 Kolya
Kolya


Они приходят ко мне скопом. Сразу все. Но вот память копится во время ожидания ответа от базы
Kolya
там генератор некуда втыкать
 Ga
Ga
Блин, задача не простая
Ga
Можешь ли ты эти данные кэшировать у себя?
Ga
И тд
Ga
Тк это метрика, ты можешь развернуть сервис очередей, а клиентам писать ваш запрос будет подготовлен в течении 5 минут. Если ты не можешь кэшировать данные, то скорее всего здесь только масштабированием решать или очередями
Ga
Это сложная задача и тут нужно понимать что нужно, скорость отдачи или она не так важна
Сергей
Метрики только по дням считаете?
Kolya
Там очень большой объем данных, чтобы их хранить у себя, даже в закэшированном виде. Мы выстраиваем систему кэширования но не для такого объема данных
Ga
Тогда очереди наверное
 Igor
Igor
Там очень большой объем данных, чтобы их хранить у себя, даже в закэшированном виде. Мы выстраиваем систему кэширования но не для такого объема данных
150мб это не объем по современным меркам.
Ga
Чтобы не падать
Kolya
Тогда очереди наверное
Скорее всего да. Вряд ли решение другое подойдет. Скорость получения для пользователя не так критична
Igor
Оптимизация через чат это очень странная метода) вобще нужно лучше понимать что за данные
Ga
Сергей
Там очень большой объем данных, чтобы их хранить у себя, даже в закэшированном виде. Мы выстраиваем систему кэширования но не для такого объема данных
Вопрос в том, нужны ли ему все данные, потому что он говорит, что они показывают по дням, можно просто хранить у себя метрику за день для каждой записи
Сергей
Ну не весь объём, а вот готовую точку
Ga
Kolya
150мб это не объем по современным меркам.
Это обработанный после условий. От кол-ва условий, которые пропишет пользователь, зависит объем. Нам придется кэшировать всю таблицу. А эта таблица логов по сайту. Уникальных пользователей порядка 4-5 млн, прикинь какой там будет объем логов
Kolya
Воронка это тулз для поика последовательностей поведения пользователя
Kolya
Тут посчитать зарание что-то не получится
Ga
Тогда очереди, если там такая большая детализация
Igor
Может у них запрос дерьмо. Нужно смотреть план выполнения, а может они вообще творят полную дичь хз что там происходит. Что вообще значит "пока выполняется запрос у меня копится память?" чиво блядь?
Сергей
Ты хватаешь потом из воронки
Kolya
Может у них запрос дерьмо. Нужно смотреть план выполнения, а может они вообще творят полную дичь хз что там происходит. Что вообще значит "пока выполняется запрос у меня копится память?" чиво блядь?
Если бы я сам знал как это объяснить иначе, объяснил бы. Все именно так. Пока жду ответа копится память. Что к чему вообще хз
Igor
А так ты по ходу вычитываешь курсор в память вот оно и копится
Kolya
Ты хватаешь потом из воронки
Полей в таблице около 30. Каждое из них может быть условием для шага. ЭТи шаги пользователь прописывает сам ручками. Тут не получится с агрегировать данные за день по каким-то условиям и ждать, что пользователь именно их пропишет
Igor
Тебе сервак данные отдает постепенно ты их у себя накапливаешь.
Igor
А куда он должен курсор читать?
Сергей
Kolya
Почитай что такое воронка и как её строят в аналитике
Igor
Покажи запрос чтоли... А то у нас есть какая то хуйня она хуяк хуяк и памяти нет долго и вообще все плоха... Ааааа что делать?
 Иаков
Иаков
 Сергей
Сергей
Покажи запрос чтоли... А то у нас есть какая то хуйня она хуяк хуяк и памяти нет долго и вообще все плоха... Ааааа что делать?
А ты про воронки почитай, и как их строят в аналитике, там же и запрос увидишь
Igor
Понятно одно они из 20 лямов затягивают нахуя то 4 ... И все тормозит. Это все что я понял.
Kolya
Покажи запрос чтоли... А то у нас есть какая то хуйня она хуяк хуяк и памяти нет долго и вообще все плоха... Ааааа что делать?
select sipHash64(user_id) as user_id_hash
, toUInt8(windowFunnel(86400)(datetime, {steps_conditions})) as steps
, count() as total_by_ring {count_conditions}
from таблица
where 1 = 1 {date_condition}
and is_bot = 0
and length (user_id) >= 32
and user_id NOT IN (''
, 'NULL'
, 'deleted')
and cache_hit != 1
group by ring_hash
Kolya
Мало что тебе это даст
Иаков
Подскажи пожалуйста на счёт изучения vb net. Как это лучше всего делать? Инфа вся только в доках, а книги чуть ли не прошлого столетия
Зачем vb? Учи c#, они оба на платформе .net, но шарп круче
Kolya
А ты про воронки почитай, и как их строят в аналитике, там же и запрос увидишь
Я использую windofunnel.
Можно руками собирать запрос, но смысла немного
Kolya
 Ga
Ga
Я использую windofunnel.
Можно руками собирать запрос, но смысла немного
Короче, если ты не можешь данные кэшировать и отказаться от объемов данных. Делай очереди, чтобы не ложиться. Для меня контекста мало, но из того что я понял.
Юзер делает запрос к тебе-> ты кидаешь запрос в какое->то место откуда тоже ждёшь данные, после обрабатываешь их (как раз это и грузит память)-> отдаёшь юзеру
Но ты можешь поочерёдно обрабатывать полученные данные и потихоньку отдавать их стримом юзеру( будет пик, при подгрузки данных, но память потом будет постепенно очищаться), если там все линейно и это возможно.
В иных случаях микросервис очередей и копай дальше как можно оптимизировать
Только ты сможешь понять то, как код можно оптимизировать.
Ga
Kolya
Юзер делает запрос к тебе-> ты кидаешь запрос в какое->то место откуда тоже ждёшь данные (как раз это и грузит память)- -> после обрабатываешь их> отдаёшь юзеру
Kolya
Так схема выглядит
Ga
Тебе нужно просто вычищать обработанные данные и все, но пик все равно будет, а потом линейно будет снижаться
Ga
Но ещё ты можешь полученные данные из какого-то места постепенно получать и парсить и сразу отдавать в стрим
Igor
Igor
А самое главное схуя бы ему снижаться)
Ga
Пик и на снижение, обработанные данные просто чистить
Igor
Я наверное на вашем языке не понимаю сорри)
Ga
Всмысле
Igor
В смысле я хз что мы обсуждаем мы даже запроса не видели.
Igor
А вот это "пик снижения" я вообще не понимаю, может я дурак я не спорю
Ga
Я так понимаю там откуда-то запрашиваются какие-то данные(не из бд) GET’ом или постом и они у него грузят память
Ga
А им где ещё хранится
Igor
Так из бд ж.
Ga
Не, там сервак имеет бд(откуда он их запрашивает) и соотвественно отдаёт с запроса, а не напрямую из бд. Или я уже запутался
Ga
А да я запутался, короче контекста мало. Но надеюсь решит
Ga
Но что-то мне подсказывает, что там генераторы решат проблему
Igor
Юзер делает запрос к тебе-> ты кидаешь запрос в какое->то место откуда тоже ждёшь данные (как раз это и грузит память)- -> после обрабатываешь их> отдаёшь юзеру
Ты не ждешь данные ты их читаешь, ты де сам сказал на удаленном сервере выполнение запроса занимает 40 сек. Значит все остальное время ты получаешь данные. Вычитываешь курсор в память эти данные и жрут память по мере вычитки
Igor
Но что-то мне подсказывает, что там генераторы решат проблему
Не решат именно потому что курсор вычитывается в память целиком
Ga
Но если они из бд берутся, там же можно стримом читать их, обрабатывать по одному и стримом на ответ отдавать сразу?
Ga
Тем самым памяти не так много будет есть
Ga
Либо я туплю
Сергей
Но если они из бд берутся, там же можно стримом читать их, обрабатывать по одному и стримом на ответ отдавать сразу?
Если они где-то лежат, и он показывает за день данные, то не вижу проблем считывать фоном за сутки и хранить за сутки у себя
Сергей
Ну а потом юзерам
Igor
Теоретически можно все что угодно а практически... Я устал повторять джанга вычитывает весь курсор в память целиком.
Ga
Igor
Оптимизируют конретный воркфлоу... А вот это что читается что то происходит и что то медленно. Ответ один что то ты не понимаешь, нужно что то оптимизировать
 Dmitriy
Dmitriy
 Dmitriy
Dmitriy
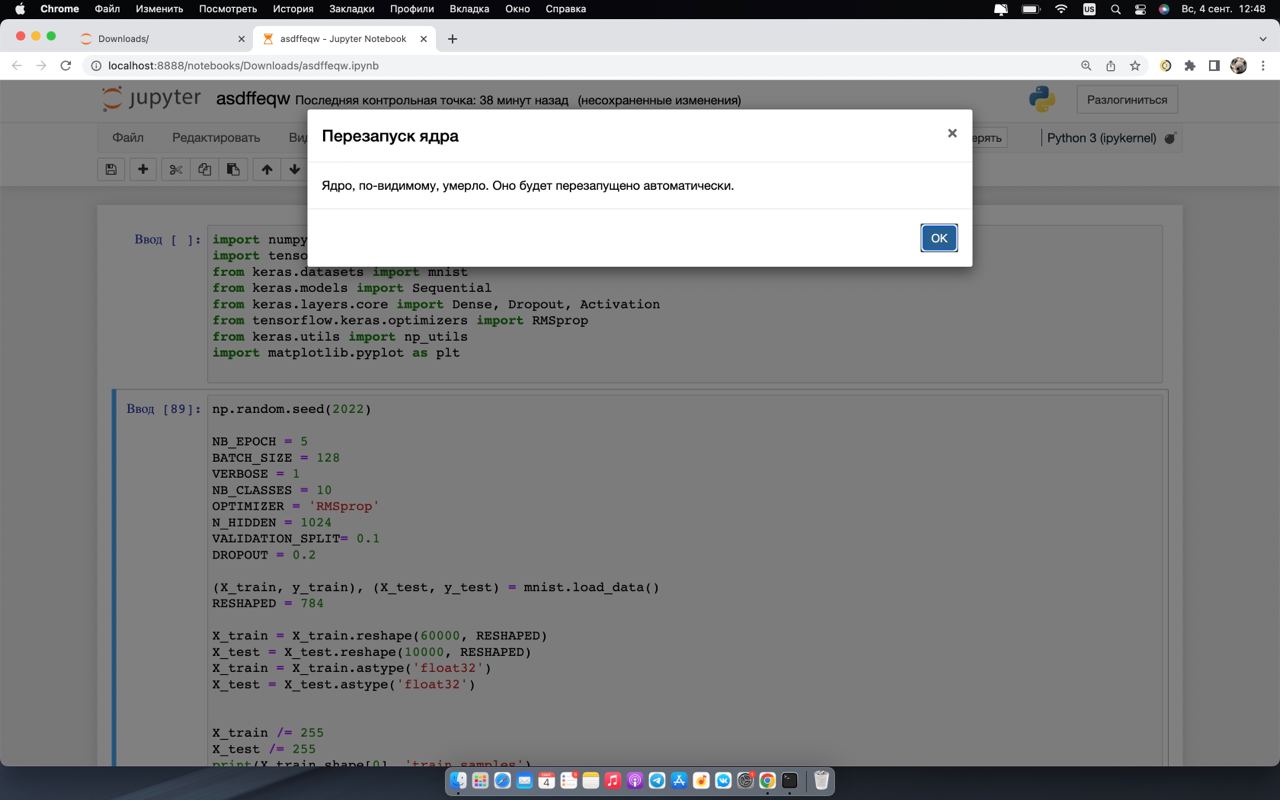
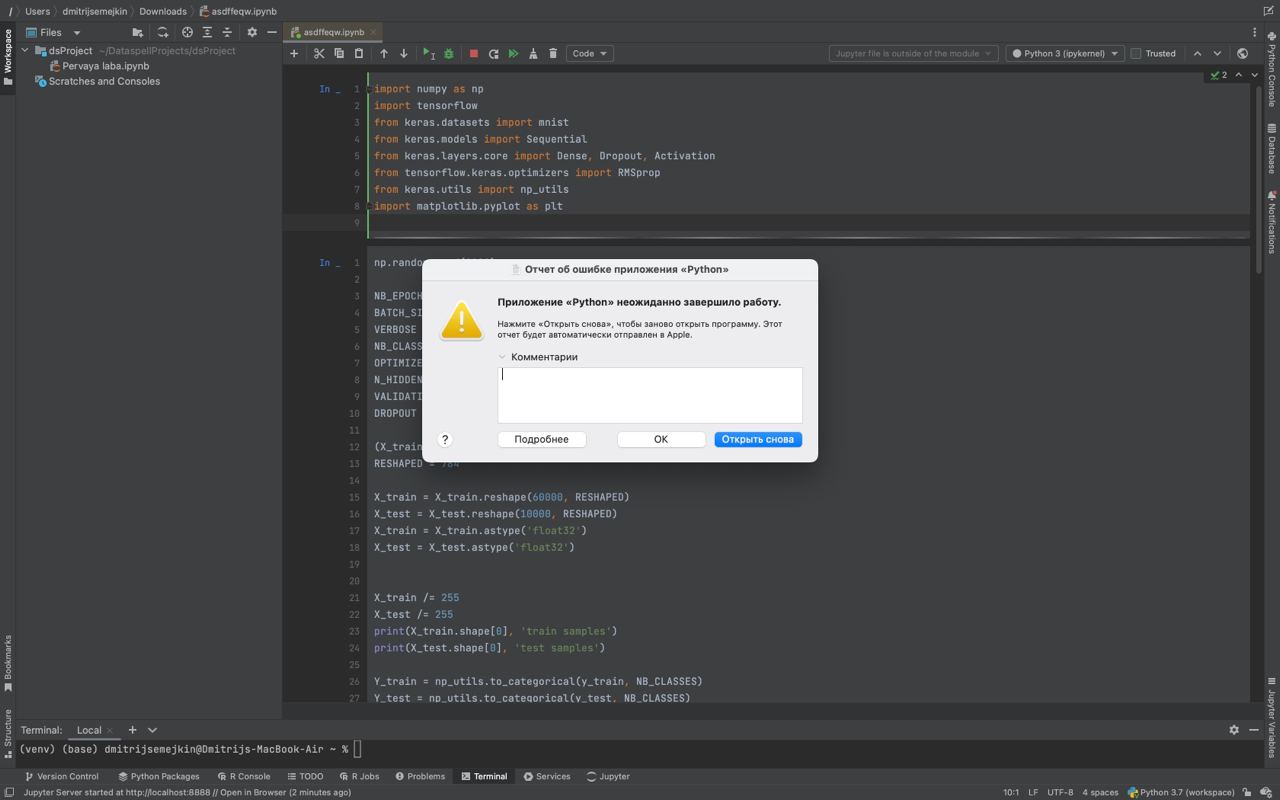
import numpy as np
import tensorflow
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from tensorflow.keras.optimizers import RMSprop
from keras.utils import np_utils
import matplotlib.pyplot as plt
Dmitriy
Все библиотеки установлены
Dmitriy
 🐈
🐈
Всем привет, уважаемые разработчики. Здесь присутствуют блокчейн-разработчики?
Стал интересоваться темой блокчейн,криптовалют. Кто знаком с экосистемой Cosmos, они имеют свою платформу CosmWasm для создания смарт-контрактов и есть давно известные модели контрактов на Ethereum , хочу понять в чем между ними разница? Информации про смарт-контракты на Ethereum очень много, но о CosmWasm гораздо меньше. Хотел узнать, получится ли научиться писать смарт-контракты на CosmWasm, научившись писать на Ethereum?
 Vyacheslav
Vyacheslav