 Заур
Заур


Если в существующую коллекцию указать уникальное индексируемое поле, монга сразу начнёт её индексировать?
 Max
Max
по логике нужен индекс {date:1 , itemPrice:1}, но все проще првоеряется через explain
перепробовал все возможные комбинации, ничего не помогает(
 Nick
Nick
Если в существующую коллекцию указать уникальное индексируемое поле, монга сразу начнёт её индексировать?
прочитаю ваши мысли и думаю вы исползуете монгус, думаю стоит тогда узнать в оф. доке монгуса
Nick
перепробовал все возможные комбинации, ничего не помогает(
а что значит "не помогает"?
Nick
так это норм
Max
то есть я уперся в возможности btree?)
Nick
с чего вы решили что быудет лучше на коллекции в 100кк?
Max
влажные фантазии :)
Nick
есть еще другой момент, что по нагрузке на железо в моменты запроса?
Nick
и да сделайте explain c executionStats
 Max
Max
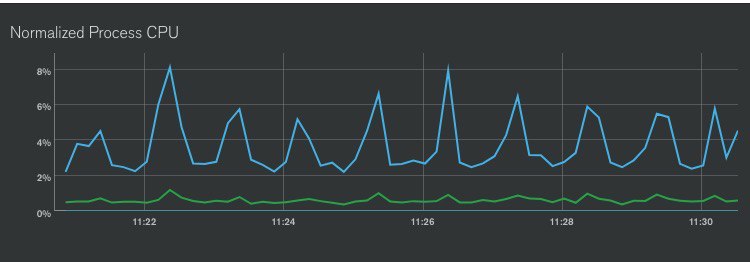
каждую минуту скачет
Max
ой, нет, не это
Max
 Max
Max
каждый час выполняется
Nick
что синее, что зеленое?
Nick
где waittime?
Max
 Nick
Nick
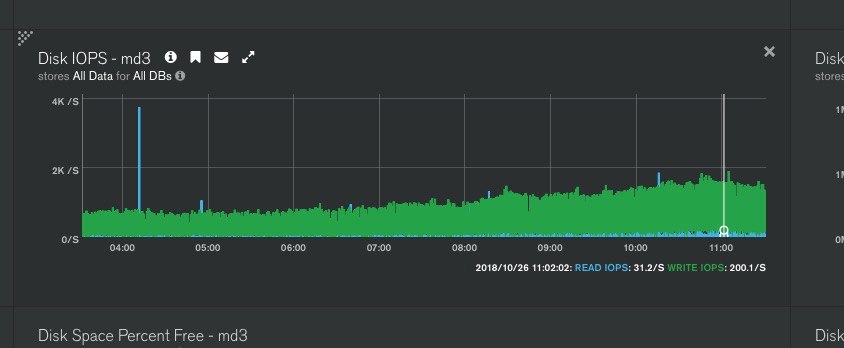
нагрузка на диски мониторится?
Max
да
Max
 Max
Max
с диском все ок, nvme raid
Max
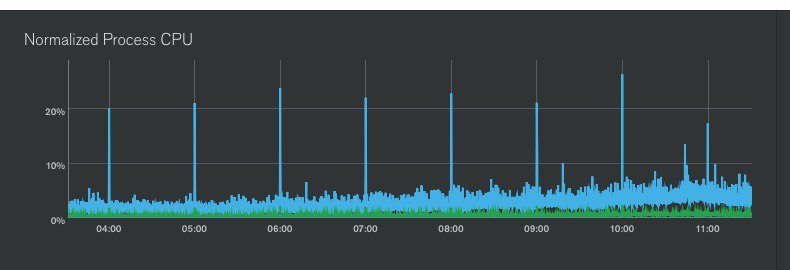
тут просто вопрос в том, что хотелось бы каждую минуту выполнять этот запрос
Max
и он очень сильно грузит cpu, нарузка возврастает в 4-5 раз
Nick
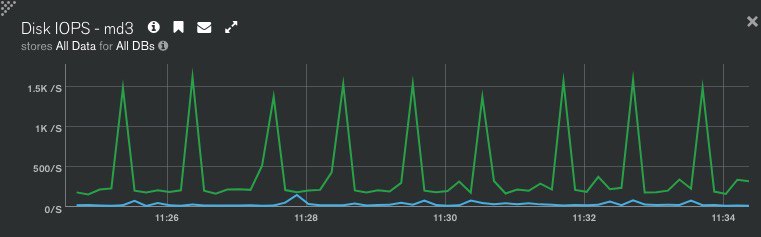
вы хотите сказат ьу вас всегда больше 500iops
Max
 Max
Max
за 10 минут
Nick
а кто вам генерит1.5крпс?
Nick
это нормально?
Max
в нашем юзкейсе это ок
Max
много данных собираем с разных источников
Max
на проц нагрузка небольшая
Max
в среднем 1/2 от одного ядра жрет
Max
чтения мало, в основном запись
Nick
ок, выполните explain и куданить на пастебин например
 yopp
yopp
Обычный IXSCAN. Я по курсору могу сделать count и он терпимо по скорости отрабатывает. Внутри unix timestamp.
Главная проблема в том, что рабочие запросы к базе не больше 300 ms должны выполняться в этот момент. А удаление сильно нагружает сервера и в диск база начинает упираться.
А что профитнее: bulkwrite удаление 1000 элементов и sleep или по одному с небольшим слипом между ними?
Bulk это сетевая оптимизация. Просто группировка запросов в один большой пакет. Мне кажется эффективные будте если вы поделите timestamp на диапазоны которые удаляются в примерно устраивающее вас время и сделаете deleteMany по этому диапазону.
Так будет открываться один курсор и сразу дропать документы. У вас сейчас получается N+1 запрос.
yopp
лучший результат — 200ms
explain({“executuonStats”:1})
Время будет зависеть от «ширины» выборки. Чем больше документов будет попадать в выборку, тем медленнее это будет.
 倫太郎
倫太郎
вопрос: можно ли во время аггрегации после unwind и всех нужных мне действий как-бы отменить unwind?
т.е. собрать все данные обратно в один документ массива?
Nick
group
Nick
И там чтонить по типа аддТуСет
倫太郎
ща гляну, спс
倫太郎
а, там немного не то
倫太郎
через него надо тогда прогонять все данные же
倫太郎
а мне сгрупировать только по одному значению посути
Nick
Укаже в качестве _id поле по которому группировать
Nick
Если вам надо вообще все по в один большой список, то в качестве _id задайте константу какуюнить
倫太郎
наверное мне больше подойдет $mergeObjects
倫太郎
хотя не
倫太郎
я не хочу все параметры прописывать :(
Nick
Давайте проще, приведите пример того что вы сейчас получаете и что нужно получить
倫太郎
 倫太郎
倫太郎
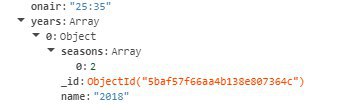 倫太郎
倫太郎
там еще массив в массиве, да
倫太郎
 Nick
Nick
А можео первую картинку более ясно сделать и желательно с форматированием
倫太郎
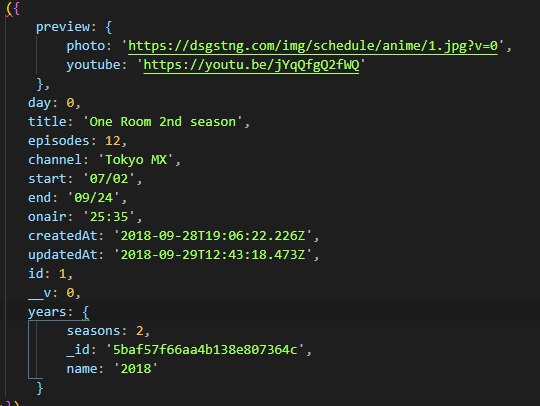 Nick
倫太郎
Nick
倫太郎
:(
倫太郎
ладно, подумаю еще как можно, спасибо
Nick
Всетаки походу до конца не догоняю, попробуйте следующую схему: первый групбай делается по тайтлу номеру эпизода и year.season
Nick
А не всеравно лажа будет с перечислением полей
yopp
если вам надо собрать документы обратно, скорее всего вы или не с той стороны к задаче проходите, либо у вас схема неподходящая
 Anonymous
Anonymous
подскажите плиз, mongod нормально стартует если вызвать его напрямую mongod —config /path/ но не хочет стартовать как сервис service mongod start
Anonymous
раньше нормально стартовал, перестал после того как запустил напрямую mongod —config /path/
 Nikolay
Max
Nikolay
Max
 Gor
Gor
народ, никому на глаза не попадался fork монги?
倫太郎
а что вы пытаетесь такой агрегацией сделать?
Ну, я так $match пытался сделать с $lookup, сначала работало, но потом потребовались все данные которые я unwind сделал
yopp
Ну, я так $match пытался сделать с $lookup, сначала работало, но потом потребовались все данные которые я unwind сделал
Я имею ввиду какую информацию вы из монги получить пытаетесь?
Maksym
Парни помогите пожалуйста правильно организовать структуру базы. Есть две сущности, сотрудник и компания. Сотрудник может принадлежать какой-то компании, а может не принадлежать. Вопрос как такую связь правильно организовать в монго, т.к. тяжело перестроиться после реляционных бд и сразу хочется создать как два отдельных документа и у сотрудника хранить ссылку на ид компании
 🖤
🖤
если у монгошелл и монги разные версии, и она кидает об этом ворнинг, может ли это быть причиной того, что авторизация не проходит?
 AstraSerg
AstraSerg
Добрый вечер. Зависит от дальнейшего использования. Можно в коллекции «пользователи» хранить компанию. Можно в коллекции «компании» хранить пользователей. Или вообще разные коллекции. Но тогда нужно будет испооьзовать lookup
https://docs.mongodb.com/manual/reference/operator/aggregation/lookup/
AstraSerg
если у монгошелл и монги разные версии, и она кидает об этом ворнинг, может ли это быть причиной того, что авторизация не проходит?
С авторизацией обычно проблемы с authenticationDatabase https://docs.mongodb.com/manual/core/authentication/
🖤
С авторизацией обычно проблемы с authenticationDatabase https://docs.mongodb.com/manual/core/authentication/
не совсем понятно, ибо пытаюсь к mlab законнектиться, и там вроде "из коробки" должно работать это.
UPD: теперь работает. видимо, нужно было время для запуска.
Maksym
Добрый вечер. Зависит от дальнейшего использования. Можно в коллекции «пользователи» хранить компанию. Можно в коллекции «компании» хранить пользователей. Или вообще разные коллекции. Но тогда нужно будет испооьзовать lookup
https://docs.mongodb.com/manual/reference/operator/aggregation/lookup/
Серж, спасибо за ответ. Дальнейшее пользование будет такое: отобразить всех пользователей, отобразить все компании, переместить пользователя в другую компанию, удалить пользователя или компанию. И что меня смущает это насколько быстро будут работать выборки по отображению всех пользователей или компаний если в монго хранить их в одном документе?
Maksym
Или например если я хочу переименовать компанию, а она у меня хранится внутри пользователя. Тогда мне нужно будет пройтись по всем пользователям и переименовать компанию, насколько быстро это будет работать при больших размерах?
Max