 RapidCodeLab
RapidCodeLab


по скрину похоже на пуш уведомление, но это все что я смг понять, чет сленг адский)
 ghett
ghett
это строение карточки в системе google material design
ghett
по скрину похоже на пуш уведомление, но это все что я смг понять, чет сленг адский)
сорь, попробую развернуть мысль
RapidCodeLab
не забудьте упомянуть стек технологий
ghett
я написал скрипт, который обращается пока просто к массиву массивов:
[
["Rich media","Primary title", "Supporting text", "Actions"]
["Rich media","Primary title", "Supporting text", "Actions"]
["Rich media","Primary title", "Supporting text", "Actions"]
["Rich media","Primary title", "Supporting text", "Actions"]
]
в итоге каждый подмассив содержит в себе набор данных для одной такой "карточки" как на картинке выше, карточки формируют ленту
ghett
стек технологий очень прост — чистый JS
RapidCodeLab
что такое чистый js ? клиентский чтоли ?
ghett
да
ghett
я не знаю. что будет дальше у меня, пока вообще просто переменная хранит массив массивов.
по идее оно где то будет храниться потом и пытаюсь понять — в каком виде лучше хранить
RapidCodeLab
если вы на клиенте, чет не пойму,какое вам дело до бэкенда и mongodb в частности
RapidCodeLab
отдавайте на бэкенд в json , бэкенд разберется как ему хранить
RapidCodeLab
и "массив массивов", имхо лучше говорить "многомерный массив" )
ghett
ну это единственный чат у меня в котором есть бекендеры
ghett
и "массив массивов", имхо лучше говорить "многомерный массив" )
да, Вы правы, спасибо
ghett
я и сам тешу себя мыслью всё делать самому, по миниуму хотя бы
RapidCodeLab
бэкендеры с удовольствием примут json объект, дальше пусть у вас голова не болит)
RapidCodeLab
protobuf былоб вообще идеал, но не в курсе как там на клиентах с этим
ghett
protobuf былоб вообще идеал, но не в курсе как там на клиентах с этим
Protocol buffers currently support generated code in Java, Python, Objective-C, and C++. With our new proto3 language version, you can also work with Dart, Go, Ruby, and C#, with more languages to come.
RapidCodeLab
ну понятно, у меня на go все норм с этим) тогда имхо json только
ghett
ясн, спасибо
RapidCodeLab
Protocol buffers currently support generated code in Java, Python, Objective-C, and C++. With our new proto3 language version, you can also work with Dart, Go, Ruby, and C#, with more languages to come.
https://github.com/protobufjs/protobuf.js гугл говорит, что не все так плохо

 Stas
Stas
бэкендеры с удовольствием примут json объект, дальше пусть у вас голова не болит)
если в json объекте будет лежать нормальная дата, было бы не плохо
Stas
 Stas
Stas
формат дата в монго
Stas
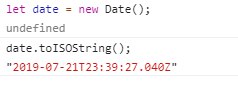 Stas
Stas
если в таком виде отправить дату, она прям отличненько в монго зайдёт
RapidCodeLab
если в таком виде отправить дату, она прям отличненько в монго зайдёт
в go вообще нормально, я вообще рад, как без проблемно все с официальным драйвером все работает)
RapidCodeLab
хотя тут почти не обсуждается)
RapidCodeLab
но оно и понятно, проблем особо нет)
Stas
не знаю как там, но могут в разном формате прислать на бэк и потом думай как перекрутить
Stas
типа строкой с выдуманным форматом под себя
RapidCodeLab
в моем случае и фронт и бэк мой,)
 yopp
yopp
Коллеги, всем привет!
Подскажите, как лучше решить такую ситуацию:
есть кластер (ReplicaSet из 3-х монг). В случае падения мастера, одна из реплик становится мастером. Как лучше реализовать проверку, чтобы, к примеру стоял балансировщик (haproxy), и всегда пробрасывал на мастер, а в случае фейла, проверял, кто сейчас стал мастером, и посылал запросы уже на него. Есть какое-либо встроенное решение, или придется юзать сторонние балансеры?
Failover встроенный, вам не нужно использовать сторонние инструменты.
yopp
Привет! У меня "околомноговский" вопрос. Есть коллекция с документами у каждого из которых 3 из 15+ полей - тяжелые массивы, где-то так от 500Кб до 2-5 Мб. Как массивы они юзаются только в самом начале их создания, потом же - только изредка для чтения..
Вопрос: как их мозжно сжать на прикладном уровне - алгоритмом или ещё как-то. то есть кодить/декодить на стороне приложения. Как обычно это делают?
Если нельзя, то в какой сторедж их обычно выносят? Я думаю про AWS S3 + Cloudfront - что скажете?
Положите в отдельную коллекцию эти массивы как есть. Может включить zlib для этой коллекции, создав ее вручную и передав туда wiredtiger configuration string. Когда станет дорого хранить в монге, тогда и будет понятно где хранить дешевле.
 Max
Max
Положите в отдельную коллекцию эти массивы как есть. Может включить zlib для этой коллекции, создав ее вручную и передав туда wiredtiger configuration string. Когда станет дорого хранить в монге, тогда и будет понятно где хранить дешевле.
Спасибо, похоже на решение.
У меня уже 20 Гб в монге за 4 месяца. Хотел решить проблему сейчас, когда данных не так много
yopp
Я задам классический вопрос почему 20гб это проблема :)
yopp
Если это психологическая проблема, то вообще не стоит ничего делать. 20гб за 4 месяца это 60гб в год, это даже в Атласе будет ну может 300 баксов. Вряд ли вы даже перенос в другую колелекцию будет дешевле 300 долларов и даст какую-то экономию которая эти 300 долларов откупит.
Max
Я задам классический вопрос почему 20гб это проблема :)
Я же писал выше. Проблема с disk i/o. Думаю как затюнить часть коллекций
yopp
Нажать кнопочку upgrade
Max
Если это психологическая проблема, то вообще не стоит ничего делать. 20гб за 4 месяца это 60гб в год, это даже в Атласе будет ну может 300 баксов. Вряд ли вы даже перенос в другую колелекцию будет дешевле 300 долларов и даст какую-то экономию которая эти 300 долларов откупит.
Я думал это вообще это с монги далой на s3
Max
И 200 iops ..
Max
Ваше время все равно дороже
А как понять, подходит ли моя конфигурация железки БД тому что я с этой бдшкой)?
Max
Бдшкой делаю
yopp
Вы уже все делаете правильно. Заболело, проапгрейдились
Max
Вы уже все делаете правильно. Заболело, проапгрейдились
я не уверен что это хорошая идея =(
обыгрывать проблемы на уровне железки, когда можно на уровне кода
как-бы технический долг и деньги клиента
yopp
Можно добавить проактивности, выбрав какие-то метрики которые отражают ваше представление о «подходит», посчитать на какие цифры на них алерты поставить, чтоб с запасом и нажимать upgrade до отказа)
yopp
yopp
Добавить ресурсов самый дешёвый способ. У вас копеечные объемы данных. Можете сами посчитать сколько часов у вас займёт «оптимизация», умножить на три и потом посчитать сколько денег может принести такая оптимизация и поделить на три. Практически уверен что ваша работа никогда не окупится.
yopp
Если у вас там есть какие-то отказы, связанные с деплоем новой версии, то посчитать убыток, умножить на частоту и понять например сколько это в деньгах в год стоит. Это будет ваш бюджет на починку. Если вы предполагаете что починить можно просто переложив куда-то данные, то переложите в отдельную коллекцию в монге.
Max
Если у вас там есть какие-то отказы, связанные с деплоем новой версии, то посчитать убыток, умножить на частоту и понять например сколько это в деньгах в год стоит. Это будет ваш бюджет на починку. Если вы предполагаете что починить можно просто переложив куда-то данные, то переложите в отдельную коллекцию в монге.
просто сок в том, что переложить их на S3 займёт не на много больше времени чем перенести в отдельную колекцию,,,
но это так, предположение)
yopp
просто сок в том, что переложить их на S3 займёт не на много больше времени чем перенести в отдельную колекцию,,,
но это так, предположение)
Вам решать. Но я ещё раз рекомендую посчитать сначала убытки от проблем.
S3 это дополнительное хранилище, это добавит сложности как в приложении, так и в сопровождение. Как минимум будет головная боль с резервными копиями. Поиск по данными будет близко к невозможному, если вдруг понадобится.
Я за то чтоб выносить ненужные данные из хранилищ, но это должно быть обусловлено ценой.
А 20гб это масштаб еле дотягивающий даже до десятков долларов. Если вы нашли что у вас при запуске приложения требуется прочитать кучу документов, в которых хранятся эти массивы, то проще всего вынести эти данные в отдельную коллекцию.
Из отдельной коллекции потом в вынести в другое хранилище будет проще, так как данные уже будут разделены.
 Fess
Fess
Failover встроенный, вам не нужно использовать сторонние инструменты.
Например 2.mongobd.ru - secondary, когда сломается, мастером станет 3.mongodb.ru - и чтобы приложение ходило уже на 3 ноду
yopp
Например 2.mongobd.ru - secondary, когда сломается, мастером станет 3.mongodb.ru - и чтобы приложение ходило уже на 3 ноду
Драйвера, если они соблюдают спецификацию, сами разрешат эту ситуацию.
Вам остаётся только указать список серверов в connection string или настроить SRV запись.
Max
@dd_bb а не подскажешь как оптимальнее - балк инсёрт / апдейт - или апдейтить по одному документу?
yopp
@dd_bb а не подскажешь как оптимальнее - балк инсёрт / апдейт - или апдейтить по одному документу?
Оптимальнее никогда не обновлять документы
yopp
Что «?»
 Sardor
Sardor
Оптимальнее никогда не обновлять документы
А как юзать монгу? Удалять документ и писать новый?
yopp
А как юзать монгу? Удалять документ и писать новый?
Как и любое друге хранилище и не забивать себе голову «оптимальностью» пока нет реальной проблемы.
yopp
но обновлять данные как-то нужно же)
Тогда в чем проблема с обновлением документов по одному? ;)
Max
 Fess
Fess
Fess
Fess
Спасибо!
Max
народ, а монга умная? если у меня в матче 5 кондишенов на 5 разных полей, и только на один из них индекс - она начнёт с индекса кверить?
Sardor
Как и любое друге хранилище и не забивать себе голову «оптимальностью» пока нет реальной проблемы.
Т.е. к апдейтам Ваше сообщение не относилось?
yopp
Если сравнивать абстрактную эффективность в вакууме то в любом хранилище вставка будет более производительной чем обновление. Так как обновление требует сначала найти запись, потом выполнить с ней какие-то трансформации, а потом уже записать результат и обновить индексы. Вставка же сводится к записать данные и добавить новые ключи в индекс.
Max
Если сравнивать абстрактную эффективность в вакууме то в любом хранилище вставка будет более производительной чем обновление. Так как обновление требует сначала найти запись, потом выполнить с ней какие-то трансформации, а потом уже записать результат и обновить индексы. Вставка же сводится к записать данные и добавить новые ключи в индекс.
но ведь тогда нужно удалить старую запись)
yopp
Нет, не нужно
yopp
Потому что удаление это настолько дорогая операция, что многие хранилища просто помечают данные как удаленные, но не удаляют их.
yopp
Одно из простых решение это использование двух атрибутов: уникальный идентификатор данных и номер версии. И по этой паре создаётся составной индекс, в котором версия это постфикс и у неё порядок сортировки по убыванию. Связи между данными устанавливаются с использованием идентификатора данных, а не записи, а при выборке используется чуть более сложное условие, в котором выбирается только последняя версия.
yopp
Но ещё раз: это про абстрактных коней в гипотетическом вакууме.
Эффективности в отрыве от реальной проблемы не существует.