 Anonymous
Anonymous


мдамс трэшак
Anonymous
1 - 2 = 0 можно сделать (проверку на минимум 0), но это уже будет не атомарно по-любому, т.к это не сделаешь с $inc. или я не понимаю как
 Nick
Nick
Делайте проверку что счетчик равен предыдущему значению с которого планируется уменьшать
Nick
Проверку эту как часть фильтра указывайте
Nick
Хотя в вашей асинхронщине возможно будет тяжело это реализовать
JohnnyPitt
events = [
{
type: Borrow,
timestemp: 1412414
value: 1
},
{
type: Supply,
timestemp: 1414212
value: 2
},
]
Всем привет, может выручите и подскажете в какую сторону смотреть, если я хочу сгруппировать события по timestemp и посчтитать sum(Borrow) / sum(Supply) на интервале
 AstraSerg
AstraSerg
events = [
{
type: Borrow,
timestemp: 1412414
value: 1
},
{
type: Supply,
timestemp: 1414212
value: 2
},
]
Всем привет, может выручите и подскажете в какую сторону смотреть, если я хочу сгруппировать события по timestemp и посчтитать sum(Borrow) / sum(Supply) на интервале
Смотрите на aggregation framework
JohnnyPitt
я не совсем понимаю как в таком случае производить группировку
AstraSerg
я не совсем понимаю как в таком случае производить группировку
В каком таком? Если вы про массив, то можно unwind предварительно сделать.
JohnnyPitt
группировка идет допустим по часу, мне за этот час нужно посчитать сумму всеx событий Borrow и это я понимаю как сделать, а как прикрепить к этому интерваллу сумму по Supply и посчитать их разницу не понимаю, и что то мне кажется unwind тут не спасет
AstraSerg
А, так вам по разным таймстампам нужно? Могу предложить добавить поле «час»
JohnnyPitt
нет, таймстемпы одинаковые, но значения в интервале выситывается с двух типов событий
JohnnyPitt
вот примерный вариант
JohnnyPitt
{
$match: {
"created_on" : {
$gte: minDate,
$lt : maxDate
}
"eventType": {$in: ["Borrow, Supply"]}
}
},
{
$group: {
"_id": {
"year" : {
$year : "$created_on"
},
"dayOfYear" : {
$dayOfYear : "$created_on"
},
},
"count": {
$sum: "$value"(вот тут мне надо получить sum(Borrow)/sum(Supply)
},
}
},
Nick
В грппе считаете две суммы, потом делаете проджект и в нем вычисляете деление
JohnnyPitt
как в группе посчитать две суммы?
JohnnyPitt
для разных событий
Nick
в вашем случае чтото такое
Nick
немного извращенно конечно
JohnnyPitt
https://play.db-ai.co/m/XJkf_J_RigABpe5O
Спасибо огромное, пусть даже извращенное, но жизнь спасет)
JohnnyPitt
хотя наверное это вариант не совсем подходит, там же получается "_id": null, а у меня он должен быть сгруппированный по дате "_id": {
"year" : {
$year : "$created_on"
},
"dayOfYear" : {
$dayOfYear : "$created_on"
},
},
Nick
так а что мешает дату указать?
JohnnyPitt
ну если я добавляю группировку по дате оно не считает, или где ее нужно указать?
 yopp
yopp
4.0.7 (Mar 25) ◦ 3.6.11 (Mar 1)
• Плейграунд для запросов: https://play.db-ai.co
• Docs: https://docs.mongodb.com/manual/
• Learn MongoDB: https://university.mongodb.com
Stable: 4.0.7 (https://docs.mongodb.com/manual/release-notes/4.0/#mar-25-2019)
Bugfix: 3.6.11 (https://docs.mongodb.com/manual/release-notes/3.6/#mar-1-2019)
Legacy: 3.4.20 (https://docs.mongodb.com/manual/release-notes/3.4/#mar-13-2019, EOL June ’19)
End of life: 3.2.21 (Sep ’18), 3.0.15 (Feb ’18)
Nick
@dd_bb раз уж появился, а в плейграунде нет форматирования?
Nick
мож какая комбинация клавиш
yopp
Под форматированием что ты понимаешь?
Nick
типа жмешь кнопочку и оно все красиво выровнено отступами
yopp
Не-а. Надо?
yopp
Если надо — заведи тикет
Nick
даж не знаю на самом деле, вчера чуваку паплайн накидывал и ручками ровнял чтоб читаемо было
yopp
В принципе ето не очень сложно, надо прост представление распарсеного объекта назад в eJSON сериализовать. На бэкенде оно уже сделано для вывода результатов, а на фронтенде надо сериализатор сколхозить
Nick
ща запилю ишью, а там смотри сам
Nick
https://github.com/db-ai/playground/issues/28
Nick
и еще один вдогонку
https://github.com/db-ai/playground/issues/29
 Anton
Anton
Слушайте, а как можно ускорить лукап, который через pipeline?
{
"$match": {
"$expr": {
"$eq": [
"$parentId",
"$$tagId"
]
}
}
},
В нем вот эта конструкция капец какая медленная
 Ilya
Ilya
 Ilya
Ilya
Какая же это атамарность
yopp
Но другой поток не может увидеть частично изменённый докумен
yopp
В приведённом абзаце комментари про durability. Т.е. можно увидеть состояние документа которое потенциально может откатиться при роллбэке
yopp
Или в принципе потеряться при отказе, не помню что они под durable конкретно имеют ввиду.
Nick
Ilya
Да. Меня смутило durable и вправду.
Рагулєг🍉
@dd_bb
 Max
Max
Привет! Есть кластер в атласе 2 ядра 8 оперативы (М30). В бд-шке есть пару коллекций на 200К - 500К записей - запросы с простым find иногда отрабатывают по 15-30 секунд - при пиковых нагрузках на БД.
Это нормально или у меня руки ростут ниже чем у обычных людей?
Что можно потюнить? Стоит ли добалять оперативы/ядра (менять тип инстанса)?
 Gor
Gor
Привет! Есть кластер в атласе 2 ядра 8 оперативы (М30). В бд-шке есть пару коллекций на 200К - 500К записей - запросы с простым find иногда отрабатывают по 15-30 секунд - при пиковых нагрузках на БД.
Это нормально или у меня руки ростут ниже чем у обычных людей?
Что можно потюнить? Стоит ли добалять оперативы/ядра (менять тип инстанса)?
Смотреть в первую очередь queries статистику, может надо ключей накинуть
Max
Смотреть в первую очередь queries статистику, может надо ключей накинуть
Там достаточно индексов - буду добавлять больше - просядет врайт операции
Gor
вообще варианта 2:
- сидеть разбираться что тормозит и тюнить
- платить деньгами увеличивая конфиг и надеясь что угадал
Max
вообще варианта 2:
- сидеть разбираться что тормозит и тюнить
- платить деньгами увеличивая конфиг и надеясь что угадал
ладно, спасибо, буду пробовать
 Maksim
Maksim
!spam
Ilya
Второй нюанса по поводу Casual Consistency, который мне не понятен:)
Если чтение и запись стоит в majority и w: 1, то почему не обеспечитвается Read own writes?
Ilya
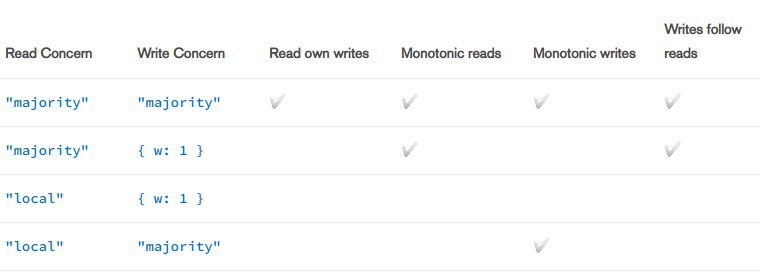 Ilya
Ilya
Если я записываю данные на primary(master) БД, то при чтнеии после записи у меня должны вернутся обновленные данные, разве нет?
Ilya
https://docs.mongodb.com/manual/core/causal-consistency-read-write-concerns/
Ilya
Ааа, я кажется понял. Пока выполняется запись на один primary узел, другой, будучи secondary, становится primary (так как предыдущий primary занят). И тут нам могут вернутся не свежие данные. Так?
yopp
Ilya
И ещё от readPreferrence зависеть будет
Да, но потом я опять не понял)
Я прочел ответ по поводу смены primary узлов здесь https://stackoverflow.com/questions/42615319/the-difference-between-majority-and-linearizable
Но не понимаю почему они вообще должны меняется. Операции ведь многопоточны, а автор ответа говорить что "пока одна primary нода занята, другие конкурируют за то, чтобы стать новой primary". Так вот мне не понятно, как это мастер нода может быть занята.
У меня предположении только если что то пошло не так и она перестала отвечать в течение какого то времени, тогда согласен, что слейвы борются чтоб стать новым мастером.
Ilya
Насчёт read preference в режиме secondary понятно, что не обеспечивается causal consistency.
yopp
Вы все правильно свели к «между запросами были выборы»
yopp
Почему были выборы — не важно
 Ilia
Ilia
Добрый день!
С монго до этого не работал, пытаюсь хоть примерно оценить ее применимость для своей задачи. Буду благодарен за соображения / критику.
Ilia
Вопрос такой: как она работает с большим количеством рандомных изменений документов?
Допустим, у меня есть порядка 100M документов, каждый примерно 10kB.
Я хочу изменить 100k таких документов, каждое изменение порядка 1kB.
На какое время записи можно (очень грубо) расчитывать. Хотя бы порядок.
Допустим это при одной железке «подходящего» размера.
yopp
это невозможно оценить
yopp
даже грубо
Ilia
ок, возможно достаточно соображений, вообще это "подходящий" для монги сценарий, или совсем противоестественный
обычно разные базы имеют разные implications в основе реализации, и исходя из них можно делать очень общие, но прикидки.
Ilia
если не противоестественный, я понятно дело буду моделировать нагрузку
если изначально стремная задача для нее — не буду тратить время
yopp
размер измнеения роли не играет, так как CoW
Nick
а обновление всех доков под одну гребенку или какждый док отдельно своими свойствами?
Ilia
Похожие по форме изменения, но данные для каждого дока свои.
Абстрагируясь от предметной области можно представить так:
Нужно из общего лога комментариев к постам раз в какое-то время обновлять документы с постами: дописывать комментарии в соответствующий список, обновлять каунтеры.
Ilia
Соответственно почти 100% изменений увеличивают размер документов.
yopp
это не важно, потому что cow
yopp
важно какой у вас запрос
yopp
если запрос будет по _id или другому уникальному индексу и не будет требовать сканировать ключи — будет быстро
yopp
если запрос будет требовать сканировать ключи, или что ещё хуже — документы, быстро не будет