как в телеграме увидеть mentions ко мне? мне тут кидали ссылочку на курс по mondo. не могу найти в этом полотне теперь
Аватарка группы - shared media - links
 yopp
yopp


 Anonymous
Anonymous
ссылку не нашел ))
Anonymous
Ниже глянь
не совсем. была еще ссылка на Udemy с курсом по MongoDB
может ошибаюсь, что здесь - но была такая точно, видел
yopp
Не тут
Anonymous
да, значит не тут
 Mykola
Mykola

 Ilya
Ilya
не очень понятно что ты хочешь сделать
Ilya
если ты хочешь ограничить данные возвращаемые монгой то синтаксис совсем другой
Ilya
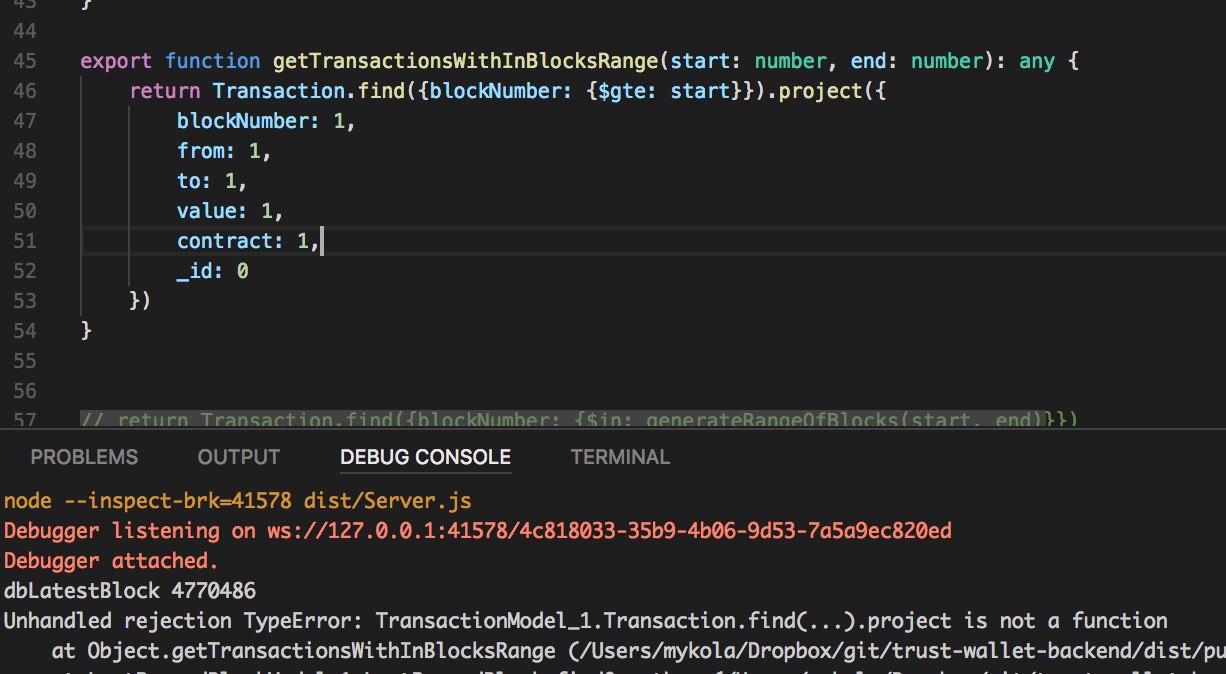
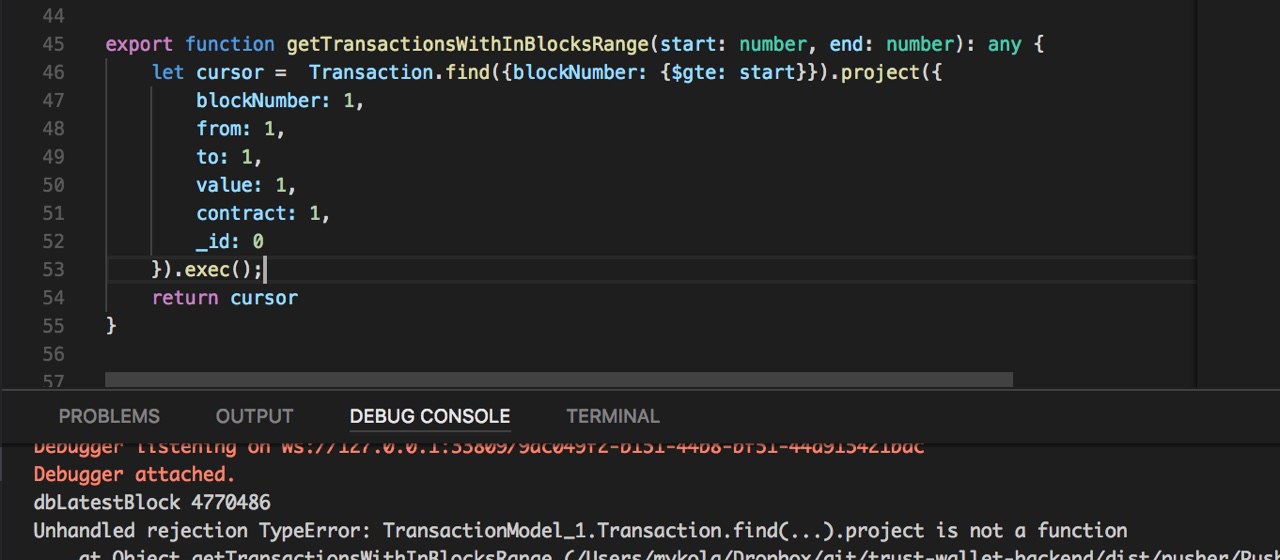
db.transactions.find({blockNumber: 4769868}, {input: 1})
Mykola
если ты хочешь ограничить данные возвращаемые монгой то синтаксис совсем другой
Именно это и хочу, но почему в туториале данные котоыре хочу вернуть надо вбивать в project() ?
Ilya
я по твоей ссылке не увидел там такого
Mykola
 Ilya
Ilya
а ну
Ilya
это какой то язык
Ilya
а ы делаешь в шеле
Ilya
то есть ты node смотришь
Ilya
а принтскрин привел из шела
Ilya
или я ошибаюсь?
Mykola
 Mykola
Mykola
 SvPupok
SvPupok
Камрады, а никто мониторинг netdata под монгу не настраивал?
Ilya
 Viktor
Viktor
тут нет лучше/хуже критерия, выбирай под задачу
Viktor
Ссылку не дам, но мы в своем продукте (система для прохождения экзаменов) используем монгу для хранения вопросов
Viktor
Типы вопросов разные, поэтому помогает отсутствие схемы. Документы используются почти всегда целиком, поэтому реляционка здесь только бы мешала (была бы куча ненужных джойнов/кейсов итд)
Viktor
Еще в минус к постгре (думали хранить кастомные поля вопросов в jsonb) при выборе было то, что драйвер под .net объективно был и есть хуже
SvPupok
хм, у меня был опыт хранения json в oracle. вполне неплохо работало.
 Ilyas
Ilyas
Привет, парни.
Хотел спросить следующий вопрос.
Я работаю со статистикой посещений и кликов, каждый день для каждого пользователя, создается 1 документ.
Пример: {id: 123456, visits: 20, clicks: 10, date: "2017-12-21T13:31:50.544Z"}
Допустим прошел год и пользователь хочет увидеть статистику за год, мне нужно из базы вернуть 365 документов, это плохая идея? Если да, то по другому как можно сделать?
 Slava
Slava
Привет, парни.
Хотел спросить следующий вопрос.
Я работаю со статистикой посещений и кликов, каждый день для каждого пользователя, создается 1 документ.
Пример: {id: 123456, visits: 20, clicks: 10, date: "2017-12-21T13:31:50.544Z"}
Допустим прошел год и пользователь хочет увидеть статистику за год, мне нужно из базы вернуть 365 документов, это плохая идея? Если да, то по другому как можно сделать?
Привет, можно средствами aggregation framework делать нужную тебе агрегацию и отдавать результат. Или же запускать по крону (раз в год, не календарный) задачу которая все с аггрегирует в один документ.
Ilyas
 Eugene [MSK+3]
Eugene [MSK+3]
Всем привет, вопрос по сортировке.
Допустим, мне необходимо отсортировать не по одному значению, а по результату сравнения двух значений (грубо говоря, по соотношению двух значений).
Пример:
Коллекция содержит документы с числовыми значениями: "value1", "value2", "value3".
Мне необходимо отсортировать документы в таком виде: value1/value3.
Каким образом это можно реализовать, кроме как записывать результат деления в документ при обновлении, а потом сортировать по данному значению?
МБ есть возможность передать функцию для сортировки, которая будет принимать два документа, как в JS метод sort для массивов?
 Yaroslav
Yaroslav
а в aggragation pipeline сначала через project создать новое поле, а потом отсортировать по нему не подойдет?
или aggragation pipeline использовать никак нельзя?
Viktor
Всем привет, вопрос по сортировке.
Допустим, мне необходимо отсортировать не по одному значению, а по результату сравнения двух значений (грубо говоря, по соотношению двух значений).
Пример:
Коллекция содержит документы с числовыми значениями: "value1", "value2", "value3".
Мне необходимо отсортировать документы в таком виде: value1/value3.
Каким образом это можно реализовать, кроме как записывать результат деления в документ при обновлении, а потом сортировать по данному значению?
МБ есть возможность передать функцию для сортировки, которая будет принимать два документа, как в JS метод sort для массивов?
можно сделать project и сортировать потом по нему, но нужно сразу учесть, что на одну стадию максимум 100мб рам выделяется
Viktor
поэтому если данных много, то лучше создать дополнительное поле как результат деления
Viktor
возможно, даже накрутить индекс потом по нему
Eugene [MSK+3]
Проблема в том, что результатов деления может быть довольно много, т.к. полей для сравнения будет многовато.
Если через project делать, то в саму бд поле будет добавляться или будет использоваться чисто в момент поиска, для сортировки?
Yaroslav
будет использоваться чисто в момент поиска, для сортировки. но есть определенные ограничения.
почитайте про aggragation pipeline
Eugene [MSK+3]
Спасибо
 Nick
Nick
Проблема в том, что результатов деления может быть довольно много, т.к. полей для сравнения будет многовато.
Если через project делать, то в саму бд поле будет добавляться или будет использоваться чисто в момент поиска, для сортировки?
Ориентировочное количество данных какое? На практике монга показала, что произвольные запросы не для нее. Например выбрать данные по вашему сообтношению v1/v3 > N через aggragate потребует полного перечитывания всех документов
Nick
вы должны быть готовы к тому, что это сожрет все дисковые ресурсы
Eugene [MSK+3]
10000 документов примерно
Nick
тогда не имеет значения
Eugene [MSK+3]
Спасибо
 Deenya
Deenya
всем привет, у меня такая ситуация: есть база с результатами перфоманс тестирования. Каждый документ - это один запрос, в котором записана скорость ответа сервера и номер сборки, в рамках которой этот запрос был выполнен. Так вот, может ли монго объединить мне эти запросы в объекты по номеру сборки + посчитать среднее время всех запросов для каждой сборки (надо показать среднюю производительность сборки)?
Deenya
в принципе еще не поздно структуру базы переделать, если так как сейчас сделано плохо
Nick
https://docs.mongodb.com/manual/reference/operator/aggregation/group/
Nick
и соответвенно среднее https://docs.mongodb.com/manual/reference/operator/aggregation/avg/#grp._S_avg
Deenya
спасибо
Deenya
а как у него со скоростью?
Deenya
есть вариант при пуше в базу подсчитывать среднее
Deenya
документов порядка 50к в одной базе
Nick
если операции разовые, то подойдет
Nick
если нужно укладыватсь в SLA, то да надо менять структуру
Deenya
это нужно для самодельной дашборды. Никаких ограничений нет, но будет неприятно если дашборда при каждом открытии будет тормозить
Deenya
хочу сделать график с результатами тестирования
Deenya
для этого и нужно среднее по сборкам
Nick
думаю тут нужно просто попробовать выполнить запрсо по вашим данным
Nick
если время устроит то ничего придумывать ен потребуется
Nick
а почему именно монго?
Deenya
просто все остальные небольшие проекты на монге были, вот и взял по привычке
Deenya
думаете лучше постгрес подойдет?
Nick
это как вариант, если aggregate не устроит
Deenya
спасибо
yopp
Нужно смотреть как часто смотрят за год. Если часто, то проще собрать в один документ который описывает целый год (-365 повторений пары id, до365 раз меньше записей в индексе)
Maxim
Ребята, привет!
как лучше реализовать фильтрацию в mongoose при условии большого количества записей? с помощью where() или обработать записи с помощью exec()? точней каким образом наименьшей будет нагрузка на сервак при выполнении фильтрации по нескольким полям?
yopp
Всем привет, вопрос по сортировке.
Допустим, мне необходимо отсортировать не по одному значению, а по результату сравнения двух значений (грубо говоря, по соотношению двух значений).
Пример:
Коллекция содержит документы с числовыми значениями: "value1", "value2", "value3".
Мне необходимо отсортировать документы в таком виде: value1/value3.
Каким образом это можно реализовать, кроме как записывать результат деления в документ при обновлении, а потом сортировать по данному значению?
МБ есть возможность передать функцию для сортировки, которая будет принимать два документа, как в JS метод sort для массивов?
если есть возможность считать значение для сортировки при обновлении документа, обязательно нужно считать при обновлении документа
yopp
потому что в монге нельзя делать индексы по эфемерным данным, а значит сортировка будет требовать высчитывания этих значений по _всем_ документам
yopp
и потом уже сортировки
yopp
впрочем и не только монга
yopp
в принципе еще не поздно структуру базы переделать, если так как сейчас сделано плохо
среднее, максимум и минимум можно считать без хранения семплов
yopp
просто заведите поле с сумарным временем, счётчик семплов и поля для max и min
yopp
и дальше одним запросом обновляйте
Deenya
всмысле еще одну коллекцию создать?
yopp
зачем?
yopp
или сырые данные нужны?