быстрее, но как вы и сказали, нет смысла копать дальше
Askhat
Ребят, подскажите. Развернул бд на одном сервере и есть Mongo Atlas M20 (реплика 3 ноды)
Обе базы идентичны. Делаю один и тот же запрос. На первом сервере в 10 раз быстрее происходит обработка чем на втором (которая реплика)
Почему так?
yopp
10 раз это в каких порядках?
Askhat
На первом сервере за 72 мс, на реплике 973 мс
yopp
сеть, индексы, производительность
Askhat
сеть, индексы, производительность
Мне кажется , что реплика развёрнута в Вирджинии, а вторая бд во Франкфурте. Может быть из-за этого?
yopp
может быть, да
yopp
простой способ понять сеть или производительность это сделать explain с executionStats
Askhat
А бэк во франкфурте. Он обращается до реплики
yopp
будет видно сколько реально выполнялся запрос
Никита
Мне кажется , что реплика развёрнута в Вирджинии, а вторая бд во Франкфурте. Может быть из-за этого?
Межатлантические запросы это всегда +300..+500 мс, переезжай в один дата центр
Serhii
Ребята, использую mongoose, после сохранения номера в базу, к телефону добавляется phone.0, как избавится от 0, хранить как строку? Или есть какие-то надстройки для mongoose
Askhat
Serhii
Покажите схему
А что ее показывать, тип Number у поля телефон, почему оно добавляет точку с ноликом когда пишет в базу и как это можно пофиксить, сейчас я решил эту проблему записывая телефон как строку, но интересно было бы узнать как это фиксится
 Ilya
Ilya
ну а какой смысл телефон хранить числом вы с ним будете делать арифметические операции? сомневаюсь, упорядочивание в крайнем случае и по строке нормально работает.
Askhat
А что ее показывать, тип Number у поля телефон, почему оно добавляет точку с ноликом когда пишет в базу и как это можно пофиксить, сейчас я решил эту проблему записывая телефон как строку, но интересно было бы узнать как это фиксится
Делайте хорошую валидацию, храните как строку. У mongoose есть свойство validate например
Serhii
Мне без разницы как хранить, интересно услышать почему происходит с числом такая хрень, спасибо за фидбек
 Nick
Serhii
Nick
Serhii
Где добвляется? Где вы это видите?
В базе, в робо3т, даже квери 3803.0 находит телефон, 3803 не находит
Nick
Значит это дабл
Nick
Проверьте тип поля
Ilya
народ правильно ли я понимаю, что если мне надо по координате найти документы в которые она попадает в поле с GeoJSON объектом типа polygon мне надо составлять запрос через оператор $geoIntersects ?
Типа
{
location: {
$geoIntersects: {
$geometry: {
"type": "Point",
"coordinates": [
60.508182808, 56.79992601
]
}
}
}
}
то есть искать пересечние точки и полигона?
Ilya
просто ничего более подходящего не нашел
Ilya
спасибо
Anonymous
Для разработки использовал бесплатную песочницу MongoDB Atlas. В целом она меня всем устраивает, данных не ожидается много и даже бесплатного тарифа хватило бы с головой, однако бэкапы доступны только для платных тарифов (минимум $9). Так вот вопрос: стоит ли заморачиваться и развертывать свою БД под продакшн в таком случае? В деньгах особой выгоды не будет (деньги не космические), а вот головной боли, боюсь, прибавится (в основном связанной с администрированием).
Anonymous
Можешь попробовать какое-то облако