не понял
что значит закрытие базы для создания тестовой базы?
Использовать лушче disconnect?
 Anonymous
Anonymous

 Kool
Kool
я использую close
Kool
обернув в промис
 AstraSerg
AstraSerg
Радужная соль joined the group
Чувствую, не долго нам в тысячниках пребывать....
Anonymous
Радужная соль joined the group
Чувствую, не долго нам в тысячниках пребывать....
Я не тот, за кого ты меня принял -_-
Anonymous
Ник - игра слов :)
AstraSerg
Я не тот, за кого ты меня принял -_-
хм... Ник неоднозначный, вас наверно много банят... :))
Anonymous
Нет, пока ещё не банили.
 Юрий
Юрий
 Anonymous
Anonymous
https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D0%B4%D1%83%D0%B6%D0%BD%D0%B0%D1%8F_%D1%82%D0%B0%D0%B1%D0%BB%D0%B8%D1%86%D0%B0
https://ru.wikipedia.org/wiki/%D0%A1%D0%BE%D0%BB%D1%8C_(%D0%BA%D1%80%D0%B8%D0%BF%D1%82%D0%BE%D0%B3%D1%80%D0%B0%D1%84%D0%B8%D1%8F)
=Радужная соль :D
AstraSerg
ах в этом смысле... а то мне одна дурь в голову лезет :(
AstraSerg
Извините
Maksim
ах в этом смысле... а то мне одна дурь в голову лезет :(
Не тебе одному. Особенности жизни в неблагополучных районах страны...
 Andrew
Andrew
извините, тоже не сдержался
 Andrey
Andrey
привет
в монге есть возможность агрегаций на лету?
 Slava
Slava
привет
в монге есть возможность агрегаций на лету?
А что вы подразумеваете под «на лету»?
Andrey
имеется коллекция иммутабельных данных, то есть документы не меняются с течением времени, рост линейный, и не логично каждый запрос проходить по всем документам
предполагается что бд умеет при вставке формировать агрегированные строки
AstraSerg
Почему " бд умеет при вставке"? Не логично ли чтобы приложение это сделало?
Andrey
как быть с консистентностью при нескольких инстансах приложения?
Andrey
считаю это логичным потому что мы по сути базе скармливаем запрос, который будет в дальнейшем выпоняться и это могло бы быть хорошей оптимизацией по скорости, конечно по памяти значительный оверхэд
Andrey
с другой стороны надо смотреть на перформанс индексов
тем не менее вопрос открыт: умеет ли такое монга?
 yopp
yopp
Есть https://docs.mongodb.com/manual/core/views/
AstraSerg
как быть с консистентностью при нескольких инстансах приложения?
Я имел ввиду, чтоб приложение сделало дополнительную запись в бд
Andrey
Я имел ввиду, чтоб приложение сделало дополнительную запись в бд
да я понял
ну давай представим нагрузка 1000 ops, есть 100 инстансов, ключ агрегации дата операции с округлением до минуты
тут или придется городить 1 точку синхронизации или через транзакции решать вопрос, но тогда боюсь что будет медленно (нужно уложиться в 100ms примерно)
AstraSerg
Я исхожу из того, что если все эти инстансы могут вставить в одну коллекцию, то и во вотрую смогут. А вторую можно ограничить по времени. Или я не правильно понял задачу...
yopp
да я понял
ну давай представим нагрузка 1000 ops, есть 100 инстансов, ключ агрегации дата операции с округлением до минуты
тут или придется городить 1 точку синхронизации или через транзакции решать вопрос, но тогда боюсь что будет медленно (нужно уложиться в 100ms примерно)
Сколько документов попадают в агрегацию? Сколько времени она сейчас занимает?
Andrey
чистых данных за минуту 60к документов, из них в худшем случае должно получиться не более 1000 агрегированных строк, в лучшем 50-100
сейчас для данной задачи использую BoltDB, вставки занимают ~ 20ms-100ms в транзакцию попадает до 500 строк
Andrey
но сейчас это реализовано через одну единую точку, что как бы неотказоустойчиво
 Nick
Nick
чистых данных за минуту 60к документов, из них в худшем случае должно получиться не более 1000 агрегированных строк, в лучшем 50-100
сейчас для данной задачи использую BoltDB, вставки занимают ~ 20ms-100ms в транзакцию попадает до 500 строк
Посмотрите на $inc, возможно на его основе сделаете агрегацию
Nick
Если правильно понял что вам надо, то нужно будет только с фильтрами для апдейта определиться, ну и может подгонять данные какнить
Andrey
это да, смотрю в это сторону, спасибо
но это выходит то же что и сейчас вручную на стороне приложения проверяю ключ, который как раз состоит из признаков prop1/prop2/prop3 и по нему тяну данные и их обновляю
Nick
это да, смотрю в это сторону, спасибо
но это выходит то же что и сейчас вручную на стороне приложения проверяю ключ, который как раз состоит из признаков prop1/prop2/prop3 и по нему тяну данные и их обновляю
Пока вы тянете то в базе все может поменяться плюс накладные расходы, два запроса вместо одного
Andrey
пока выбираются агрегации процесс не может писать
Andrey
и поскольку бакет агрегированных данных только за минуту, то чтение происходит предельно быстро, что дает возможность блокировать, остальные операции чтения не блокируют запись, поскольку читается уже из другого бакета
Nick
Если вы тянете данные в околореальном времени то всерано не пропадает чтение во время записи в одном и том же бакете
Andrey
тянуть агрегированные данные можно относительно долго (до минуты) это со всех шардов
запись данных происходит в бакет с ключем текущей минуты, там относительно немного данных (несколько тысяч), поэтому при запросе чтения мы блокируем его и далее быстро читаем и дальше пишем, и читаем предыдущие бакеты уже без блокировок, потому что в них не может идти записи, все в базе поменяться не может, писал выше данные имутабельны и всегда дополняются, поэтому меняется бакет за последнюю минуту
чтения из бакета в который пишутся сырые данные не происходит, поэтому он работает только на запись, если говорить точнее там чтение только единичных записей возможно по ключу
Andrey
сама по себе блокировка на запись во время чтения делается, потому что начинается обход по дереву, а запись делает его ребалансировку (это так для информации)
yopp
мне кажется вам нет смысла сейчас городить кеш
Andrey
кэш в виде агрегированных данных?
yopp
да, делать пре-агрегацию
yopp
на мой взгляд view или просто агрегация ваш выход
yopp
я так понимаю что у вас запись преобладает над чтениями?
Andrey
данные требуют хранить минимум 3 года, я боюсь что выборка даже за год будет медленной, хотя возможно недооцениваю индексы
с индексами же другая история, на сырые данные их не повесишь, потому что там 3 поля нужно для индексации, а вставка по времени ограничена, боюсь за ребалансировку
Andrey
я так понимаю что у вас запись преобладает над чтениями?
именно, сейчас в boltdb запись транзакционна со сбросом на диск и перебалансировкой, делать отложенную переиндексацию не дают
yopp
У вас уже есть реальные данные?
Andrey
да есть, планирую по ним пробежаться со вставками их же в монгу
Dmitry
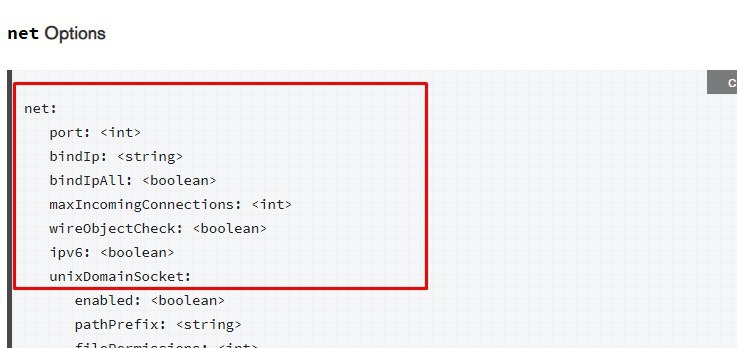
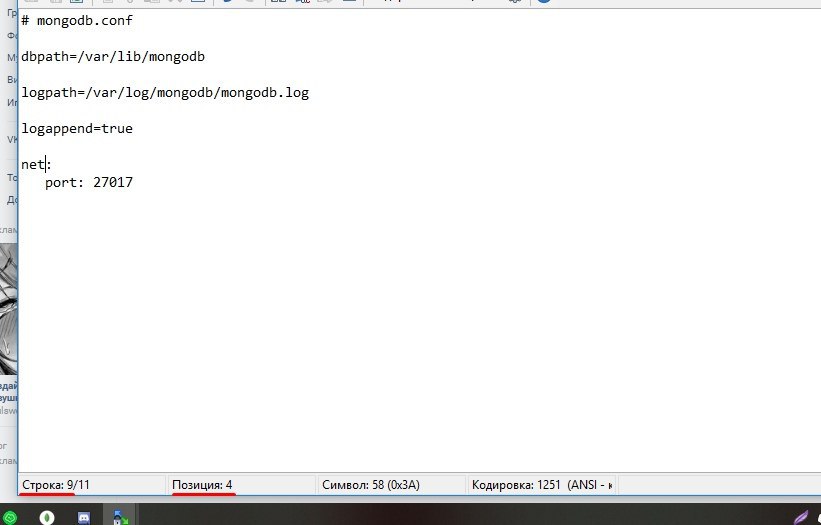
Привет, ребят, можете помочь разобраться с ошибкой в файле конфига?
Dmitry
 Dmitry
Dmitry
 Dmitry
Dmitry
 yopp
yopp
Не работал с boltdb и не понимаю проблем, которые вы озвучиваете. По этому буду рассуждать с позиции монги.
Про запись. Тысяча документов в секунду, если они в районе 1-4 килобайт, это ~1-4 мегабайта в секунду. Это не очень большое IO и даже если у вас будет десяток индексов, если у вас не виртуалка с зарезаным IO или не нагруженный другими приложениями механических сторадж. Это легко замерить, возьмите свой датасет и попробуйте его влить через mongoimport.
Про чтение. Агрегация это спосб компрессии данных. Компрессию используют когда вы уперлись в пропускную способность вашего стораджа на чтение и QoS по времени ответа не выполняется.
Монга позволяет решить этот вопрос иначе — используя шардирование. Это позволяте масштабировать как запись, так и чтение. Плюс организовать tiered хранение данных по каким-то вам нужным параметрам, например по актуальности (горячие, теплые, архив).
Про «клиент хочет данные за год». Если это происходит редко (масштабы дней-недель), то для таких ситуация идеально подходит агрегация с out во временную коллекцию. В приложении определяете что клиент хочет широкий интервал который не укладывается в online QoS, меняете стратегию со «сразу показываем результат», на «Вы заказали отчёт, будет готов через пару минут». Запускаем агрегацию, ждём завершения, уведомляем клиента.
yopp
Andrey
@yopp спасибо уже пробую
yopp
Старайтесь держать ваш сетап максимально простым, иметь статистику и прогноз по нагрузке (observability + monitoring) и дейстовать когда есть видимые проблемы. Предварительную оптимизацию стоит избегать. Ну и fail fast: проверяйте свои гипотезы максимально быстро. Соберите себе тестовый стол со срезом продакшена и 1/10 доступных в продакшене ресурсов и провеяте свои гипотезы там.
Andrey
вот у меня изначально вышел косяк с boltdb начал юзать расширение storm которое позволяет писать запросы в общем что-то типа orm к key-value и при нагрузке начались неадекватные затыки (до 3-5 сек) на виртуалках hetzner, оказалось что поля помеченые для индексации медленно вставлялись, причем под нагрузкой ситуация не проявлялась
пришлось отказаться от расширения и реализовывать вручную, взять железо
Pavel
товарищи, хотел бы спросить у вас совета. только начинаю работать с монгой, проектирую бд. у меня имеется объект, часть параметров которого может быть на разных языках (типа названия, тегов и прочей ерунды). языков может быть как много, так и мало. опыт работы с рсубд подсказывает, что надо бы языковую часть засунуть в отдельную таблицу и поставить ссылки, но в интернете везде пишут "пихайте в одну". есть какие-то советы по этому?
yopp
товарищи, хотел бы спросить у вас совета. только начинаю работать с монгой, проектирую бд. у меня имеется объект, часть параметров которого может быть на разных языках (типа названия, тегов и прочей ерунды). языков может быть как много, так и мало. опыт работы с рсубд подсказывает, что надо бы языковую часть засунуть в отдельную таблицу и поставить ссылки, но в интернете везде пишут "пихайте в одну". есть какие-то советы по этому?
http://learnmongodbthehardway.com/schema/multilanguage/
Anonymous
Там с 20 ноября намечается офф.курс по монге - как думаете, годнота?
Pavel
http://learnmongodbthehardway.com/schema/multilanguage/
спасибо за полезную ссылку. это похоже на мое, но у меня даже более простой случай. языковые объекты уникальны для объекта и не будут повторно использоваться в другом объекте. как я понимаю, в таком случае стоит объединить все-таки в один. в статье несколько раз говорится о снижении количества запросов к бд. размер самого документа, получается, не так важен и является вторичным для производительности?
yopp
Там с 20 ноября намечается офф.курс по монге - как думаете, годнота?
они постоянно идут, нормальные
yopp
спасибо за полезную ссылку. это похоже на мое, но у меня даже более простой случай. языковые объекты уникальны для объекта и не будут повторно использоваться в другом объекте. как я понимаю, в таком случае стоит объединить все-таки в один. в статье несколько раз говорится о снижении количества запросов к бд. размер самого документа, получается, не так важен и является вторичным для производительности?
оставьте переводы в том документе, которому они пренадлежат
Anonymous
они постоянно идут, нормальные
Понял. У меня указано, что регистрация с 20 ноября только возможна.
 Bro
Bro
короче $exists зло
Bro
> db.exist.find().sort({c: 1})
{ "_id" : ObjectId("5bf0e5196dbe5de6ad16ec6d"), "a" : 1, "b" : 2 }
{ "_id" : ObjectId("5bf0e5206dbe5de6ad16ec6e"), "a" : 2, "b" : 3 }
{ "_id" : ObjectId("5bf0e5256dbe5de6ad16ec6f"), "a" : 3, "b" : 4 }
{ "_id" : ObjectId("5bf0e52f6dbe5de6ad16ec70"), "a" : 5, "b" : 6, "c" : 1 }
Bro
можно так делать
Anonymous
Привет, не пинайте сапогами, если мой вопрос сильно тупой, я ненастоящий сварщик и монгу тыкаю второй день. Собственно вопрос:
есть странная трабла на 3.4.7 версии с дампами бд, делаю рестор из дампа - приложение которое работает с бд начинает "терять" данные из коллекций. типа добавил новые элемент - весь старый список пропал. Однако, если я на рабочем сервере стопаю монго и тупо копирую всю ее папку с бд и скармливаю на другой площадке - все ок работает
дампится так:
/usr/bin/mongodump --db name --archive="/dump/$(date +%Y%m%d%H%M%S).dump
восстанавливал в новый контейнер
/usr/bin/mongorestore --db name --archive=file.dump
Dmitry
Понял. У меня указано, что регистрация с 20 ноября только возможна.
буду благодарен за ссылку на годные курсы
 Сергей
Сергей
а как в монго номер заказа сформировывать?)
 Андрей
Андрей
Это скорее приложение должно делать.
Андрей
Может заблуждаюсь, конечно
Anonymous
🙈
Andrey
никто не в курсе, хочу в заббикс получать информацию по mongo cache есть готовые скрипты? Что нужно дергать чтобы выводить инфу (full,dirty,size и прочее)?