 Oleg
Oleg


в принципе можно попробовать ранчер, он для старта попонятнее чем кибернетс
 V
V
есть время\ресурсы потратить пару недель?
да есть впринципе. но я хотел больше опыт услышать, мол держим терабайты монги в докере в kuber полет нормальный
Oleg
может здесь есть народ с терабайтами :)
Oleg
у меня просто немного другой стек
и данные не основной продукт
микросервисы и парочку крупных приложений в купе с дб
V
кстати кто знает про драйвера, как быстро они понимают что мастер поменялся?
 yopp
yopp
Контейнеризация подразумевает stateless приложения. А базы данных statefull и с высокими требованиями к скорости и пропускной способности файловой системы.
Вторая проблема: failover и scalability. Так как шедулер контейнеров обычно ничего про состояние приложения не знает, он может начать совершать действия которые приведут к отказу кластера.
yopp
Или что хуже — к потере данных.
yopp
Могу дать два совета: не использовать шедулеры для контейнеров с базой данный и не использовать виртуальных или сетевых файловых систем, особенно если они поддерживают миграцию томов между контейнерами.
Не слежу за последними наработками в этой области, может быть что-то изменилось.
yopp
Я пытался несколько лет назад ранчеровский cattle с монгой подружить — не смог.
yopp
Результат всегда был примерно один: шедулер тем или иным образом вместо работающие реплики деплоил пустую.
yopp
кстати кто знает про драйвера, как быстро они понимают что мастер поменялся?
Близко к сетевым задержкам.
yopp
Реально весь процесс выборов займёт несколько секунд, после чего все клиенты закроют соединения и откроют их снова. Переключения без даунтайма кажется всё ещё не завезли.
V
Реально весь процесс выборов займёт несколько секунд, после чего все клиенты закроют соединения и откроют их снова. Переключения без даунтайма кажется всё ещё не завезли.
не знаю не знаю) я сегодня для теста положил ровно 90% нод оставил одну и арбитр, все кричали
yopp
Вы говорите загадками
yopp
Кто «все» и что «кричали»?
V
Кто «все» и что «кричали»?
что всё не работает.
@dd_bb пока конечно надо изучать логику работы драйвера.
yopp
Если вы будете говорить не загадками и абстракциями, а конкретными фактами, возможно, вам тут помогут. Иначе 🤷🏻♀️
 Nick
Nick
не знаю не знаю) я сегодня для теста положил ровно 90% нод оставил одну и арбитр, все кричали
нельзя сразу класть 90%. Допустимо за один раз положить не больше (N/2)-1, т.е. должно остаться большинство
V
Nick
потому что никто не дает гарантий о рабоспособности кластера если помирает нод больше чем простое большинство
Nick
есть такая проблема split brain и она ограничивает допустимое количество мгновенно умирающих нод
V
потому что никто не дает гарантий о рабоспособности кластера если помирает нод больше чем простое большинство
ну сплит бренй был исключён осталась ведь одна нода, она была slave.
Nick
@dd_bb кстати а монга переживет если убивать по одной ноде после каждый выборов?
Nick
ну сплит бренй был исключён осталась ведь одна нода, она была slave.
да, она слейв и поэтому кластер развалится
Nick
потому что у нее прописано что их было больше двух
V
я пологал что такое поведение должно быть, выбрать себя мастером а драйвер сам найдёт её потом
Nick
произведите реконфиг убрав лишние реплики и она станет мастером
Nick
эм
Nick
как вы настраиваете репликасет?
Nick
сколько реплик в репликасете?
Nick
тогда как вы 90% положили?
Nick
т.е. вы погасили 2 ноды из трех
V
да, я ожидал что вообще всё прозрачно пройдёт, или с минимальными потерями.
V
т.е. вы погасили 2 ноды из трех
хотя пока данных точных все равно нет, буду уже на днях больше тестов делать
Nick
N нод в реплика сете позволяют пережить падение (N-1)/2 нод
Nick
никакой магии
yopp
@dd_bb кстати а монга переживет если убивать по одной ноде после каждый выборов?
Если не ошибаюсь, то топология из rs.config берётся. Не помню про алгоритм расчета большинства, искать некогда. Скорее всего либо в репозитории спецификации монги, либо в wiki соснового репозитория описана логика
 Миша
Миша
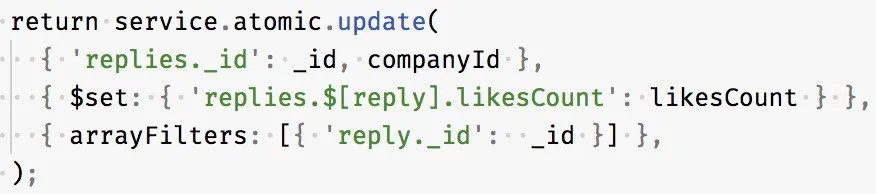 Миша
Миша

 Сергей
Сергей
Привет всем)
Есть вопрос, может кто-то сможет подсказать)
Использую mongoose, хочу решить задачу.
Есть коллекция posts.
У каждого поста есть поле comments.
А сами комментарии лежат в отдельной коллекции comments.
Как сделать так, чтобы при запросе post, в него сразу подтягивались комментарии?
Виртуальным полем не получается, потому что его нельзя сделать асинхронным.
Какие еще есть варианты?
 Artur
Сергей
Artur
Сергей
Я забыл написать про то, что я не хочу это в каждом контроллере писать) Хочу описать один раз в модели, чтобы оно постоянно подтягивалось, как внутреннее поле
V
ребят подскажите а есть ли какой то интсрумент чтобы сделать версионость документа
чтобы можно было откатиться назад
V
или на какую то версию
 Serhii
Serhii
запустил express+mongodb через pm2 и теперь постоянно перезапускает сервер:
Change detected on path db/diagnostic.data/metrics.interim for app app - restarting
PM2 | Stopping app:app id:0
PM2 | App [app] with id [0] and pid [11760], exited with code [0] via signal [SIGINT]
PM2 | pid=11760 msg=process killed
PM2 | Starting execution sequence in -fork mode- for app name:app id:0
PM2 | App name:app id:0 online
Serhii
что за файл? как можно остановить рестарт?
Serhii
не смог ничего найти по этому файлу metrics.interim
Сергей
что за файл? как можно остановить рестарт?
а папка с базой у тебя не лежит в папке с проектом?
Serhii
Да
 SvPupok
SvPupok
что за файл? как можно остановить рестарт?
насколько я помню это папка diagnostic.data куда пишется диагностическая информация конкретного инстанса. можно отключить сбор диагностики, стартовав mongod с параметром setParameter:
diagnosticDataCollectionEnabled: false
SvPupok
а вы не могли бы привести версию MongoDB, и какой движок используете?
 p
p
всем привет!
В коллекции у каждого документа есть массив объектов с еще одним массивом. Нужно все элементы последнего массива обновить - взять два поля и вычислить третье. Как это лучше сделать?
 Nickolay
Nickolay
всем привет!
В коллекции у каждого документа есть массив объектов с еще одним массивом. Нужно все элементы последнего массива обновить - взять два поля и вычислить третье. Как это лучше сделать?
если вычислить, то на бэкенде своем, если одним запросом, то через агрегацию
p
если вычислить, то на бэкенде своем, если одним запросом, то через агрегацию
все вычисления внутри одного элемента, агрегация тут не поможет, если я правильно понял.
сейчас сделал find() по коллекции и два цикла foreach по результатам запроса
 Alexandr
Alexandr
ребят, что-то не въезжаю, мне нужно из вложеного массива сделать выборку элементов, которые были добавлены за последние 24 часа (поле time есть), как мне это сделать?
Alexandr
проблема в том что он мне выдает все вложенные документы, если есть записи за последние 24 часа, а мне нужны только документы за 24 часа
 Nan0
Nan0
ребят, а m0 tier cluster можно только с помощью replica set развернуть, правильно?
Nan0
вот читаю "You cannot deploy a M0 Free Tier or M2/M5 shared cluster as a Sharded Cluster."
https://docs.atlas.mongodb.com/reference/free-shared-limitations/#atlas-free-tier, это значит, что я могу деплоить только с помощью реплик?
 Ivanov
Ivanov
Привет. Подскажите в mongo
Делаю group выполняется быстро
Делаю lookup который пару полей лепит к документу выполяется быстро
Делаю lookup + group - выполняется в 100 раз дольше
Куда копнуть?
 Ruslan
Ruslan
Привет. Подскажите в mongo
Делаю group выполняется быстро
Делаю lookup который пару полей лепит к документу выполяется быстро
Делаю lookup + group - выполняется в 100 раз дольше
Куда копнуть?
Попробуй после lookup своего поля unwind, а потом group
Ivanov
Вроде точно так же работает, время выборки не изменилось
Ivanov
db.clients_data_info.aggregate( [
{ "$lookup" : { "from" : "inn2markets" , "localField" : "inn" , "foreignField" : "inn" , "as" : "inn2markets"}} ,
{ "$group" : { "_id" : "$clientId" , "clientDataInfos" : { "$push" : "$$ROOT"}}}
]
)
db.clients_data_info.aggregate( [
{ "$lookup" : { "from" : "inn2markets" , "localField" : "inn" , "foreignField" : "inn" , "as" : "inn2markets"}} ,
{ "$unwind": "$inn2markets"},
{ "$group" : { "_id" : "$clientId" , "clientDataInfos" : { "$push" : "$$ROOT"}}}
]
)
Ivanov
Структура там такая
clients_data_info
_id
name
inn
clientId
Нам надо по inn из другой таблицы цепануть информацию о магазине (наименование)
Ivanov
И потом сгруппировать их по clientId
Ivanov
Вот так вот
db.clients_data_info.aggregate( [
{ "$lookup" : { "from" : "inn2markets" , "localField" : "inn" , "foreignField" : "inn" , "as" : "inn2markets"}} ,
]
)
0.002 с выполняется
db.clients_data_info.aggregate( [
{ "$group" : { "_id" : "$clientId" , "clientDataInfos" : { "$push" : "$$ROOT"}}}
]
)
0.337 с
db.clients_data_info.aggregate( [
{ "$lookup" : { "from" : "inn2markets" , "localField" : "inn" , "foreignField" : "inn" , "as" : "inn2markets"}} ,
{ "$group" : { "_id" : "$clientId" , "clientDataInfos" : { "$push" : "$$ROOT"}}}
]
)
а вот так 9 секунд
Nick
а вы берете время до поулчения первого элемента или время полной вычитки всех данных из ответа? сдается мне что вы замеряете время получения курсора, а оно никак не корреклирует с выборкой. а в случае с думя стейджами у вас идет как раз полный проход по данным на стороне базы до момента когда вам вернули курсор. так что начинайте мерить время от начала запроса вычитки абсолютно всех данных из курсора
Nick
тогда увидите что время на самом деле +- одинаковое
Ivanov
Я мерю по тому что показывает Robot 3T.
Ivanov
На самом деле конечный запрос еще огромнее, и выполняется в боевой среди 90секунд
Ivanov
надо сократить до 2-3с
Nick
начните с експлейнов
Nick
если вам нао быстро - перестраивайте данные, делайте преагрегаты