@ya_kostya ...монга просит, чтобы _id генерился клиентом, если его нет сгенерирует его сама Ну это меняет дело, тогда это не баг, а фича :) Да вот только, если БД сгенерила id сама, то почему бы его и не отдать в результате операции?
Потому что она работает по принципу выстрелил и забыл
 Constantin
Constantin


 yopp
yopp
Вы сейчас на 880 человек транслируете свои ошибочные рассуждения.
0) Совершенно не важно что используется как значение _id. Есть сколько ограничений накладываемых уникальным индексом. Но кроме ObjectId может использоваться всё что угодно. Это никак не влияет на гарантии.
1) Нет никакого «видения уникальности». Есть спецификация генерации OID. Да, не все реализации соблюдают спецификации. Но см. п 0
2) Нет никакой отвественности клиента за уникальность. Уникальный индекс даёт одинаковые гарантии уникальности вне зависимости от того, какое значение и где оно появилось.
3) Никаких дополнительных «технических возможностей» в кластере нет. Есть архитектурные ограничения. Например в шардированном окружении может не быть гарантии уникальности _id.
4) Вероятность коллизии никак не меняется о того где и как генерируются идентификаторы
 Gleb
Gleb
Допишу еще к предыдущему оратору. Тут вот же еще какое дело. Если генерить на стороне клиента, то timestamp в ObjectId завернется клиентский. На разных тачках время может отличаться на несколько секунд. Можно начать записывать новые документы в прошлое. И это не редкий кейс, когда нужно гарантировать порядок id-шек. Разумеется, для этих целей можно использовать дополнительные поля с серверным (монго) timestamp. Но если порядок не важен и вообще пофигу какой тип у id, то тогда можно использовать какой-нибудь UUID и без проблем генерить на клиенте. Поправьте меня, если я ошибаюсь - в монге нет кластерных индексов, поэтому UUID с эффективным распределение порядка не нужен.
если у тебя в продакшене который под твоим контролем разнове время на серверах то у меня для тебя очень плохие новости
 Юрий
Юрий
Привет! Не подскажите ли, как можно решить проблему, с ошибкой
"can't take a write lock while out of disk space"
не даёт ни удалять документы, ни апдейтить ни дропать.
только поиск работает.
админских прав к удалённому серверу нет. Наружу торчит только монга.
Юрий
Всё, справились. Но если есть способ решить это из оболочки, то поделитесь)
yopp
Всё, справились. Но если есть способ решить это из оболочки, то поделитесь)
Никак, к сожалению.
 agic
agic
добрый день коллеги, смотрите такой вопрос я делаю db.name.drop() удаляются ли также построенные индексы ?
agic
или индексы остаются?
agic
спасибо большое
Andrew
А что говорит rs.status() ?https://docs.mongodb.com/manual/reference/method/rs.status/
/ 1 / { "set" : "mongodb", "date" : ISODate("2018-08-01T14:59:30.808+03:00"), "myState" : 1, "members" : [ { "_id" : 0, "name" : "172.0.0.1:27019", "health" : 1.0, "state" : 1, "stateStr" : "PRIMARY", "uptime" : 2345125, "optime" : Timestamp(1533124770, 492), "optimeDate" : ISODate("2018-08-01T14:59:30.000+03:00"), "electionTime" : Timestamp(1530779646, 1), "electionDate" : ISODate("2018-07-05T11:34:06.000+03:00"), "configVersion" : 3, "self" : true }, { "_id" : 1, "name" : "172.0.0.2:27019", "health" : 1.0, "state" : 2, "stateStr" : "SECONDARY", "uptime" : 85714, "optime" : Timestamp(1533124769, 278), "optimeDate" : ISODate("2018-08-01T14:59:29.000+03:00"), "lastHeartbeat" : ISODate("2018-08-01T14:59:29.520+03:00"), "lastHeartbeatRecv" : ISODate("2018-08-01T14:59:29.094+03:00"), "pingMs" : 2, "syncingTo" : "172.0.0.1:27019", "configVersion" : 3 } ], "ok" : 1.0 }
Andrew
Некоторые коллекции вроде среплицировались нормально, а в одной разница на 4к документов. Несколько сот миллионов всего
Andrew
Может count() какие-то погрешности даёт, или реально на одной банке документов больше...
 Slava
Slava
Может count() какие-то погрешности даёт, или реально на одной банке документов больше...
а можешь выполнить на мастере rs.printSlaveReplicationInfo() ?
Andrew
а можешь выполнить на мастере rs.printSlaveReplicationInfo() ?
source: 172.0.0.1:27019 syncedTo: Wed Aug 01 2018 18:39:48 GMT+0300 (RTZ 2 (ceia)) 2 secs (0 hrs) behind the primary
Andrew
Да прикол в том, что коллекция с разным количеством документов сейчас не пишется, ей месяц уже
Andrew
Т.е. задержкой репликации это не объяснить
Constantin
Т.е. задержкой репликации это не объяснить
Возможно у вас было два ведущих в какой-то момент и оптлог криво среплицировался. Такое может произойти при ошибках в настройке и проблемах внутри сети, когда несколько клиентов
Constantin
Если клиент один — то это странное поведение
yopp
yopp
Попробуйте агрегацией посчитать число документов
Andrew
Думаю тоже так поступить :)
Andrew
Возможно у вас было два ведущих в какой-то момент и оптлог криво среплицировался. Такое может произойти при ошибках в настройке и проблемах внутри сети, когда несколько клиентов
Реплицировал с нуля, выставил реплицируемой ноде нулевой приоритет, чтобы мастером не стала. А в ту коллекцию вообще давно ничего не писалось. В этом плане маловероятно
 Alchemist
Alchemist
Можно ли как то сделать, чтобы в индексе expireAfterSeconds как то помягче отжирал ресурсы? После его введения просела производительность. По графикам очень выросло CPU и нагрузка на диск.
Constantin
Можно ли как то сделать, чтобы в индексе expireAfterSeconds как то помягче отжирал ресурсы? После его введения просела производительность. По графикам очень выросло CPU и нагрузка на диск.
А индекс добавлялли уже на существующую коллекцию?
Если коллекция была большая, он будет отжирать, как и любой другой индекс, на время построения, потом успокоится
Alchemist
@ya_kostya индекс был новый, коллекция большая, да, сам индекс строился два часа (нагрузку обрубали на время построения, сейчас удаляет записи под нагрузкой, и монга начала медленнее отдавать данные, в чем и проблема).
Constantin
А индекс бэкграунд или фореграунд?
Alchemist
бэкграунд
Constantin
Тогда странно, он должен был чистить по-ходу построения индекса
Constantin
Но вообще, если документов много которые нужно удалить — это нормально что растет нагрузка, особенно если на коллекции есть другие индексы
Constantin
Так как уделение и обновление может вызывать проблемы если индексов много, или они тяжелые
yopp
Можно ли как то сделать, чтобы в индексе expireAfterSeconds как то помягче отжирал ресурсы? После его введения просела производительность. По графикам очень выросло CPU и нагрузка на диск.
Каждый новый индекс требует дополнительных ресурсов на обновление.
Нагрузка выросла постоянно или пиками?
Alchemist
@dd_bb постоянно, но там много данных, которые надо вычистить. Удаляются 300-600 в минуту из 4млн записей в базе.
yopp
300-600 это не очень много
yopp
4 млн тоже не очень много
yopp
а какой поток записей/чтений?
yopp
вероятнее всего пришло время масшрабироваться
Alchemist
Эх :(
Жду железа
 antofa
antofa
Как при группировке посчитать количество всех аккаунтов + кол-во уникальных?
antofa
подвис немного
antofa
http://dpaste.com/0P0FD25
antofa
Делать еще одну проекцию после группировки?
 Yurii
Yurii
Делать еще одну проекцию после группировки?
добавить ещё одну группировку,
где
_id: null,
unique: {$sum: 1},
all: {$push: "$all"},
а потом проекцию, где посчитать сумму all...
Возможно, можно проще 💁♂️
antofa
account_ids: { $addToSet: '$account_id' } - делаю пока так. А можно ли еще null значения пропускать?
antofa
http://dpaste.com/1BBWB91
 Denis
Denis
Приветствую! Подскажите, как правильно переименовать пользователей баз данных в монге?
 SvPupok
SvPupok
Приветствую! Подскажите, как правильно переименовать пользователей баз данных в монге?
В смысле, правильно переименовать? Вас синтаксис команды интересует?
SvPupok
Попробуйте так :
db.system.users.update({"user":"oldname"}, {$set:{"user":"newname"}})
Denis
В смысле, правильно переименовать? Вас синтаксис команды интересует?
Читал доки, но так и не понял как это сделать правильно.
Denis
Попробуйте так :
db.system.users.update({"user":"oldname"}, {$set:{"user":"newname"}})
Я правильно понимаю, что это будет работать так
Перехожу в нужную БД: use mydatabase
Далее db.system.users.update({"user":"oldname"}, {$set:{"user":"newname"}})
SvPupok
Сейчас до рабочего места доберусь, попробую прям с примером сделать
Denis
Сейчас до рабочего места доберусь, попробую прям с примером сделать
Спасибо! Я пробовал так делать вчера, но помоему ничего не сработало. Заранее извиняюсь, я просто /dev/null в монге)
Danila
Здравствуйте. Можно ли сделать горизонтальное масштабирование MongoDB таким образом:
Есть 2 хоста, на каждом из них создан Docker контейнер с MongoDB.
К каждому контейнеру в директорию с БД примонтирована CephFS.
Slava
Здравствуйте. Можно ли сделать горизонтальное масштабирование MongoDB таким образом:
Есть 2 хоста, на каждом из них создан Docker контейнер с MongoDB.
К каждому контейнеру в директорию с БД примонтирована CephFS.
скажите, а директория одна и так же примонтирована ?
Slava
думаю что нет, монга ведь умеет в шардирование оно не подходит вам?
SvPupok
думаю что нет, монга ведь умеет в шардирование оно не подходит вам?
поддерживаю мнение предыдущего оратора. Не проще решить проблему стандартными средствами mongo?
 Anton
Anton
Здравствуйте. Есть проблема, осваиваю транзакции в mongoose 5.2.6 и наткнулся на ошибку "Transaction numbers are only allowed on storage engines that support document-level locking". Сама база на mlab-е. Подскажите пожалуйста в какую сторону копать? Код использовал из мануала по mongoose
Mira
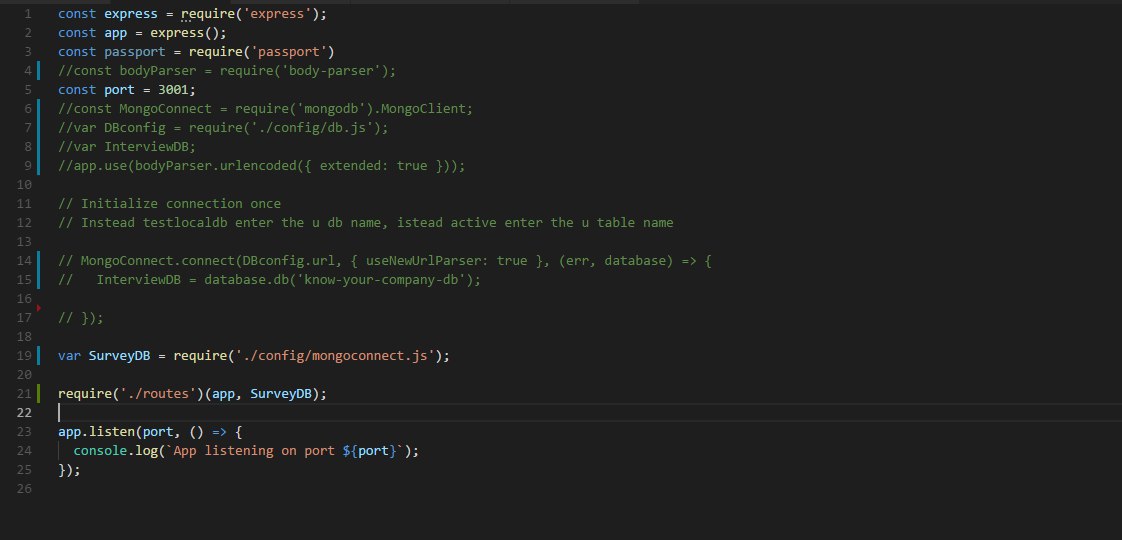
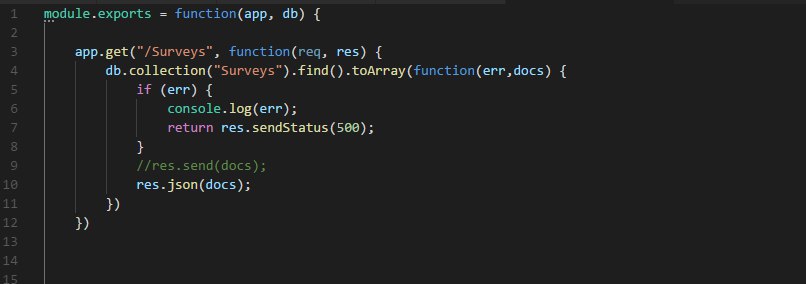
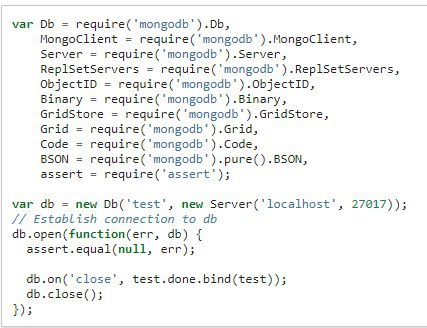
Добрый день, может знает кто, как правильно передавать полученную бд?
Сделал отдельный модуль для подключения (до этого всё было в server.js и работало)
1ое - server.js
2ое - запрос
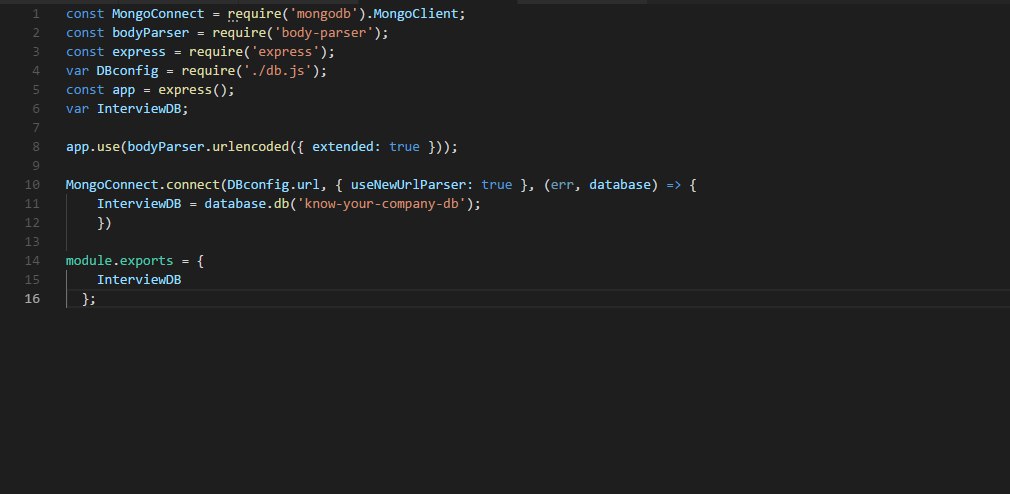
3ие - mongoconnect.js
Mira
 Mira
Mira
 Mira
Mira
 Mira
Mira
Пишет ошибку, при попытке обращения к db.collection (на 3 скрине)
ошибка db.collection is not a function
Anton
А db он точно нашёл при подключении?
Mira
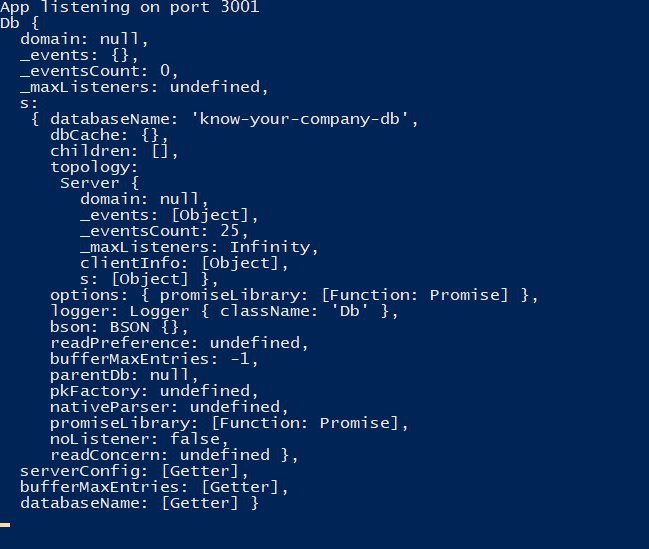
Да, урл тот же
Mira
 Mira
Mira
Как я понял, вне метода connect он её не видит, т.е. инициализация идёт только внутри метода .connect()
Но я хз тогда как правильно вынести это в отдельный метод
 Михаил Макарычев
Mira
Михаил Макарычев
Mira
Вам в @nodejs_ru. И вы неправильно понимаете асинхронность в ноде
Спасибо за ответ, с данного момента немного разобрался и всё работает :)
Михаил Макарычев
Спасибо за ответ, с данного момента немного разобрался и всё работает :)
 Mira
Denis
Mira
Denis
Подскажите, плес. Делаю дамп базы данных при помощи mongodump с флагом —dumpDbUsersAndRoles
Делаю restore на другой инстанс с монгой, в итоге захожу в БД, смотрю юзеров и там все пусто. Как правильно востановить на другом инстансе всех юзеров и роли?
Denis
Я правильно понимаю что инфа по всем юзером и ролям лежит в файле $admin.system.users.bson ?
yopp
Подскажите, плес. Делаю дамп базы данных при помощи mongodump с флагом —dumpDbUsersAndRoles
Делаю restore на другой инстанс с монгой, в итоге захожу в БД, смотрю юзеров и там все пусто. Как правильно востановить на другом инстансе всех юзеров и роли?
Необходимо использовать этот флаг и при восстановлении: https://docs.mongodb.com/manual/reference/program/mongorestore/#cmdoption-mongorestore-restoredbusersandroles
yopp
https://docs.mongodb.com/manual/reference/operator/aggregation/sum/
yopp
Здравствуйте. Можно ли сделать горизонтальное масштабирование MongoDB таким образом:
Есть 2 хоста, на каждом из них создан Docker контейнер с MongoDB.
К каждому контейнеру в директорию с БД примонтирована CephFS.
1) Это не будет горизонтальным масштабированием. Репликация это скорее HA & FT.
2) Не используйте сетевые файловые системы. Монга очень чувствительна к задержкам.
Для горизонтального масштабирования вам уже посоветовали шардирование. Но это потребует существенно больше ресурсов