 Yuf
Yuf


tcp
Yuf

 Logan
Yuf
Logan
Yuf
Баку Ростов
Yuf
?
 Jev
Jev
Есть для этого hystax
Jev
Российский
Jev
@nssven
Jev
@AlexanderChadin привет
 Alexander
Alexander
@feranicus салют
Yuf
 Yuf
Yuf
Что за hystax
Yuf
http://www.cnews.ru/news/line/2017-05-15_atlex_i_hystax_razrabatyvayut_otechestvennuyu_platformu
 Artem
Artem
https://www.openstack.org/assets/presentation-media/Enable-GPU-virtualization-in-OpenStack.pdf
Artem
Ребята как это работает? Вместо cpu мы получаем gpu-ушные ядра? Или это тупо проброс?
Jev
@nssven
Jev
Раскажи тут о продукте dr & Migration
 Radik
Radik
Ребята как это работает? Вместо cpu мы получаем gpu-ушные ядра? Или это тупо проброс?
Если я все правильно понимаю, в вм пробрасывается виртуальное графическое ядро. Программным методом.
Radik
И это не вместо, а в добавок к.
Radik
Для граф.вычислений
Artem
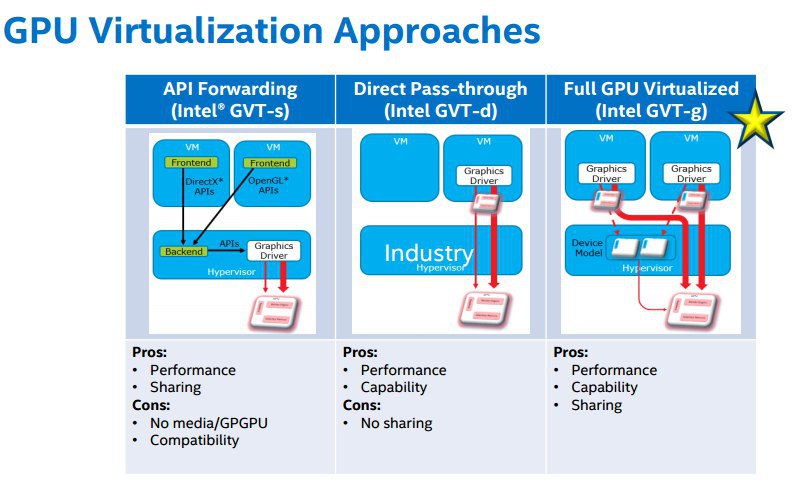
 Александр
Александр
Процентное соотношение дерьмо
Александр
Да я про гпу
Александр
В пдф цифры 80% если не ошибаюсь
Artem
В пдф цифры 80% если не ошибаюсь
Ну да и бог с ними. На последней картинке Full GPU Virt, что по итогу означает?
Александр
Это скорее подразумевает что оно будет работать
Александр
Ты посмотри, на двух из вариантов чего-то нет
Александр
Типа шаринга
Александр
А в третей есть
Artem
Ну типа openstack server create на гипервизор с типом gpu и развернется виртуалка с процессором на gpu?
Александр
Ну там же показано, внутри драйвер ГПУ должен быть, так что скорее всего нужны аргументы
 Nick
Nick
Что за hystax
Занимаемся Disaster Recovery и миграцией, в обоих случаях преимущественно из VMware в OpenStack, но поддерживаются разные варианты исходных и target платформ. Одной из основных плюшек DR для vmware в OpenStack является отсутствие VMware (соответственно, необходимости покупать вторую копию vmware лицензий) на DR площадке, что серьезно уменьшает стоимость Disaster Recovery для компаний. Если интересно, могу подробней в личку написать.
Yuf
да интересно
 Vyacheslav
Vyacheslav
Коллеги, а у нас тут была компания, которая биллинг для OS делает
Есть ASD tech из Нижнего. Ты их сам знаешь ;)
Radik
Слава, они уже есть в моем курсе :)
Radik
А ту вторую я уже нашел, спасибо )
Radik
Возможно даже сведу вас вместе, вдруг чего путного получится. Все таки bossa хороша. До сих пор хочется ее куда-нить применить.
Если не найду, придется свое облако строить, чтобы удовлетворить интерес ))
 Mike
Mike
Занимаемся Disaster Recovery и миграцией, в обоих случаях преимущественно из VMware в OpenStack, но поддерживаются разные варианты исходных и target платформ. Одной из основных плюшек DR для vmware в OpenStack является отсутствие VMware (соответственно, необходимости покупать вторую копию vmware лицензий) на DR площадке, что серьезно уменьшает стоимость Disaster Recovery для компаний. Если интересно, могу подробней в личку написать.
Судя по документам, это по сути бекап на свою площадку.
Nick
Судя по документам, это по сути бекап на свою площадку.
В момент наступления аварии делается DR на резервной площадке, то есть на ней поднимается инфраструктура с процессом V2V, сохранением сетевых настроек, оркестрацией и т.д. Как просто cloud backup тоже можно использовать
Mike
В момент наступления аварии делается DR на резервной площадке, то есть на ней поднимается инфраструктура с процессом V2V, сохранением сетевых настроек, оркестрацией и т.д. Как просто cloud backup тоже можно использовать
Этого в документах нет. И кстати если делается v2v из VMware в KVM - клиентам печать и боль.
Anonymous
Ну там же наверняка заявлен какой-то SLA, магии не бывает в гетерогенных дискретных системах
Mike
Дело не в магии. Сидел клиент с vbc в VMware - бах, сменились IP, переехало на KVM и оренстек.
Mike
У меня бы инфаркт случился от этого.
Nick
Этого в документах нет. И кстати если делается v2v из VMware в KVM - клиентам печать и боль.
Ок, в документах сделаем описание более явным. IP и MAC адреса остаются как и на vmware
Anonymous
А где-то там внутри градация сервисов по классическим типам сервисов из ITIL учитывается при миграции?
Nick
Anonymous
Ну вот есть у кастомера mission critical, business critical и office productivity с dev/test сервисами.
Anonymous
Ведь надо как-то учитывать, что первым перевозить. Особенно когда RTO для всех них разный.
Nick
Это вполне учитывается при прописывании DR плана, в котором указывается очередность и правила оркестрации
Anonymous
Зачем кастомеру работающий офис и системы мониторинга, когда у пользователей нет сервиса? :)
Anonymous
А, ок
Nick
Я вас сразу не так понял, сори. Отвечая на вопрос - учитывается
Anonymous
Отлично, а каким образом тогда выдерживается RTO, если от dc кастомера до резервного dc плохие медленные каналы? :)
Nick
Вы, вероятно, про RPO. Через WAN оптимизацию и дедупликацию на стороне клиента / продакшна
Nick
То есть из того, что изменилось между репликациями, реально шлются только те блоки, которых еще нет в сторедже
Nick
Хранилке снапшотов
Anonymous
Нет, я именно про время восстановления. Потерянные данные пока не интересны.
Anonymous
Но wan optimization - это хорошо.
Nick
Снапшоты хранятся на DR площадке, рядом с OpenStack, в момент аварии нам не важен канал межу ЦОДами
Nick
мы автономно все поднимаем на DR стороне
Anonymous
А, то есть постоянная синхронизация, ок
Nick
да
Nick
с обозначенным RPO
Nick
либо по расписанию, либо near-realtime, когда новый снапшот после предыдущего идет
Anonymous
Реплики через промежуточный какой-то хост?
Nick
нет, напрямую на DR площадку
Anonymous
Ну вот backup dc на каком-нибудь старом 3PAR, а кастомер на модном-стильном-молодежном SDS от infinibox, например. Как реплику делать?
Mike
Печалит то, что у вас своя площадка, с своей схд и магией.
Anonymous
То есть фокус решения на DRaaS, ага?
Mike
И надо везде обмазаться вашими агентами в своей инфраструктуре
Nick
Тут много факторов, которые могут спасти в этой сложной ситуации: во-первых, wan-оптимизация и дедупликацией, во-вторых, можно RPO разный настроить, в-третьих, все-таки на DR площадку совсем древности не нужно ставить, им в случае аварии вашу инфраструктуру какое-то время тянуть
Nick
Печалит то, что у вас своя площадка, с своей схд и магией.
Площадка у нас как раз не своя, мы софтверная компания, площадки делаем или с партнерами или on-premise
Anonymous
Ну я спрашиваю, никакой коробки, просто предоставляется резервный DC с конвертерами на случай аварии у кастомера, да?
Nick
И надо везде обмазаться вашими агентами в своей инфраструктуре
Из агентов нужно поставить один linux box на каждый ESXi хост и все, он на автомате будет протектить инстансы на том же хосте
Anonymous
Ну и, соответственно, большая преподписка по капасити ресурсов между кастомерами в резервном DC. Так как вероятность дизастера, всё же меньше, чем в легаси облачном бизнесе.
Nick
Ну я спрашиваю, никакой коробки, просто предоставляется резервный DC с конвертерами на случай аварии у кастомера, да?
Никакой коробки. Кастомер или дает HW, на который будет делать DR, или с HW / OpenStack вендорами билдится клауд, на который ставится решение. Или DR в клауд партнеров, например Atlex.ru
Anonymous
Ооок, спасибо :)
Nick
Ну и, соответственно, большая преподписка по капасити ресурсов между кастомерами в резервном DC. Так как вероятность дизастера, всё же меньше, чем в легаси облачном бизнесе.
Да, но здесь всегда предупреждаем, что в случае аварии, инфраструктуре еще работать нужно и сильно переподписывать не стоит
Anonymous
и животрепещущий вопрос: кто-нибудь уже использует prometheus для мониторинга nfvi?