 new
new

 new
new
module.exports.dbServer = '127.0.0.1'; // set to you database server
module.exports.dbName = 'Int-Rev_Blog'; // set to you database name
var mongoose = require('mongoose');
mongoose.Promise = require('promise');
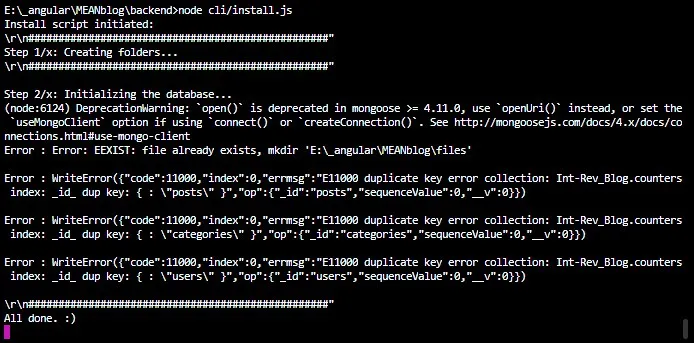
mongoose.connect('mongodb://' + this.dbServer + '/' + this.dbName, { useMongoClient: true });
module.exports.mongoose = mongoose;в подключении есть useMongoClient: true
 Semyon V
Semyon V
Господа, добрый вечер. С ходу вопрос, а есть какой-то изящный способ используя Mongoose (Typegoose даже), сделать 1 (ну ладно, 2)-liner для инкремента записи по запросу. Задача: таблица поисковых запросов. Нужно инкрементить счётчик у записи с соответсвующим поисковым запросом.
Semyon V
await SearchModel.findOneAndUpdate(
{ request },
{
$set: {
request,
lastSearch: new Date()
},
$inc: { count: 1 }
},
{ upsert: true }
).exec();
выглядит как-то уж очень многословно
Semyon V
nnbphkqujhjkynr
да, это ты какой проект пробуешь запустить по счету?
Semyon V
зачем же это делать через C#?
Semyon V
мне почему-то кажется, что если нужен дамп, то язык программирования здесь не особо причём
Oleg
Какие нужно сделать индексы для этих запросов?
.count({
operation: 100,
source: 'generator',
owner_id: ctx.from.id
})
.findOne({
operation: 100,
source: 'generator',
owner_id: ctx.from.id
}).sort({created_at: -1})
.aggregate([
{
"$match": {
operation: 100,
source: 'generator',
created_at: {$gt: new Date(Date.now() - 2 * 60 * 60 * 1000)}
}
},
{
"$project": {
"y": {"$year": "$created_at"},
"m": {"$month": "$created_at"},
"d": {"$dayOfMonth": "$created_at"},
"h": {"$hour": "$created_at"},
"value": 1
}
},
{
"$group": {
"_id": {"year": "$y", "month": "$m", "day": "$d", "hour": "$h"},
"total": {"$sum": "$value"}
}
},
{$sort: {_id: -1}},
{$limit: 1}
])
Anonymous
 Anonymous
Anonymous
 Anonymous
Anonymous
mycol.find({ f"time_to_receive.{i}": { '$elemMatch': {'$eq': time}}})
Вернет все колонки сразу, а не по одной?
Oleg
/ban
 The first
The first
/ban@combot
 Maxim
Maxim
Как добавить в документе
user
{
userid,
style,
tasks {
{task1},
{task2}...
}
}
элемент в tasks?
Anonymous
Может лучше сделать tasks массивом ?
Anonymous
tasks [
{task1},
{task2}...
]
Maxim
как добавить элемент в массив?
Anonymous
.push() добовляет в конец
Maxim
спасибо
Denys
Всем доброго времени суток, я начинаю вникать в mongodb и пытаюсь понять, что значит атомарные операторы. Читаю на английском, поэтому буду благодарен, если в двух словах на родном языке кто-то обьяснит)
Amir
коллеги, а кто-то может подсказать хорошую статью как использовать strem? немного не пойму как между перезапусками сохранять состояние на клиенте
Anonymous
Всем доброго времени суток, я начинаю вникать в mongodb и пытаюсь понять, что значит атомарные операторы. Читаю на английском, поэтому буду благодарен, если в двух словах на родном языке кто-то обьяснит)
операция либо пройдет целиком, либо целиком не пройдет. Не будет такого, что половина запроса применилась, а вторая половина развалилась
до 4.0 монга атомарна на урове конкретных документов, в 4.0 появились транзакции
Евгений
Всем доброго времени суток, я начинаю вникать в mongodb и пытаюсь понять, что значит атомарные операторы. Читаю на английском, поэтому буду благодарен, если в двух словах на родном языке кто-то обьяснит)
Можете ещё вот эту небольшую переписку почитать о bulk-операторах, что бы не было неоднозначного понимания атомарности.
Атоморность в Монге < 4 версии обеспечивается на уровне документов, а не операций. Было сказано выше.
 yopp
yopp
yopp
yopp
Multidocument операции не будут гарантировать атомарность всего множества операций, а только каждой конкретной по отдельности
yopp
коллеги, а кто-то может подсказать хорошую статью как использовать strem? немного не пойму как между перезапусками сохранять состояние на клиенте
https://docs.mongodb.com/manual/changeStreams/#resume-a-change-stream
Евгений
Если на пальцах объяснять, то, например, ты делаешь сохранение документа в БД. Всегда есть шанс, что документ может быть не сохранен по разным причинам. Атомарность означает, что либо весь документ у тебя сохранится, либо ничего. Промежуточного результата не будет.
yopp
Но надо учитывать что resume ограничен размером журнала репликации. Т.е. если точка в которой мы остановились выпала из журнала, восстановить положение будет невозможно.
Евгений
Всем доброго времени суток, я начинаю вникать в mongodb и пытаюсь понять, что значит атомарные операторы. Читаю на английском, поэтому буду благодарен, если в двух словах на родном языке кто-то обьяснит)
А вообще, вот значение слова atomic
http://foldoc.org/atomic
Oleg
Какие нужно сделать индексы для этих запросов?
.count({
operation: 100,
source: 'generator',
owner_id: ctx.from.id
})
.findOne({
operation: 100,
source: 'generator',
owner_id: ctx.from.id
}).sort({created_at: -1})
.aggregate([
{
"$match": {
operation: 100,
source: 'generator',
created_at: {$gt: new Date(Date.now() - 2 * 60 * 60 * 1000)}
}
},
{
"$project": {
"y": {"$year": "$created_at"},
"m": {"$month": "$created_at"},
"d": {"$dayOfMonth": "$created_at"},
"h": {"$hour": "$created_at"},
"value": 1
}
},
{
"$group": {
"_id": {"year": "$y", "month": "$m", "day": "$d", "hour": "$h"},
"total": {"$sum": "$value"}
}
},
{$sort: {_id: -1}},
{$limit: 1}
])
Artem
У меня есть колекция в которой есть поле statistics типа array, которое хранит объекты {id: ..., total: ...}
И вот мне нужно добавить если в statistics нету объекты с указаным ключем, а если есть то просто проинкрименить тотал.
Можно ли так сделать?
Ivan
по принципу ESR
можно так:
{ operation: 1, source: 1, created_at: 1 }
Ivan
можно еще последним добавить owner_id: 1
но часть запросов будут использовать только 2 leading fields либо же еще раз добавить { operation: 1, source: 1, owner_id: 1 }
Ivan
тогда записи в индексах будут пересекаться что не оч хорошо
Oleg
тогда записи в индексах будут пересекаться что не оч хорошо
И какой тогда самый верный вариант?
Ivan
как много различных данных в owner_id?
Ivan
такой же вопрос по operation и source
Ivan
если уникальных данных в этих полях мало то и индекс надо строить по-другому
Oleg
Значение 100 для operation
И generator для source
А owner_id много разных
Ivan
самым (пока) хорошим вариантом это
{ created_at: 1, owner_id: 1 }
Ivan
все остальные поля как я понял имеют ооочень мало различных/уникальных данных и их бестолку индексировать
yopp
берёте срез данных
yopp
берёте высказнные в группе гипотезы
yopp
берёте запросы
yopp
и проверяете, укладываются ли запросы в ваши требования
yopp
например created_at это так себе индекс, из-за низкой селективности. т.е. один уникальный ключ индекса будет скорее всего указывать всего на один документ. т.е. всё равно необходимо сканировать большие диапазоны ключей
yopp
это лучше чем сканировать большие диапазоны документов
yopp
но ставить такой ключ в префикс индекса — задушить индекс
yopp
потому что постфиксные ключи не будут добавлять никакой селективности
yopp
т.е не будут сужать выборку
yopp
но это всё равно только гипотеза, потому что всё очень сильно зависит от реального распределения индексируемых значений
Anonymous
а где можно почитать, как устроены многомерные индексы в монге? я пытаюсь периодически нагуглить, но ничего подробнее чем "ну короч b-tree "+ пара схем не могу найти
я к тому, что вряд ли там многомерные б-деревья, т.к. где-то с 3-его измерения они уже не дают выигрыша на вменяемом кол-ве данных, кажется
yopp
а где можно почитать, как устроены многомерные индексы в монге? я пытаюсь периодически нагуглить, но ничего подробнее чем "ну короч b-tree "+ пара схем не могу найти
я к тому, что вряд ли там многомерные б-деревья, т.к. где-то с 3-его измерения они уже не дают выигрыша на вменяемом кол-ве данных, кажется
в истории группы. я на пальцах уже несколько раз объяснял
Anonymous
а есть ли подробнее, чем на пальцах?
yopp
нет никакого смысла разбираться подробнее чем на пальцах
Anonymous
любопытство и только
yopp
если вам интересны архитектуры индексов, то монга не очень интересна в этом плане. есть куча хороших материалов
если вам интересна реализация в монге, то объяснение на пальцах является достаточным, потому что как именно реализован k/v в монге это являтся деталью реализации и зависит от конкретного storage engine и не имеет практического значения
Anonymous
ок, спасибо
 Nick
Nick
У вас планируется больше одного инстанса приложения?
Nick
Тогда зачем эти огороды с данными в базе? Локальная мапа клиентов-сессий и все
Nick
От соединений вы не уйдете и они жрут памяти на уровне ОС а не на уровне жавы
 pplcf
pplcf
у тебя точно новое соединение должно умирать, если старое еще не закрылось?
pplcf
обычно делают наоборот
pplcf
смерть коннекта не всегда можно вовремя поймать
pplcf
и когда клиент попытается создать новый, а ты его убьешь