Почему чтобы посмотреть видео, надо ее скачать ? Раньше вроде такого не было, или у меня что-то в настройках неправильно
питон какой версии?
 Artur Rakhmatulin
Artur Rakhmatulin

 Anonymous
Anonymous
То есть у вас не так. Ок буду искать
Artur Rakhmatulin
То есть у вас не так. Ок буду искать
я думаю зависит от "типа". если дали ссылку на ютуб, то можно и перемотать. а если файл, то качай. хз. я не против такого
 Pavel
Pavel
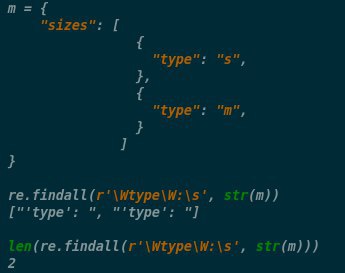
sum(bool(x.get('type', str())) for x in my_json.get('sizes', list()))
новичок Николай решил помогать другим новичкам?
Artur Rakhmatulin
я думаю это конкурс на самое неоптимальное решение
Artur Rakhmatulin
надо одним потоком сохранять в гугл таблицах, а другим читать 🤔
 Nikolay
Nikolay
 Nodaa
Nodaa
"sizes": [
{
"type": "s",
},
{
"type": "m",
}
]
m = {
"sizes": [
{
"type": "s",
},
{
"type": "m",
}
]
}
str(m).count('type')
 Tigran
Tigran
🤦♂️
 Loadi
Loadi
 Pavel
Pavel
странных решений контест :)
Aleksey
Крч , умников всегда больше чем решений )
Tigran
сделать count через regularExpression ?
какой regular expression? у тебя всё сломается, если слово text внутри контента встретится
Pavel
есть еще Counter, кстати
Nodaa
какой regular expression? у тебя всё сломается, если слово text внутри контента встретится
мы же знаем как устроена Ключ и Значение ('key': 'value')
Nodaa
json же
Nodaa
это не Чел пишет криво
Tigran
мы же знаем как устроена Ключ и Значение ('key': 'value')
но никто не говорил, что не может быть "sizes": [{"type": "type"}]
Nodaa
но никто не говорил, что не может быть "sizes": [{"type": "type"}]
именно "sizes": [{"type": "type"}], а не "sizes": [{"type": "type": "type"}]
Tigran
ну и?
Tigran
.count('type') не работает
Tigran
ответ очевиден, твоё решение неправильное и надо сделать по-другому
Tigran
но через re тоже корректно не сделаешь.
Tigran
надо парсить json парсером json и идти циклом
.
Вопрос не по Пайтону, но надеюсь на вашу помощь. Подскажите по структуре:
есть посты, к которым могут прикрепляться файлы, которые можно просматривать с информацией об их размере, оригинальном имени и саму ссылку на файл. Файлы само собой можно прикреплять при создании поста, при его редактировании можно и добавлять и удалять привязанные файлы.
Сейчас это реализовано так: есть API метод files.upload, через который загружается файл, в результате файл загружается в хранилище а в базе создается запись с метаданными файла и ему выдается айдишник. Полученные айдишники файлов можно передать при создании/редактировании поста в виде массива айдишников. В результате чего будет созданы записи в отделную таблицу attachments со связью в виде post_id - file_id. При получении поста, таблица attachments джоинится с таблицей файлов по ключу file_id для получения метаданных прикрепленных файлов. При удалении прикрепленного файла, вызывается метод attachments.delete, который удаляет запись из таблицы attachments.
Нормальный вариант? Или есть получше?
files.upload также используется для загрузки каких либо других файлов на сайте (фото профайла, аватарка группы, и т.д.)
Tigran
Нормальный вариант, а разве видны какие-то проблемы?
Не упомянута только чистка хранилища при удалении метаданных.
Anonymous
sum(bool(x.get('type', str())) for x in my_json.get('sizes', list()))
get страшно медленный как минимум в двойке. Я теперь его боюсь
Pavel
get страшно медленный как минимум в двойке. Я теперь его боюсь
вот бы бояться косяков двойки за 9 месяцев до конца её жизни :)
Pavel
Жить она еще будет долго.
я не спорю. некоторые люди до сих пор под 2.6 ядро модули пишут, например. так что и второму питону еще долго где-то присутствовать ничего не помешает
 Dima
Nodaa
Dima
Nodaa
ломается на "type": ":type:: "
Божечки, либо тип есть либо нет. Думаешь тип может быть ":type:: " ?
Tigran
Божечки, либо тип есть либо нет. Думаешь тип может быть ":type:: " ?
Ну если это JSON от пользователя, я могу впихнуть в него что угодно.
Tigran
Зачем отстаивать своё хуёвое решение с регулярками, когда можно просто распарсить JSON?
Artur Rakhmatulin
import json; import re; my_json = {"sizes": [{"type": "s",},{"type": "m",}]}; print(len(re.findall('(\{\"type\"\:\s*\"\w+\"\}\,{0,1})', json.dumps(my_json))))
Pavel
Божечки, либо тип есть либо нет. Думаешь тип может быть ":type:: " ?
чито технически там может быть что угодно, включая вложенный словарь произвольной глубины со множеством повторений type
Vladimir
Регулярки для разбора JSON — это божественная херота
Tigran
import json; import re; my_json = {"sizes": [{"type": "s",},{"type": "m",}]}; print(len(re.findall('(\{\"type\"\:\s*\"\w+\"\}\,{0,1})', json.dumps(my_json))))
Добро пожаловать в мир хуёвых решений. Хуёвые решения — спасибо за уделённое время, мы вам перезвоним.
Anonymous
Добро пожаловать в мир хуёвых решений. Хуёвые решения — спасибо за уделённое время, мы вам перезвоним.
А на вид прикольно смотрится. Прямо как в перле😍
Nodaa
Не хотите Как хотите
 Sergey
Sergey
Сейчас пишу код для распознавания таблиц и их содержимого в отсканированных документах (на вход pdf, на выход json со строками и столбцами таблицы). Текущий подход - обнаружение контуров, вырезание ячеек как отдельных изображений и прогон через тессеракт. Проблема в том, что иногда даже после предобработки таблицы обрабатываются либо скошенными, либо с нерегулярными разделительными линиями, что нарушает порядок при использовании текущего метода сортировки ячеек (лист 1 до N, где потом тессеракт обнаруживает текстовые поля и принимает их за заголовки колонок, которые заполняются содержимым ячеек между заголовочными)
Вот код используемой сейчас сортировки сверху вниз, слева направо
def sort_rect_vertical(cnts):
rect = [cv2.boundingRect(c) for c in cnts]
rect.sort(key=lambda b: b[1])
line_bottom = rect[0][1]+rect[0][3]-1
line_begin_idx = 0
for i in xrange(len(rect)):
if rect[i][1] > line_bottom:
rect[line_begin_idx:i] = sorted(rect[line_begin_idx:i], key=lambda b: b[0])
line_begin_idx = i
line_bottom = max(rect[i][1]+rect[i][3]-1, line_bottom)
rect[line_begin_idx:] = sorted(rect[line_begin_idx:], key=lambda b: b[0])
Мне хотелось бы спросить, как лучше доработать этот код для расфасовывания ячеек по столбцам.
Pavel
это самый плохой способ
 Savva
Savva
С той, что на фотке и код подсвечивается, таббуляция не сбита и строки не переносятся
Sergey
Сейчас отскриню.
Pavel
 Denis
Denis
 Anonymous
Anonymous
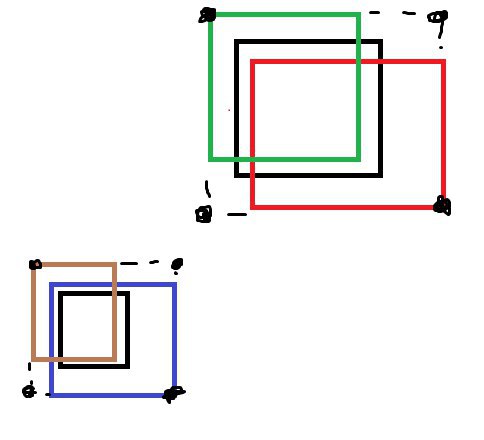
есть список в котором описаны прямоугольники, некоторые из них накладываются друг на друга
нужно выписать координаты мест где есть прямоугольники
как это сделать?
Anonymous
 Aragaer
Aragaer
а что сделать, если бы был прямоугольник, накрывающий левую нижнюю точку верхней группы и правую верхнюю нижней?
Pavel
Pavel
мультиполигон что ли?
Pavel
гугли по словам geomety; unary_union
 Alexey
Alexey
Так получается что умение решать задачки на бумаге "магическим" образом мапится на умение решать описанные ниже проблемы.
Про наши реальные задачки. Зачем нужно знать алгоритмы.
Могу рассказать про то чем занимается моя группа. В соседних группах проблемы другие, но сложность задач не ниже.
Внешне предметная область кажется достаточно простой: https://habr.com/ru/company/yandex/blog/428972/
Но кроме поддержки особо сложных сценариев, есть много технических проблем: https://habr.com/ru/company/yandex/blog/429956/
Часть проблем:
1) даннные/события нужно обрабатывать near realtime. В мире это называется Stream Processing. Даже если вам это не нужно, все равно полезно почитать https://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying
2) обработка событий завязана на состояние. Текущее состояние + событие -> новое состояние + результирующие события. Для старта можно почитать здесь: https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-101 и https://www.oreilly.com/ideas/why-local-state-is-a-fundamental-primitive-in-stream-processing. У нас используется много хитрых техник кеширования в памяти. Чаще всего LRU кеши с восстановлением состояния при необходимости.
3) данных достаточно много. Тысячи пре/посткоммитных проверок в день. Сотни тысяч сборок и тестов * кол-во поддерживаемых платформ.
Здесь можно использовать различные техники сжатия. Например словарь int -> int можно очень хорошо сжать, если сортируем пары key-value по ключам, далее считаем дельты, затем zigzag encoding для значений, затем varint.
и т.д.
Pavel
ну куда нападали прямоугольники - обводим, и возвращаем xy точки
ну да, мультиполигон, стало быть.
Pavel
какие-то требования к решению предъявляются? если нет, бери shapely и вперед :)
Pavel
или тебе bounding box'ы пересекающихся групп нужны (картинка на это намекает)
Дмитрий
Хочу начать внедряться в питон.
Какая иде лучше полноценная visual studio или pycharm?
Главные требования это отладка, intellisense
Anonymous
или тебе bounding box'ы пересекающихся групп нужны (картинка на это намекает)
я плохо объясняю) надо как на картинке
 Ivan
Pavel
Ivan
Pavel
я плохо объясняю) надо как на картинке
ну смотри. если с нуля делать, тебе нужно:
1. выделять группы прямоугольников, которые пересекаются
2. находить для них ббоксы
есть библиотека shapely, в которой этот функционал есть.
но вообще это совершенно базовая геометрия и её несложно написать самостоятельно
Sergey
В дополнение к своему вопросу выше: сейчас есть идея обнаружить горизонтальные разделительные линии и нарезать изображение на фрагменты, заключенные между их парами, а только потом уже нашинковать строки на ячейки. Вопрос в том, как это можно сделать, если а) изображение слегка повернуто и б) справа/слева от большинства горизонтальных линий есть вайтспейс.
Sergey
 Дмитрий
Дмитрий
pycharm
в чем у него преимущества по сравнению со студией? Мне он показался очень тормазнутым