unique_FunctionalId ?
да
 Viktor
Viktor


 Nick
Nick
там сразу будет наглядно понятно какие стоимости были
Viktor
эммм, вместо aggregate попробовали find ... sort ... и вуаля - индекс работает
 Gor
Gor
а в агрегате по прежнему - нет?
Gor
или после того как find дернули, уже да?
Viktor
https://gist.github.com/ahydrax/a5cde7c9f6c6a2407b41d64bc70251dd
Viktor
не понимаю чем отличается от предыдущего (кроме вложенности $and)
Gor
вложенность влияет, это первая мысль была
Gor
можешь попробовать ее в find с эмулирвать через ;фтв
Gor
$and
 Anonymous
Anonymous
драти. есть ли какая-нибудь годная подробная статья по поводу того, как делать stored procedures в современном МгоноДБ ? версии 3.+
желательно, с рассмотрением жаба-драйвера для Монго
Nick
Сторед процедурес в монго?
Nick
Где вы такое прочитали
Anonymous
я читал что на JS можно писать код и чтобы он на стороне сервера выполнялся. пусть будет stored или не stored, главное чтобы он на стороне сервера работал
Anonymous
там db.command() или что-то в этом роде
 yopp
yopp
я читал что на JS можно писать код и чтобы он на стороне сервера выполнялся. пусть будет stored или не stored, главное чтобы он на стороне сервера работал
это фундаментально неэффективная стратегия
yopp
хранимые процедуры это попытка перенести логику в хранилище, что за редкими исключениями является ошибкой проектирования
Gor
я читал что на JS можно писать код и чтобы он на стороне сервера выполнялся. пусть будет stored или не stored, главное чтобы он на стороне сервера работал
а в чем пробелма или какую задачу так пытаетесь решить?
Anonymous
тут тормозит одна шляпа в рабочем проекте и хочу переписать её на хранимую процедуру... в частности, надо чтобы результаты сортировались по дистанции в графе от определённой точки. поэтому сейчас все результаты грузятся с базы
yopp
С вероятностью 95% от этого она тормозить не перестанет
yopp
И вместо одной проблемы, у вас будет сразу три
Anonymous
это правда, но имитировать деятельность-то надо. ну не поможт - скажу "не помогло". результаты сортируются в жаба-коде когда все результаты уже загружены. а я бы сортировал их как-нибудь на стороне mongoDB
yopp
можно попробовать разобраться что именно тормозит
Gor
Gor
ну и на сколько это "тормозит"
 Bro
Bro
Хранимые процедуры это мэп редюс?
Anonymous
у всех объектов есть родитель. folder.parentId. и есть дети. folder.childrenIds. Дистанция это длина ближайшего пути, по которому можно пройти от выбираемого объекта до целевого. Ходить можно вверх по parentId либо вниз по childrenIds. Ситуация осложняется ещё и тем, что в folder есть files, и сортироваться должны они, по дистанции от целевого folder. Тут ещё разбираться и разбираться в этой куче. Я прост сразу хотел спросить про хранимые процедуры чтобы сразу с ними разбираться, а потом уж ещё покопаться в основной куче
Anonymous
ещё вопрос так ли вообще сильно нужна эта сортировка по дистанции. я думал о том чтобы предложить вообще её выкинуть
Anonymous
типа, надо найти файл - вспоминай его имя, а не надейся на дистанцию, которая вообще вряд ли поможет для чего-нибудь
Gor
Хранимые процедуры это мэп редюс?
он однопоточный. производительность никакая по сравнению если через AF делать
 little big
little big
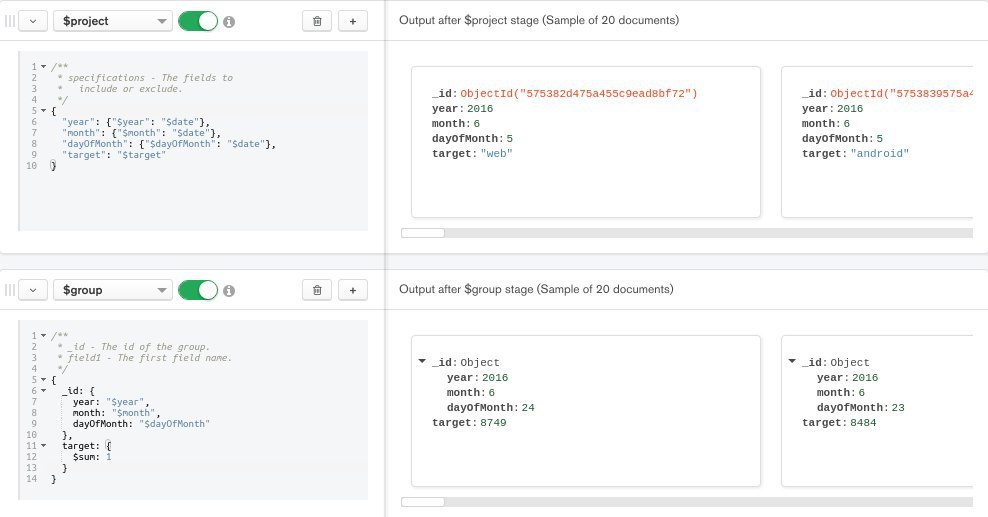
ребят, всем привет. Подскажите пожалуйста по монге. Имеется коллекция с объектами и таймстамом на каждом. Можно как-то провести агрегацию так, чтобы выдало сумму по полю объекта за определенный период времени? Куда копать?
little big
пытаюсь вытащить что-то типа timesiries
yopp
little big
$group по округленной до нужного интервала дате
а запросом по интервалам разбить как-то можно?
yopp
в смысле?
yopp
в $group внутри _id и нужно разбивать
yopp
над Date объектами можно делать математику
little big
ну в смысле, мне нужны интервалы, например, по одному дню. И сумма объектов каждого типа.
Допустим:
Из записей такого типа:
{
"date": "2016-06-05T01:42:45.105Z",
"target": "android",
"source": "unknown",
}
day1:
android: 5,
web: 3,
ios: 1
day2:
android: 7,
web: 2,
ios: 1
little big
 yopp
yopp
ну в смысле, мне нужны интервалы, например, по одному дню. И сумма объектов каждого типа.
Допустим:
Из записей такого типа:
{
"date": "2016-06-05T01:42:45.105Z",
"target": "android",
"source": "unknown",
}
day1:
android: 5,
web: 3,
ios: 1
day2:
android: 7,
web: 2,
ios: 1
https://play.db-ai.co/m/XKJJkqBXLQABKlpi
yopp
https://play.db-ai.co/m/XKJJkqBXLQABKlpi
yopp
или вот так, если надо ещё кроме даты какой-то аттрибут для группировки
little big
пасиб большое
yopp
ну и перед этим $match стейдж, чтоб отфильтровать ненужное и сузить диапазон дат
yopp
и если большие диапазоны, то быстро не будет
little big
а в чём скрытый смысл $mod: [{ "$toLong": "$date" }, 900000 ] ?
little big
ну и перед этим $match стейдж, чтоб отфильтровать ненужное и сузить диапазон дат
да нет, норм отрабатывает.
yopp
оно с ростом данных будет дерградировать
yopp
а в чём скрытый смысл $mod: [{ "$toLong": "$date" }, 900000 ] ?
ой, это я до 15 минут на автомате округлил
yopp
86400000 должно быть
yopp
1000*24*60*60
yopp
$toLong возвращает дату в миллисекундах с начала эпохи
yopp
мы делим дату на число миллисекунд в сутках и берём отстаток от деления
yopp
остаток от деления будет разницой с началом суток в дате
yopp
её и вычитаем из даты, получив начало суток
little big
пасиб. Ты крут
yopp
но если это статистика то пост-агрегация будет не самой эффективной стратегией
yopp
но всё сильно зависит от планируемого объёма данных
yopp
если никаких планов нет, то нормально
little big
но если это статистика то пост-агрегация будет не самой эффективной стратегией
это метрика, которая будет просматриваться раз в несколько недель. Так что даже пусть она секунд 10 обсчитывается, это норм
little big
прост для статистики красивый график на дашборде grafana
 Max
Max
Привет (снова)! Кто-то юзал BI (business intelligence) тулзы в связке с монгой? Если да, то какие и с каким успехом?
Gor
@dd_bb у тебя с знанием алгоритмов поиска как? KMP и прочих?
Gor
чтоб я понял что это значит...)
Gor
да не, вопрос нетривиальный. где искать или есть такой алгоритм поиска подстроки или нет))
Gor
гуглить устал
yopp
Не знаю даже такой аббревиатуры
Gor
аха, ок. блин где бы еще спросить
yopp
В бигдате
Gor
эти https://t.me/Bigdataanalyst?
yopp
t.me/bigdata_ru
Gor
ага ок
Gor
спс
yopp
Gor
да я тут на пальцах сваял простой как палка а он какого то черта эффективнее получился. сижу пытаюсь понять это что то известное или я чего то не понимаю