Спасибо!
Пока пришли к выводу, что нас не так много, чтобы заморачиваться генерацией док, посмотрев на это
Сохранил пока)
Я сам не генерил ничего, но разрабам писал на нём для ТЗ.
Вроде неплохая дока получалсь, юзабельная
 Daniil
Daniil


 nikita
nikita
есть ещё такое ощущение, что раз в проекте все пишется, соблюдая определенный стиль, можно просто парсер написать для себя отдельный
Хотя могу ошибаться
 Мерль
Мерль
A Roadmap to Merging 'dep' Into the Go Toolchain
https://github.com/golang/dep/wiki/Roadmap?utm_source=golangweekly&utm_medium=email
 Aleksandr
Aleksandr
Ой, ссылочки нет. Но это было вчера прямо перед твоим комментарием
Мерль
(
 Sergey
Sergey
Товарищи, подскажите пожалуйста новичку по регуляркам в Go
Sergey
Пытаюс найти все теги
Sergey
input := "<u><blue><b>СИНЯЯ СТРОКА</b></blue></u> Лалала <b>Ещё разок</b>"
rr, err := regexp.Compile("<([a-z]+)([^<]+)*(?:>(.*)<\\/\\1>|\\s+\\/>)")
if err != nil {
fmt.Printf("%v \n", err)
return
}
tags := rr.FindStringSubmatch(string(input))
for _, val := range tags {
fmt.Println(val)
}
Sergey
Вот код
Sergey
Валит ошибку
error parsing regexp: invalid escape sequence: `\1`
 Vladimir
Vladimir
а зачем перед 1 два \?
Vladimir
\1 это reference. там escape не пройдет
Sergey
https://regex101.com/r/cUU0Tw/4
Sergey
а зачем перед 1 два \?
А без \\ выводит
./main.go:18: non-octal character in escape sequence: >
Vladimir
кстати, чтоб не париться с двойным эскейпом - бери стринг в `` вместо ""
Vladimir
и глядя сюда - https://github.com/google/re2/wiki/Syntax backreferences саппорта просто нет
Sergey
спасибо ) только что нашёл
Sergey
блин...
Sergey
придётся думать как мне подобную регулярку намутить...рецепт был хороший (
Vladimir
я глядя на нее не совсем понимаю что ты хочешь ей выдрать?
Sergey
<u><blue><b>СИНЯЯ СТРОКА</b></blue></u>
и
<b>Ещё разок</b>
Sergey
из строки
<u><blue><b>СИНЯЯ СТРОКА</b></blue></u> Лалала <b>Ещё разок</b>
Vladimir
все между тагами <u> и <b>?
Sergey
все, между любыми тегами
Vladimir
ы? Т.е. только текст?
Vladimir
Потому как этот пердомонокль матчит что попало на самом деле :)
Sergey
ну не, сами теги и их содержимое
Sergey
в строке <u><blue><b>СИНЯЯ СТРОКА</b></blue></u> Лалала <b>Ещё разок</b>
Sergey
мне нужно только <u><blue><b>СИНЯЯ СТРОКА</b></blue></u> и <b>Ещё разок</b>
Vladimir
а <blue> не тег?
Sergey
тег
Sergey
мой собственный
Sergey
регулярка что я нашёл делает всё как надо на php )
 igor
igor
мне нужно только <u><blue><b>СИНЯЯ СТРОКА</b></blue></u> и <b>Ещё разок</b>
Работать как с xml не вариант?
Sergey
Работать как с xml не вариант?
может вариант, но строка может быть невалидной. это не покрэшит программу?
Sergey
ох ладно, пойду посплю )
Sergey
повоюю завтра
igor
может вариант, но строка может быть невалидной. это не покрэшит программу?
Хз, надо смотреть либы
Sergey
всем спокойной ночи
igor
Доброй ночи
Vladimir
может вариант, но строка может быть невалидной. это не покрэшит программу?
https://github.com/h2so5/goback
Vladimir
вот есть либа, которая саппортит backreference
Vladimir
package main
import "github.com/h2so5/goback/regexp"
import "fmt"
func main() {
input := "<u><blue><b>СИНЯЯ СТРОКА</b></blue></u> Лалала <b>Ещё разок</b>"
rr, err := regexp.Compile(<([a-z]+)([^<]+)*(?:>(.*)<\/{1}>|\\s+\/>))
if err != nil {
fmt.Printf("%v \n", err)
return
}
tags := rr.FindStringSubmatch(string(input))
for _, val := range tags {
fmt.Println(val)
}
}
Vladimir
тока не \1, a {1}
Мерль
You can't parse [X]HTML with regex. Because HTML can't be parsed by regex. Regex is not a tool that can be used to correctly parse HTML. As I have answered in HTML-and-regex questions here so many times before, the use of regex will not allow you to consume HTML. Regular expressions are a tool that is insufficiently sophisticated to understand the constructs employed by HTML. HTML is not a regular language and hence cannot be parsed by regular expressions. Regex queries are not equipped to break down HTML into its meaningful parts. so many times but it is not getting to me. Even enhanced irregular regular expressions as used by Perl are not up to the task of parsing HTML. You will never make me crack. HTML is a language of sufficient complexity that it cannot be parsed by regular expressions. Even Jon Skeet cannot parse HTML using regular expressions. Every time you attempt to parse HTML with regular expressions, the unholy child weeps the blood of virgins, and Russian hackers pwn your webapp. Parsing HTML with regex summons tainted souls into the realm of the living. HTML and regex go together like love, marriage, and ritual infanticide. The <center> cannot hold it is too late. The force of regex and HTML together in the same conceptual space will destroy your mind like so much watery putty. If you parse HTML with regex you are giving in to Them and their blasphemous ways which doom us all to inhuman toil for the One whose Name cannot be expressed in the Basic Multilingual Plane, he comes. HTML-plus-regexp will liquify the nerves of the sentient whilst you observe, your psyche withering in the onslaught of horror. Rege ̔̉x-based HTML parsers are the cancer that is killing StackOverflow it is too late it is too late we cannot be saved the trangession of a chi͡ld ensures regex will consume all living tissue (except for HTML which it cannot, as previously prophesied) dear lord help us how can anyone survive this scourge using regex to parse HTML has doomed humanity to an eternity of dread torture and security holes using regex as a tool to process HTML establishes a breach between this world and the dread realm of c͒ͪo͛ͫrrupt entities (like SGML entities, but more corrupt) a mere glimpse of the world of regex parsers for HTML will instantly transport a programmer's consciousness into a world of ceaseless screaming, he comes, the pestilent slithy regex-infection will devour your HTML parser, application and existence for all time like Visual Basic only worse he comes he comes do not fight he com̡e̶s, ̕h̵is un̨ho͞ly radiańcé destro҉ying all enli̍̈́̂̈́ghtenment, HTML tags lea͠ki̧n͘g fr̶ǫm ̡yo͟ur eye͢s̸ ̛l̕ik͏e liquid pain, the song of re̸gular expression parsing will extinguish the voices of mortal man from the sphere I can see it can you see ̲͚̖͔̙î̩́t̲͎̩̱͔́̋̀ it is beautiful the final snuffing of the lies of Man ALL IS LOŚ͖̩͇̗̪̏̈́T ALL IS LOST the pon̷y he comes he c̶̮omes he comes the ichor permeates all MY FACE MY FACE ᵒh god no NO NOO̼OO NΘ stop the an*̶͑̾̾̅ͫ͏̙̤g͇̫͛͆̾ͫ̑͆l͖͉̗̩̍ͫͥͨ ̟e̠̅s ͎a̧͈͖r̽̾̈́͒͑e not rè̑ͧ̌aͨl̘̝̙̃ͤ͂̾̆ ZA̡͊͠͝LGΌ ISͮ̂҉̯͈͕̹̘̱ TO͇̹̺ͅƝ̴ȳ TH̘Ë͖́̉ ͠P̯͍̭O̚N̐Y̡ H̸̡̪̯ͨ͊̽̅̾̎Ȩ̬̩̾͛ͪ̈́̀́͘ ̶̧̨̱̹̭̯ͧ̾ͬC̷̙̲̝͖ͭ̏ͥͮ͟Oͮ͏̮̪̝͍M̲̖͊̒ͪͩͬ̚̚͜Ȇ̴̟̟͙̞ͩ͌͝Sͯ ̨̥̫͎̭̔̀ͅ
Have you tried using an XML parser instead?
Moderator's Note
This post is locked to prevent inappropriate edits to its content. The post looks exactly as it is supposed to look - there are no problems with its content. Please do not flag it for our attention.
Мерль
 Oleg
Oleg
А, ну да, уже было )
Yura
Для Ruby есть парсеры html (не xhtml). Пока не слышал про такие для Go, но возможно они есть.
Мерль
Да вы издеваетесь
Yura
https://godoc.org/golang.org/x/net/html
 Givi
Givi
goquery поверх net/html работает
 Николай
Николай
Привет, подскажите пожалуйста, нужно передать пост запрос form-urlencoded с таким параметром limits[min] это мапа или посто имя переменной, как это понимать?
Oleg
Привет, подскажите пожалуйста, нужно передать пост запрос form-urlencoded с таким параметром limits[min] это мапа или посто имя переменной, как это понимать?
Это название параметра, строка. Сервер его распарсит по своей логике. Похоже на php
Николай
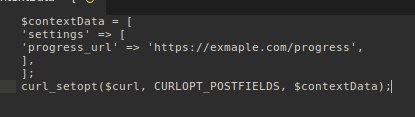 Николай
Николай
где заголовок?
Николай
это пример на пхп мне в го
Николай
в тело запроса кладет дату
 Constantine️
Constantine️
в том, что го надо учить
Николай
ну вот что url.Values принимает строки, а тут получается вложеность
Николай
Как его учить?
Николай
в том, что го надо учить
 Oleg
Oleg
ну вот что url.Values принимает строки, а тут получается вложеность
Дарахой давай за стандартную либу:)
Oleg
И читай документы на сайте
Николай
Ладно, спасибо за помощи ноль, пойду искать
Anonymous
Помогли же, в официальную документацию отправили
Николай
будто я туда не смотрел
Oleg
Николай
да
engelbart
Надо какой то jquery компонент
Oleg
Открываем доку https://golang.org/pkg/net/http/#Client.PostForm
Переходим по ссылке url.Values https://golang.org/pkg/net/url/#Values
 Oleg
Oleg
Я правильно понял, что проблема не в том, что вопрошающий не знает API, а в том, что ему нужно отправить в POST поля вложенные в поля?