 Andrey
Andrey


мемлики есть?
 Kirill
Kirill
Искать утечки в стандартной библиотеке? :D
Andrey
ну ее использовать можно неправильно ;)
Kirill
У меня в коде ни одного new
Andrey
ну значит смотри, что внутри контейнера в итоге
Andrey
может я пропустил, max_size у сета смотрел?
Andrey
а не, там не то немного :(
Andrey
а, ну и файл может системой кешироваться
Kirill
Файл может кешироваться, но это не влияет на RES процесса.
Andrey
 Churchill
Churchill
у нас есть доступ друг к другу через учительский комп
Kirill
 Kirill
Kirill
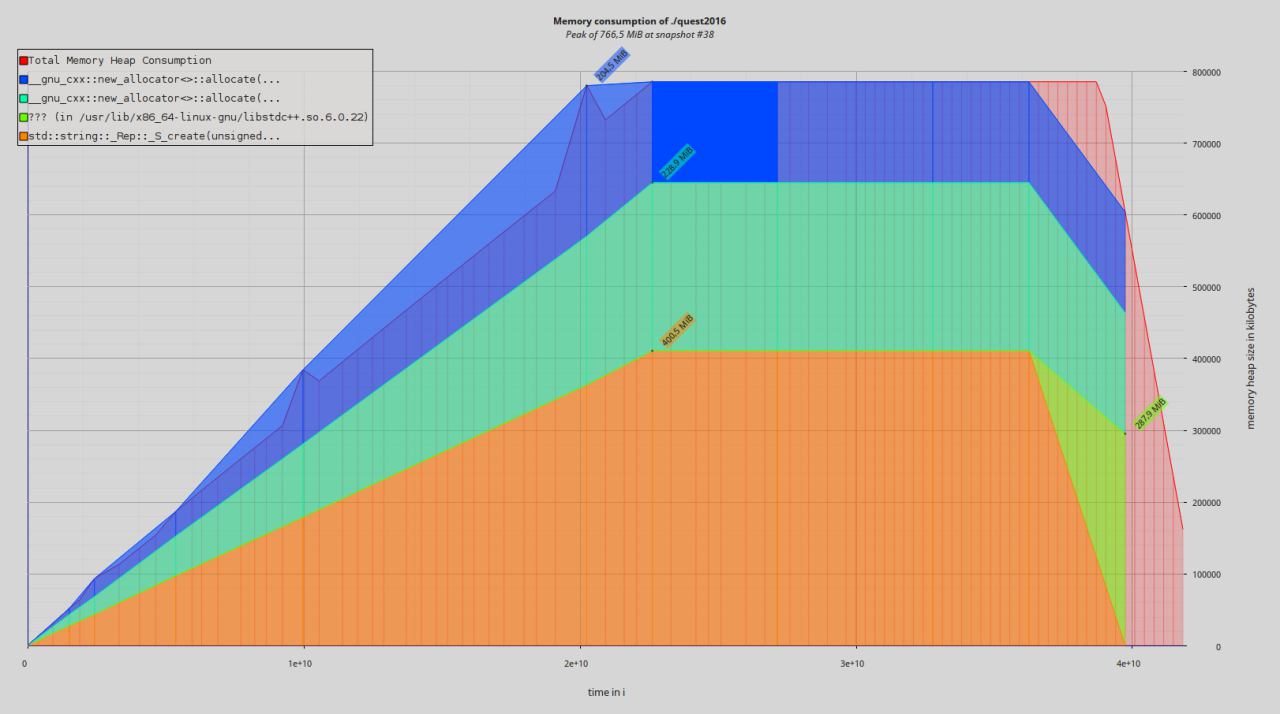
Интересные результаты выдал Massif
Kirill
400 МБ на сами строки
Kirill
360 МБ на хеш-таблицу
Kirill
И якобы пик 766 МБ всего. Откуда же 3 ГБ в RES и попадание в своп?
Kirill
А, поправка. Без Valgrind на файле в три раза меньшего размера выжрал 1 ГБ. Т.е. все линейно.
Kirill
Но все равно больше, чем выдает Massif
Andrey
а что нужно дать тебе, какую инфу
мне не нужно давать ) ты сам должен понять, как пакеты по сети ходят :) если компы друг друга видят, тогда это может быть не сильно критично. Но обычно в сети есть свичи. Напрямую компы редко напрямую соединяются.
Churchill
ок
Andrey
посмотри какие порты досутпны. Может smb хватит (если еще это пашет и открыто)
 λ
λ
Hi. Как такое может бьіть?
jni/../../Classes/GenericFunc.cpp:220:5: error: 'puts' is not a member of 'std'
std::puts(buffer);
Andrey
<cstdio> не забыл?
λ
cstdio.h: No such file or directory
stdio.h никак не влияет на ошибку
λ
Сомневаюсь, но может дело в android-ndk? (По идее же std в комплекте с cpp идет, не важно какой тулчейн использовать?) — https://bpaste.net/raw/606f37c51a40
λ
Используется так:
char *buffer = new char[10];
std::strftime(buffer, 10, "%Y-%m-%d", timeinfo);
std::puts(buffer);
λ
Все же правильно? Туда передается char* тоесть функция есть. И значит проблема не в неправильном использовании puts...
λ
Или puts и std::puts разньіе звери?
Kirill
А без std видит?
λ
Yep 😃
Kirill
Такое бывает на старых компиляторах
Kirill
Когда-то cstdio не заключал stdio.h в пространство имен std
 🦥Alex Fails
🦥Alex Fails
cstdio.h: No such file or directory
stdio.h никак не влияет на ошибку
не cstdio.h, а просто cstdio
🦥Alex Fails
Да
🦥Alex Fails
Но stdio.h не делает неймспейс std
 Ned
Ned
ну да, потому что там для совместимости с плюсОвыми примочками есть только extern "C" {}
 Suigintou45
Suigintou45
да, и если мускуль то мемори енжайн взять для такого
чота там искоропки около 1мб ограничение на темп таблицу с этим енджайном. myisam поставил
🦥Alex Fails
А как же иннодб?
 Stanislav
Stanislav
чота там искоропки около 1мб ограничение на темп таблицу с этим енджайном. myisam поставил
max_heap_table_size тебя спасет
🦥Alex Fails
А
 Anonymous
Anonymous
Кто подскажет? Где в коде эти плагины? https://sourceforge.net/p/tht/code/HEAD/tree/
Anonymous
 ttldtor
ttldtor
ну, они заканчиваются на слово plugin =)
finvizplugin.h/cpp
stocksinplayplugin.h/cpp
ttldtor
прям как есть навалены, в транке, например https://sourceforge.net/p/tht/code/HEAD/tree/trunk/
Anonymous
Anonymous
А тут нет такого
Anonymous
Это код с самой проги,скаченной..
Kirill
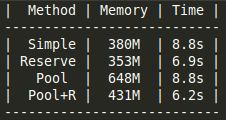
В продолжение вчерашнего обсуждения про выделение памяти.
Я решил попробовать использовать boost::fast_pool_allocator для std::unordered_set. Время выполнения не изменилось, зато памяти сожрало почти в два раза больше, чем с обычным аллокатором.
Kirill
 Kirill
Kirill
Потом я попробовал делать reserve перед заполнением и перебрал 4 варианта:
Kirill
Хотя время я некорректно измерял :(
Алдар
не помню точно, вроде unordered set это массив списков
Ned
Kirill
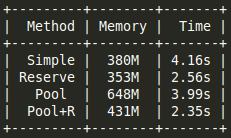 Kirill
Kirill
Перемерил.
Kirill
То биш, если вне зависимости от возможности вызова reserve(), смысла в fast_pool_allocator почти нет.
Алдар
в чем задача состоит? я пропустил
Kirill
Есть файл с большим количеством строк. Нужно из этих строк вычленять нужную часть и записывать в хеш-таблицу для быстрого поиска после.
Kirill
Замес в том, что для хранения данных из файла 172 МБ (а вычленяется половина из него, т.е. 86 МБ) почему-то расходуется больше 300 МБ ОЗУ.
Алдар
поиск просто по строкам?
Kirill
Ну да. Нужно быстро определять, есть ли искомая строка в файле.
Алдар
https://ru.wikipedia.org/wiki/%D0%A4%D0%B8%D0%BB%D1%8C%D1%82%D1%80_%D0%91%D0%BB%D1%83%D0%BC%D0%B0
Kirill
И как бороться с ложноположительным результатом?
Алдар
По сравнению с хеш-таблицами, фильтр Блума может обходиться на несколько порядков меньшими объёмами памяти, жертвуя детерминизмом. Обычно он используется для уменьшения числа запросов к несуществующим данным в структуре данных с более дорогостоящим доступом (например, расположенной на жестком диске или в сетевой базе данных), то есть для «фильтрации» запросов к ней.
Kirill
 Kirill
Kirill
Но все же интересно, почему такие накладные расходы у unordered_set.
Kirill
Надо бы еще проверить его на long int вместо string.
 Andrey
Andrey
Но все же интересно, почему такие накладные расходы у unordered_set.
http://stackoverflow.com/questions/9375450/stdunordered-map-very-high-memory-usage
Kirill
Я видел
Kirill
Там нет объяснения, почему столько требуется.
Алдар
Просто в реализацию залезть посмотреть, вроде там массив списков, на список еще накладные расходы
Алдар
можно самому реализовать хеш с иным разрешением коллизий
Andrey
ну да, можно и свой написать, с оптимизацией под частный случай
Andrey
мож поменьше памяти нужно будет