 Ruslan
Ruslan


помогите пожалуйста
Ruslan
я хочу чтобы монго возвращала результат, где {'body: ''}
но она мне возвращает
> db.articles.find({'body': ''}).limit(1)
{
"_id" : ObjectId("5a5e0127040702033857efb7"),
"url" : "https://www.bloomberg.com/gadfly/articles/2018-01-16/can-hedge-funds-handle-a-bitcoin-bust",
"type" : "bloomberg",
"query" : "bitcoin",
"article" : "DATA CHECK: 2018-01-16, func_name: get_aricles",
"body" : [
"Hedge fund managers have been lying awake at night for years worrying about poor performance, weak volatility and whether it might be time to just move on and do something else -- like get into Bitcoin maybe.",""
],
"title" : "Can Hedge Funds Handle a Bitcoin Bust?",
"date" : ISODate("2018-01-16T00:00:00Z"),
"latest_check" : "DATA CHECK: 2018-01-17"
}
 Arthur
Arthur
Всем привет! Подскажите пожалуйста как остортировать документы в коллекции по двум полям сразу?
 Zloy-Dobry
Zloy-Dobry
aggregate, $group
Zloy-Dobry
Наверное. Хотя, как поставлен вопрос, так и получен ответ, тамщемта. Возможно стоит воспользоваться $match в том же aggregate
Arthur
 Zloy-Dobry
Zloy-Dobry
Да ну опять же.
Zloy-Dobry
Модно зато
Zloy-Dobry
Ну да ладно, продолжайти
Arthur
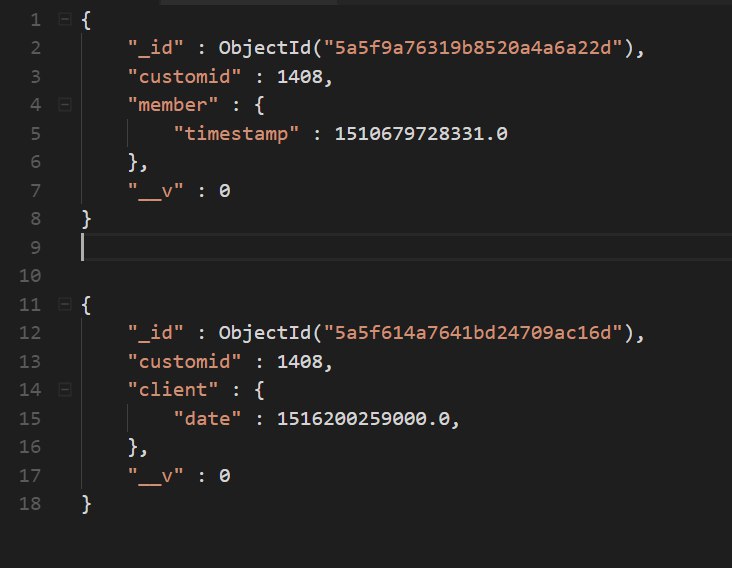
если делать db.coll.find({customid: 1408}).sort({member.timestamp: 1, client.date: 1});
то сначала выводяться все отсортированные документы с member.timestamp , а потом client.date отсортированные
а надо чтобы они вместе сортировались ))
 Ivan
Ivan
А что если у элемента две даты, то как сортировка будет? Если извращаться, то смотри в сторону pipeline, а на деле неправильно хранишь данные, вот и задача дурацкая
Arthur
А что если у элемента две даты, то как сортировка будет? Если извращаться, то смотри в сторону pipeline, а на деле неправильно хранишь данные, вот и задача дурацкая
две даты не может быть
но спасибо за ответ
 Nick
Nick
если делать db.coll.find({customid: 1408}).sort({member.timestamp: 1, client.date: 1});
то сначала выводяться все отсортированные документы с member.timestamp , а потом client.date отсортированные
а надо чтобы они вместе сортировались ))
если я правильно понял, то вам нужно, чтобы member.timestamp и client.date у разных документов сравнивались между собой и выстраивались в общий ряд, но для разных поле это сделать невозможно. сортировка которую вы использовали работает корректно, т.к. это сортировка сначала по одному полю, потом по второму.
а то что вам нужно потребует изменения формата данных либо использования агрегаций, где вы будете оба поля мапить в новое, уже по которому будете производить сортировку
Arthur
если я правильно понял, то вам нужно, чтобы member.timestamp и client.date у разных документов сравнивались между собой и выстраивались в общий ряд, но для разных поле это сделать невозможно. сортировка которую вы использовали работает корректно, т.к. это сортировка сначала по одному полю, потом по второму.
а то что вам нужно потребует изменения формата данных либо использования агрегаций, где вы будете оба поля мапить в новое, уже по которому будете производить сортировку
понятно
спасибо за ответ, буду делать как Вы и сказали " ...оба поля мапить в новое..."
Nick
но лучше всетаки пересмотреть структутуру данных пока не поздно, обычно такие проблемы - это первые звоночки, что данные не подходят под запросы
Nick
например просто вынести дату на верхний уровень документа и обозвать updatedTime, если это оба время про время создания или последнего изменения, и жизнь сразу улучшиться
Nick
и еще я вижу у вас две разные сущности в одной коллекции, если допустимо, то общее нужно вынести на врехний уровень документа и добавить флаг client/member, позволит строить нормальные индексы
Arthur
согласен, спасибо за помощь!надо будет както изменить данные которые уже есть...
Anonymous
парни, тут пытаюсь подключиться к mongodb atlas
он спрашивает у меня версию драйвера - выше 3.6 или ниже 3.4
а как мне узнать мою версию драйвера, чтобы подсунуть ему?
 SvPupok
SvPupok
коллеги, а не подскажете, можно ли питоновским скриптом вытащить db.getReplicationInfo()? pymongo вообще позволяет это?
Anonymous
 SvPupok
SvPupok
хм, насколько я понял это просто вызов команды монги из питона. Поясню ситуацию, у меня есть 3 кластера, в каждом 10-12 репликасетов, в каждом репликасете 4 ноды (3+архивная, с отставанием на час). Время от времени случаются ситуации, когда из за интенсивной записи, архивные ноды отваливаются в recovering, потому как не хватает размера оплога. на наиболее критичных репликасетах мы выкрутили оплог до максимума, что в общем то исправило ситуацию. К остальному хозяйству, я хочу прикрутить мониторящий скрипт, который покажет размер оплога, время на которое его хватает, для каждой из нод кластера.
 Dmitry
Dmitry
Ребят, привет. Я фронтендер, в серверной разработке новичок.
В чём вопрос:
Есть костяк сайта, сервер на node.js, фронт на vue.js, бд монго. Локально CRUD в монго работает, на удалённом сервере (у меня linode 1gb) появляется ошибка: "net::ERR_CONNECTION_REFUSED"
Как настроить права доступа для приложения?
Ubuntu 16.04
Прокси nginx
 yopp
yopp
это не команда, это метод в js для шелла
yopp
SvPupok
Я пошел немного другим путем. Дернул в питоне оплог как коллекцию, и размер вытащил из статов. А время думаю рассчитать как разницу между последней и первой записью коллекции
yopp
не надо думать
yopp
можно просто исходник метода в шелле посмотреть
yopp
просто убрав скобки
yopp
но так да, логика верная
yopp
https://github.com/db-ai/mongo_collection_exporter/blob/master/app/models/exporter/collector/op_log.rb
yopp
а зачем оно надо?
yopp
Ребят, привет. Я фронтендер, в серверной разработке новичок.
В чём вопрос:
Есть костяк сайта, сервер на node.js, фронт на vue.js, бд монго. Локально CRUD в монго работает, на удалённом сервере (у меня linode 1gb) появляется ошибка: "net::ERR_CONNECTION_REFUSED"
Как настроить права доступа для приложения?
Ubuntu 16.04
Прокси nginx
продуктивнее всего в @ru_devops спросить
SvPupok
а зачем оно надо?
Ну просто интенсивность записи в шардированный кластер видимо настолько велика, что у нас пару раз была ситуация, когда оплога в 10 гигов, в репликасетах кластера хватало всего на 5-10 минут. Из за этого отваливались бэкапные ноды, которые по задумке архитектора должны были отставать на час от мастеров. Поэтому я для собственного удобства понимания картины происходящего с кластером, пытаюсь скриптами вытащить данные по состоянию репликасетов.
yopp
разверни mongo_collection_exporter
yopp
prometheus + grafrana + экспортер
yopp
там даже готовые дешборды есть,
yopp
но вообще надо просто увеличить размер оплога
SvPupok
Не поверишь, так и делаю.
yopp
а зачем бекапные ноды отстают?
yopp
вы же знаете что ваши бекапы сломанные, если это в шардед кластере?
yopp
Sharding
In sharded clusters, delayed members have limited utility when the balancer is enabled. Because delayed members replicate chunk migrations with a delay, the state of delayed members in a sharded cluster are not useful for recovering to a previous state of the sharded cluster if any migrations occur during the delay window.
yopp
https://docs.mongodb.com/manual/core/replica-set-delayed-member/#sharding
SvPupok
мин, ща за нормальную клаву пересяду.
SvPupok
а зачем бекапные ноды отстают?
идея была в следующем, отставание бэкапных нод сделано было для того что бы можно было вытащить по горячим следам удаленные документы, в течении часа. Балансировка происходит ночью, в течении семичасового окна, а в дневное рабочее время можно было бы воспользоваться в случае необходимости быстрого восстановления, отстающими нодами
SvPupok
но сейчас, я практически везде делей убрал
yopp
вообще делейд ноды в шрадед кластере это очень кривая забава, такие гипотезы надо проверять на копии боевых данных и желательно симулиря боевые нагрузочные условия
yopp
так как например два часа с момента запуска балансировки уже выпадают
yopp
делать бекапы с этих нод надо очень аккуратно и есть очень высокая вероятность получить неконсистентные бекапы которые потом в бой будет очень дорого выкатить.
yopp
вообще бекапить шардед кластер сложновато
SvPupok
вообще делейд ноды в шрадед кластере это очень кривая забава, такие гипотезы надо проверять на копии боевых данных и желательно симулиря боевые нагрузочные условия
я это понимаю. поэтому отставание я отключил. с бэкап нод просто происходит ежесуточный бэкап базы, скриптом останавливается запись в базу, и датафайлы сливаются в хранилище.
yopp
по плейбуку из доки, с маркерами?
SvPupok
не запись, путаюсь в терминах, репликация.
yopp
если это не по плейбуку сделано, то надо изучить плейбук и переделать как там написано
yopp
дожидаться завершения репликации до маркера нодами с которых снимается снепшот, не забывать тоже самое делать в CSRS
yopp
убеждаться что балансер и выключен и не активен
SvPupok
если это не по плейбуку сделано, то надо изучить плейбук и переделать как там написано
а не трудно ссылку кинуть на плейбук?
yopp
под большой нагрузкой выключение балансера != завершению работы балансера
yopp
https://docs.mongodb.com/manual/tutorial/backup-sharded-cluster-with-filesystem-snapshots/
yopp
И да, вот это:
IMPORTANT
To capture a point-in-time backup from a sharded cluster you must stop all writes to the cluster. On a running production system, you can only capture an approximation of point-in-time snapshot.
yopp
Всё ещё актуально
SvPupok
yopp
ну вот тогда надо сделать risk assesment вашего бекапа
yopp
но вообще, большой и жырный кластер в большинстве случаев нужно логически поделить по ценности и критичности для бизнеса и не бекапить всё
yopp
скорее всего окажется что реально кричных данных пару сотен гигов, а всё остальное можно не бекапить, а просто хорошенько резирвировать
yopp
а что у вас там с такими размерами, что оплога хватает на 5-10 минут?
yopp
gridfs?
yopp
или что-то с высокой частотой обновления?
yopp
RTB там какой
eshch
блин, нереально. нам никто не даст остановить запись
а я говорил что надо делать the world для бэкапа
eshch
stop the world
Alexander
парни, а в mongoose можно в схеме определить тип массив и чтобы допустимые значения были ограничены данными из массива?
Alexander
о! или валидатор проще прикрутить?
 Igor
Igor
У меня очень интересный вопрос. Как Монго воспринимает пустую строку в отношении занятого места?
Что "экономнее" хранить, пустую строку типа '' или null ?
Igor
Этот вопрос родился когда я увидел что база в SQL занимает 130 кб, а в Монго 6 мегабайт. Пустые строки есть и их прилично, вот и подумал
Alexander
NULL - 1 байт
"" = 2 байта
Igor
NULL - 1 байт
"" = 2 байта
но не может же быть такая разница. Одни и теже данные в MySql занимают в разы меньше
Alexander
https://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GSQL_langelements_null