 Oleg
Oleg


 倫太郎
倫太郎
Лол
Oleg
Чтож, всё равно надо бы с ним разобраться.
 Dmitriy
Dmitriy
Если для себя, то с docker-compose все заводится в 5 строк
Oleg
Если для себя, то с docker-compose все заводится в 5 строк
Та dockerfile я могу найти. Вопрос в том, как его установить, что поставить ещё..
Маfеt
Я бы попробовал разобраться с тем, что им не нравится. In-memory это очень специфичная штука с которой будет очень сложно
Кажется инмемори не подходит, тк оно в ениерпрайзе типа
Маfеt
Можно intmpfs базу сделать, но это вообще зашквар да?
Маfеt
И это. А можно в шарду добавить стендэлоун хост, а не репликусет?
 yopp
yopp
да, оно не GA
yopp
разберитесь чего хотят ваши программисты добиться
Маfеt
Ок
yopp
но не понятно зачем
Маfеt
Ну в случае инмемори вроде норм
yopp
а, стендэлон нельзя
yopp
можно добавить реплику из одной ноды
Маfеt
Спасибо. Теперь понятно все)
 Alex OXEN_SN 🇺🇦
Alex OXEN_SN 🇺🇦
 yopp
yopp
yopp
yopp
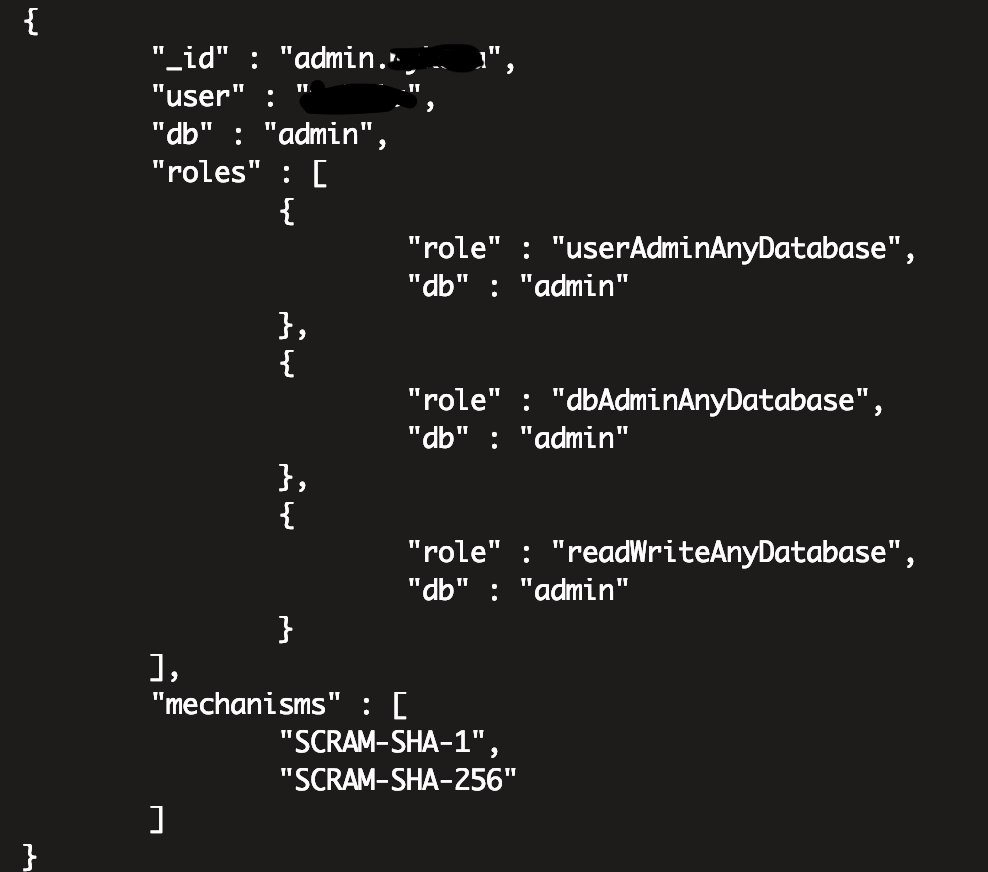
И почитайте на какую из баз надо ставить роли *anyDatabase
Alex OXEN_SN 🇺🇦
И почитайте на какую из баз надо ставить роли *anyDatabase
👍 Спасибо за подсказку
Alex OXEN_SN 🇺🇦
Странно что это работает db.currentOp( { "$ownOps": true } )
Alex OXEN_SN 🇺🇦
yopp
Странно что это работает db.currentOp( { "$ownOps": true } )
ownOps без inprog доступны
yopp
Смысл в том, чтоб нельзя было увидеть запросы других пользователей, потому что там могут быть приватные данные.
yopp
По этому currentOps доступны только с inprog. Если у вас атлас, то там они могут быть вообще не доступны на бесплатных тарифах
Маfеt
40кк документов, у каждого около 150 свойств
Надо считать count по совпадению свойств
Типа сколько профилей определенного типа с определенным параметром
Свойства иногда вложенные
Маfеt
а сколько стоит энтерпрайз с инмемори?
Маfеt
@dd_bb есть инфа?
Маfеt
порядок хоть понять о чем речь
yopp
не помню, могу врать. кажется было что-то в районе 2500-5000 долларов в год за ноду.
Маfеt
ну порядок понятен, спасибо!
yopp
а что значит по «совпадению свойств»? и как часто надо считать?
Маfеt
я так понимаю надо не часто, но быстро
Маfеt
типа есть профили пользователей в них есть пол возраст, вложенные - набор интересов пользователя к примеру
Маfеt
надо сделать быструю выборку по таким пользователям
Маfеt
но я думаю это не часто
yopp
если у вас там сотни гигабайт, у вас «быстро» упрется в какое-то из бутылочных горлышек
yopp
вероятнее всего в шину памяти
Маfеt
да, об этом тоже надо не забывать. подумаем над этим
yopp
на мой взгляд, дешевле будет подумать во что сейчас упираются запросы и может быть похимичить с индексами
yopp
подумайте чтоб купить подписку — https://db-ai.co ;) уверен что можно найти какой-то менее затратный способ решить эту задачу. не факт что in-memory сможет уложиться в нужные вам SLA. а толстый шард из in-memory может быть очень недешевым удовольствием
Маfеt
спасибо! очень ценно!
 Andrey
Andrey
40кк документов, у каждого около 150 свойств
Надо считать count по совпадению свойств
Типа сколько профилей определенного типа с определенным параметром
Свойства иногда вложенные
в сторону графовых БД не смотрели? задача сведётся к пересчёту ребер с одинаковыми весами
 Denys
Denys
Здравствуйте, у меня есть пробелмы с некоторыми символами при сортировке. Я сортирую текстовые поля с украинскими символами и некоторые символы при сортировке находяться выше А, тоесть [Є, І, А, Б...] а хотелось бы [А, Б ... Є ... І ... Я]
 Nick
Nick
Nick
Nick
Правда хз есть ли там украинский
yopp
не помню, могу врать. кажется было что-то в районе 2500-5000 долларов в год за ноду.
Вру, да. Несколько лет назад Enterprise стоил $6,500 в год, а enterprise advanced $10,000. $2500-5000 это у меня видать смешалось со стоимостью поддержки для Community: $250 в месяц за боевой и $125 за тестовый в месяц.
yopp
Сейчас похоже подорожало: MongoDB Enterprise Advanced costs $11,990 per server per year (up to 256 GB RAM per server). Для больших инсталляций есть скидка 10%
yopp
Но туда поддержка входит
yopp
http://s3.amazonaws.com/info-mongodb-com/TCO_MongoDB_vs._Oracle.pdf
yopp
Не очень дорого. :)
Маfеt
Я к сожалению не привык к таким ценам
yopp
Есть смысл начинать привыкать к эынтерпрайз ценнику. :) если у вас много данных, лицензии на всякие нужные или экономящие штуки будут находится в этих порядках. Чтоб потом когда резко понадобимся какой-нибудь SAN для бэкапов или SDN для удобства Управления сетью в стойках это не было сюрпризом.
Anonymous
Привет, сообщество! Подскажите, как лучше спроектировать: есть бд с сущностями, а теперь эти сущности будут получать мониторинг показателей из шести источников (не часто, раз в неделю, может, раз в день).
1️⃣ Я так понимаю, будут коллекции под метрики определённого типа, а там внутри потом делать запросы по идентификатору сущности + сортировка по убыванию даты с лимитом, чтоб например за год получить? Это рационально? или лучше встроить эти данные в сущности массивами?
2️⃣ Есть такая сложность, что данные приходят из сторонних ресурсов, на которые мои сущности ссылаются, то есть чтоб идентифицировать, к какой сущности пришли данные, надо будет сначала её найти. И в этой ситуации вижу два пути - либо просто аккуратно рассовывать получаемые данные по коллекциям, а когда запрашиваю сущность, то искать для её характеристик метрики по совпадению, либо при добавлении искать, кому принадлежит метрика, а потом её вытаскивать уже по идентификатору сущности. Первый способ проще, также позволит на всякий случай иметь историю по тем показателям, которые ещё не были привязаты к сущностям, но могут быть привязаты в будущем (в моем случае справедливо, что если сущности ещё нет, а метрику брать возможно, то это наша недоработка, а не нормальный случай). Второй способ потребует немного больше действия на этапе загрузки, не даст загрузить отсутствующие данные, но зато сэкономит много времени при запросе метрик для сущностей.
3️⃣ Какую схему лучше использовать для поступающи данных мониторинга?
citeria: String,
timestamp: Int,
value: Int
или
criteria: String,
metrics: [{timestamp, valie}]
Не знаю, какой лучше, второй вроде как быстрее при запросе
Буду благодарен советам.
倫太郎
а если $size убрать?
 TAB_mk 🍑
TAB_mk 🍑
$size does not accept ranges of values. To select documents based on fields with different numbers of elements, create a counter field that you increment when you add elements to a field.
https://docs.mongodb.com/manual/reference/operator/query/size/
TAB_mk 🍑
 Успішний Андрій
Успішний Андрій
Не подскажите, как через Mongoose можно получить последний документ (запись) из бд?
yopp
если у документа есть аттрибут который определяет его «последнесть», то да
yopp
если такого аттрибута нет, то может быть можно
yopp
почему «может быть», потому что в этом случае гарантий не будет. если у вас _id по-умолчанию и там ObjectId, вы в принципе можете использовать _id как аттрибут для «последнесть», отсортировав по убыванию. в случае если _id генерируется на сервере, то есть очень большой шанс что он будет в основном возрастать у документов вставленны последовательно. если _id генерируется на клиенте, то тут уже как повезёт
Успішний Андрій
Не подскажите, как через Mongoose можно получить последний документ (запись) из бд?
Всё, решил проблему.
yopp
ну и ещё есть $natural, но это работает только в standalone
Успішний Андрій
Я беру весь документ через .find() и с помощью [doc.length - 1] получаю последний элемент
yopp
это неверный способ
yopp
без явно заданной сортировки монга использует $natual для сортировки
Успішний Андрій
Возможно я неверно описал задачу: мне нужно узнать, какой _id в базе последний (_id генерируется на сервере через автоинкремент). Вот я и беру последний элемент и из него достаю _id
yopp
тем более
yopp
автоикнремент это антипатерн в монге
yopp
вероятно вы решаете несуществующую проблему «красивых ссылок»
yopp
выбор последнего значения автоинкремента через $natural тоже не верно
yopp
лучший способ — отказатся от автоинкремента
yopp
если у вас нет веских основной заменить ObjectId, то это отличный тип для _id
yopp
если вы хотите настоящий автоинкремент, то вам надо завести отдельный счётчик. если у вас монга 4+ то делать инкремент в транзакции. если у вас более старая версия, то через чтение с помощью update с $inc
yopp
т.е. у вас чтение счётчика будет его инкрементировать