 ㅤ
ㅤ


Это хорошо
Nick
да, указатель, что ж ещё
у меня всё правильно, но несколько не стандартно для компилятора и он предполагает, что я ошибся.
Сейчас попробовал воссоздать ваш кeйс
Забавно следующее: когда я в memcpy засунул вторым аргументом С-string:
memcpy((Some + 2) -> data, "4", 1)
никаких проблем не возникло - ни варнингов, ни даже note
Но когда я попробовал добавить просто один байт, типа
memcpy((Some + 2)->data, (char)'4', 1)
то компилер выдал то же самое, что у вас
Nick
Да, дела
ㅤ
Второе это вообще дичь. Ты вместо адреса поставил значение символа '4'
Andy
На мой взгляд правильнее сказать компилятору, что data у вас это какой-то кусок памяти, а его размер определяется динамически.
Т.е.:
typedef struct {
size_t length;
char *data;
} str_t;
Nick
А, и правда
 ok-home
ok-home
Нужно чтобы работало или чтобы варнинги ушли ?
Nick
Еще пара таких случаев, и С вспомню
Nick
Нужно чтобы работало или чтобы варнинги ушли ?
Не знаю, что именно нужно коллеге выше, но если кeйс рабочий, то это синонимы, как правило
Насколько мне известно, сишные продакшены при компиляции всегда флаг -Werror ставят
Nick
Так что там варнинги = не работает
ok-home
А ничего что память выделяется на структуру, а мемкопи на элемент структуры размером в 1 байт. Что там в итоге куда копируется хз. Вот компилятор честно предупреждает.
Nick
Да я и не спорю
 Аргентина
ㅤ
Аргентина
ㅤ

 Ruslan
Ruslan
он не может
ㅤ
Хуле все такие криворукие нынче
Ruslan
время такое
 Anton
Anton
На мой взгляд правильнее сказать компилятору, что data у вас это какой-то кусок памяти, а его размер определяется динамически.
Т.е.:
typedef struct {
size_t length;
char *data;
} str_t;
два выделения памяти вместо одного, а у меня есть проблема фрагментации кучи. плюс хранение указателя просто для целей второго выделения памяти. мой вариант эффективнее
Anton
Нужно чтобы работало или чтобы варнинги ушли ?
одно другого не исключает. работает оно и с варнингом, кстати
 Никита
Никита
Господа, а есть ли в 32есп возможность выбора прошивки для обновления с сервера? Типо если сильно старая версия, то должна установиться промежуточная
 Ivan
Ivan
Господа, а есть ли в 32есп возможность выбора прошивки для обновления с сервера? Типо если сильно старая версия, то должна установиться промежуточная
эт ты сам реализовываешь, чо сосать. фреймворк базовые ота-функцыи только предоставляет - откуда грузить, проверку/взведение флагов, запись в разделы.
Ruslan
эт ты сам реализовываешь, чо сосать. фреймворк базовые ота-функцыи только предоставляет - откуда грузить, проверку/взведение флагов, запись в разделы.
обновляться по воздуху несложно, сложно придумать логику как именно можно обновляться, продумав всё...
Andy
два выделения памяти вместо одного, а у меня есть проблема фрагментации кучи. плюс хранение указателя просто для целей второго выделения памяти. мой вариант эффективнее
Скорее всего проблема в архитектуре решения раз куча так интенсивно фрагментируется. В большинстве задач на МК захват памяти из кучи достаточно редкое явление. Ну и экономия тактов в ущерб надежности кода всегда достаточно спорное решение.
Anton
Скорее всего проблема в архитектуре решения раз куча так интенсивно фрагментируется. В большинстве задач на МК захват памяти из кучи достаточно редкое явление. Ну и экономия тактов в ущерб надежности кода всегда достаточно спорное решение.
проблема в том, что хттп-клиент принимает данные блоками по 512 байт. каждый раз при приёме следующего блока приходится выделять память под новый размер, копировать старое содержимое, добавлять пришедшее новое, освобождать старый участок. хттп запросы идут к нескольким разным сервисам, одни возвращают пару сотен байт, а вот ответ прогноза погоды возвращает под 20 килобайт — это всё читается вот так вот блоками по 512. затем парсится джейсон, который тоже динамически выделяет себе структуры нужные, он довольно развесистый с массивами объектов — всё это создаёт много мелких объектов на куче. можно ли оптимальнее? ну, наверное можно, но проблему сначала же надо получить, и только после этого решать.
Anton
Скорее всего проблема в архитектуре решения раз куча так интенсивно фрагментируется. В большинстве задач на МК захват памяти из кучи достаточно редкое явление. Ну и экономия тактов в ущерб надежности кода всегда достаточно спорное решение.
я пользуюсь ESP32 как микропроцессором, а не как микроконтроллером. ресурсов то у нас больше, чем в "большинстве МК", которые решают "большинство задач для МК", поэтому и архитектура программы больше на классическую похожа
Anton
А что мешает выделить сразу с запасом 100к и не морочиться далее?
наверное то, что 100к свободных у меня уже и нет
Max
наверное то, что 100к свободных у меня уже и нет
Фигассе плотность. Ну окей. Тогда заранее пул из кусочков в 512 байт.
Andy
я пользуюсь ESP32 как микропроцессором, а не как микроконтроллером. ресурсов то у нас больше, чем в "большинстве МК", которые решают "большинство задач для МК", поэтому и архитектура программы больше на классическую похожа
Это вы зря. esp32 ни в коем случае не микропроцессор, поэтому такой подход заведомо приведет к краху проекта. ИМХО
Anton
Это вы зря. esp32 ни в коем случае не микропроцессор, поэтому такой подход заведомо приведет к краху проекта. ИМХО
пока отлаживаю проект — конечно будут краши. если внимательно посмотреть что у нас за интерфейсы — фактически во многом нормальна ос
Anton
Фигассе плотность. Ну окей. Тогда заранее пул из кусочков в 512 байт.
делать строку из кусочков — такое не поймёт парсер cJSON
Max
делать строку из кусочков — такое не поймёт парсер cJSON
Ну окей. Реплай в первых строчках вроде ж в http-заголовках должен размер выдавать даже при чанкед-передаче. Сразу заалоцировать и все.
Anton
Фигассе плотность. Ну окей. Тогда заранее пул из кусочков в 512 байт.
а ещё у меня уже был раньше вопрос про кучу, но никто не ответил. если коротко, то мне кажется маллок не берёт одного пулла, который у меня как раз весьма свободен
Anton
Anton
Ну окей. Реплай в первых строчках вроде ж в http-заголовках должен размер выдавать даже при чанкед-передаче. Сразу заалоцировать и все.
вот мой вопрос: https://t.me/ProEsp8266/329883
Max
при чанкед как раз нет
Ну окей, тогда как Руслан говорил - забирать где-то еще на сервер, фильтровать нужное, отсылать как удобно.
Anton
Ну окей, тогда как Руслан говорил - забирать где-то еще на сервер, фильтровать нужное, отсылать как удобно.
я пока сделал просто: для хттп ответа преаллоцирую 16кб строку, у которой память выделена но длина нулевая. и пока ответ вмещается, то реаллокаций не требуется, что эффективно уменьшает фрагментацию. процесс проработал сутки без проблем, так что пока что всё нормально :)
Max
вот мой вопрос: https://t.me/ProEsp8266/329883
Тут надо выкуривать, как у них аллокатор работает и что там с фрагментацией.
Потому и была первая мысль - выделить сразу от входа большой буфер (аналог huge page на Линуксах) и туда все складывать.
Anton
Anton
пока что 16кб преаллокация меня спасла. но я ещё функциональности добавил и свободной памяти ещё меньше стало :)
Max
А cJSON разве в потоковый режим не умеет?
Max
https://github.com/lloyd/yajl - вот такое нагуглилось, но хз, насколько живое/рабочее.
Anton
https://github.com/lloyd/yajl - вот такое нагуглилось, но хз, насколько живое/рабочее.
парсить джейсон в потоке — это следующий этап, если понадобится. пока вроде работает и так
Max
парсить джейсон в потоке — это следующий этап, если понадобится. пока вроде работает и так
Ага, за переполнение таймстампа мы, значит, переживаем...))
Anton
Ага, за переполнение таймстампа мы, значит, переживаем...))
таймстемп переполнится гарантированно :)
Max
таймстемп переполнится гарантированно :)
Ну, тут тоже фрагментация может прилететь после месяца использования.
Anton
Ну, тут тоже фрагментация может прилететь после месяца использования.
чисто технически это в данном проекте не страшно, ну перегрузятся часики раз в месяц за несколько секунд и дальше показывать будут что надо. но мысль верная, да, про кучу надо как-то больше думать
Max
Anton
Какой-то let it crash, обобряемо.
ну в смысле крэш тут не фатален для проекта. раз в день было б не очень, но раз в неделю уже вообще бы никого не припарило. а раз в месяц никто бы не заметил :)
Max
Max
Прикольно, а на гитхабе полно стриминг-парсеров джейсона.
Например - https://github.com/MaJerle/lwjson
Anton
Прикольно, а на гитхабе полно стриминг-парсеров джейсона.
Например - https://github.com/MaJerle/lwjson
прикольно, похож на приличный вполне.
 Денис
Денис
биткоины раздают😁
Ruslan
а я бы парсил всё на сервере, а железке скармливал только необходимый минимум
Max
а я бы парсил всё на сервере, а железке скармливал только необходимый минимум
Ну да, знаем мы эти третьесторонние сервисы, напихают туда говна, что железку нахрен скукожат.
Ruslan
в железку должны приходить только доверенные данные, но это моя личная паранойя
Ruslan
 Ivan
Ruslan
Ivan
Ruslan
у меня какой-то GSM G4
Ruslan
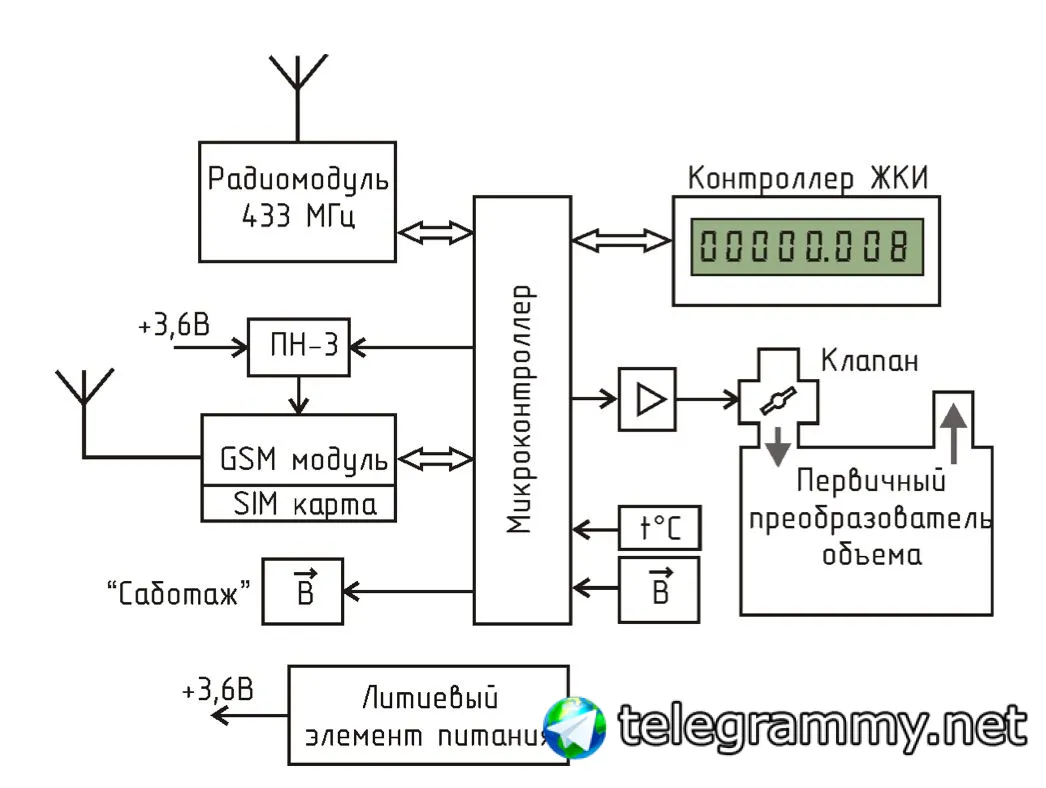
Счетчик оснащен радиоканалом 433 МГц и GSM, и может быть использован в автоматизированной системе коммерческого учета потребления газа.
Ruslan
 Ruslan
Ruslan
И ни слова о формате передачи по 443
Ivan
И ни слова о формате передачи по 443
https://arduino.ru/forum/proekty/chtenie-i-emulyatsiya-datchikov-oregon-scientific-433mhz
Ivan
пробовал?
Ruslan
неа
Dok38
@EVP_07_KZ а можно ссылку на группу по программаторам? Спасибо 🤓
Andrey
Парни приветствую,захотел привязать увлажнитель electrolux у умному дому через умный пульт,уже голову сломал,тысячи кодов перебрал,нифига....
Есть кто в этой теме шарит?
Именно увлажнитель,не кондиционер...Пульта родного конечно же нет
Помогите 😭😭😭😭
ㅤ
Денис
а вдруг он не успеет, увлажнитель же😁
 Evgen
Evgen
епическая сила. Я тут подозревал товарища майора, шо он, сука, не дает доступа на гитхаб с Файрфокса с определенного провайдера. Оказалось это последствия обновления файрфокса. Для начала предыдущую версию хернайдешь и хер поставишь, а поставишь, она немедленно создаст к хуям новый профиль, а потом немедленно к хуям взад обновится. При этом со старой версией гитхаб таки работает, а с новой - только показывает из страницу гитхаба из кеша, а потом кю. Запуск в безопасном режиме с отключенными дополнениями ничего не дает. Запуск с чисткой создает новый профиль, пароли и закладки сохраняет, а вот табы и окна не сохраняет. Не сохраняет табы и окна и расширение фраерфокса для сохранения табов и окон.
Evgen
горе сука какое. 500 табов потерял
Evgen