 Roman
Roman


после прототипности js кажется цветочками
 Snusmumriken
Snusmumriken
Ну, это да. С декораторами питона тоже.
Благо, ни один язык в мире не может запретить писать говнокод, и что-то сложное на чём-то казалось бы простом тоже будет всегда.
Roman
> Благо, ни один язык в мире не может запретить писать говнокод
Говнокодер детектед :)
Snusmumriken
Ох, ты так мил :3
Кажись я ещё один детектор сломал, прости, я вышлю тебе компенсацию.
Суть в другом: если основные инструменты языка просты - это отлично, но ничего не значит.
Если основные инструменты сложны и не очень естественны - это может намекать на то что разработчики языка - упоротые чуваки.
Roman
Я это со всем уважением, если что. Чего бы мне доказывать что-то великому луа писателю, но не соглашусь! Если основные инструменты языка просты (луа) и при этом он гибкий и мощный (луа), то это значит одно очень важное! Что он чертовски здорово спроектирован, сравнивать могу только с js, потому что они похожи, а питон совсем другой, так вот js отличный пример паршивого проектирования. Ну то есть он простой и это нифига не значит - нетушки, благодарным нужно быть католикам бразильским.
Snusmumriken
Глянь эту штуку.
Я её уже несколько раз скидывал сюда, но думаю, пора её закрепить наверху.
http://russian.joelonsoftware.com/Articles/LeakyAbstractions.html
Это проблема всех высокоуровневых языков. Вопрос количества "течей" в стандартной библиотеке.
Roman
читал, дырявые абстракции, суть вообще не уловил
Roman
абстракции это добро, нужно готовить уметь
 Tverd
Tverd
В js очень много легаси, и не решаются убрать оттуда это все что осталось с прошлых веков )
Tverd
это и =, ==, ===. И NaN, null, Undefined
Snusmumriken
Суть в том, сколько всего нужно знать, чтобы сделать что-то хоть на шаг отходящее от задуманного.
В луа, дырявой абстракцией можно считать хеш-таблицы, а конкретно - их порядок.
Ну, если попробовать пройтись через pairs по key-value-табличке, то их порядок будет совсем не тем, который ожидался. Я бы даже сказал что он будет совершенно неизвестным, и меняющимся при добавлении нового элемента, и иногда перемешивающимся полностью.
Например, другой пример. Нам надо прочитать первые 5 000 000 строк в файле на 100500 гигабайт.
Если мы будем это делать так:
local s = ''
for line in file:lines() do
s = s..line
end
Мы столкнёмся с тем, что файл будет считываться часами.
А если
local s = {}
for line in file:lines() do
s[#s+1] = line
end
s = table.concat(s)
Мы ускорим процесс в несколько сотен тысяч раз. На самом деле, на мелких файлах разниза незаметна, но в первом случае - скорость растёт по экспоненте пока заканчивается оперативка, а во втором - линейно.
А всё потому что строки в луа - хешируются, и вообще статичны, а при конкатенации - старые строки выбрасываются в мусор.
Это тоже дырявая абстракция.
Tverd
можно в каждом цикле дергать сборку мусора
Snusmumriken
Это будет ещё медленнее, ибо сборщик в луа довольно глупый, и будет елозить по почти всему дереву объектов. И чем их больше тем медленнее. Авось на сутки-двое растянешь.
Roman
это и =, ==, ===. И NaN, null, Undefined
хм, это никак не легаси, это убирать никак нельзя
Tverd
Я бы попробовал все таки ))) Понятно что конкат будет намного быстрее, но в первом примере можно что-нить поковырять
Snusmumriken
Так вот. Чтобы писать на высокоуровневых языках не совсем страшные вещи, приходится знать довольно много мелких тонкостей.
Чем больше тонкостей - тем сложнее писать на языке.
В жаваскрипте - чтобы быть мастером, нужно знать очень, очень много тонкостей, иначе то что будет на выходе - окажется медленной фигнёй. Бытие ниндзей жаваскрипта - вынужденная мера.
Tverd
это и =, ==, ===. И NaN, null, Undefined
хм, это никак не легаси, это убирать никак нельзя
Это даже не легаси? ))))))))))))))))) Тогда все еще хуже )
Roman
то есть это фича, а не баг, undefined это как nil в луа, null это как nil в других языках, NaN это из стандарта про числа, == и === это да, зря так сделали, = очень полезный символ
Snusmumriken
Быть мастером в луа гораздо проще чем в жаваскрипте, причём не только потому что сама луа меньше течёт, но и потому что, простите, на луа мало библиотек и фреймворков. Как только язык становится популярным, появляются фреймворки, и многие из них пишутся кем попало, в результате те начинают течь ещё хуже чем язык. И такое бывает довольно часто.
Страшно представить, что будет если луа окажется такой же популярной как жаваскрипт.
Tverd
то есть это фича, а не баг, undefined это как nil в луа, null это как nil в других языках, NaN это из стандарта про числа, == и === это да, зря так сделали, = очень полезный символ
Мне кажется просто все привыкли и считают это нормальным. Хотя в других языках без этого обходятся
Snusmumriken
В луа, кстати, тоже есть nan, правда до него ещё надо докопаться. И inf.
Roman
Снусмумрик (это ведь персонаж из мультика?), спасибо за пример с файлом, и правда за абстракциями глаз да глаз
Snusmumriken
Это персонаж книжки, по которой сняли мультики.
Есть ещё кеширование для ускорения процесса, чтобы не искать по 100500 раз одно и то же. Это аналогично ускоряет, но его не должно быть слишком много. Всё в меру.
 Anonymous
Anonymous
Мало того, у меня был случай, когда file:lines() не заработал на клиентской машине. io.open - ok
Snusmumriken
Там есть file:seek(), которым можно двигать курсор чтения по файлу. Можно мутить свой кастомный итератор даже по терабайтным файлам.
Roman
Подскажешь как правильно читать файлы в openresty, которые multipart приходят?
Roman
Я просто беру да и читаю в строку, конкатанирую, понимаю, что это очень тупо
Snusmumriken
Тебе файл нужен в загруженном на сервер виде?
Потому что если загружать мультипарт асинхронно, там нарушается порядок принятия кусочков файла и их надо выстраивать, а если файл большой - сразу грузить на хард.
Есть режим открытия файла 'append', который дописывает нужный кусочек в конец файла, не перезатирая начало, в отличии от w/wb.
Roman
то есть в форму загружаю картинку, картинка идет на сервер, а дальше момент плохой - из параметров в строку, из строки в файл
Snusmumriken
Давай сразу в файл, по кусочкам.
Если они упорядочены - всё проще.
Snusmumriken
Как ты принимаешь кусочек файла? У тебя там хендлер?
Roman
браузер посылает
—пыщьпыщьэторазделитель
key
value
Roman
key = просто имя, value - может быть фильм blue ray
Snusmumriken
Ой, скинь на pastebin.com кусок кода.
В котором хранение файла и его приём.
Roman
а в принципе как это в идеале должно быть
Roman
так все, зря людей отвлекаю
Roman
у resty upload есть размер чанка, и все решено
fgntfg
https://pastebin.com/3q9uP7CG
fgntfg
Вот код
 B
B
странный вопрос но кто то знает как из каши 01101010101010 и тд тп делать информацию?
хотя тут же скорее вопрос к глубоким вещам и железу, ведь по сути на хдд информация представлена в таком виде но мы ей пользуемся в удобном для нас виде, один набор единиц и нулей это текстовый файл второй это какой то видосик
Roman
делал адаптер постгреса, сначала инт - длина сообщение, берешь 2 байта (вроде 2), читаешь длину, потом берешь это число байт и превращаешь в строку, вот так и работает
B
не мне наверно там нжно совсем в ином направлении как именно происходит процесс понимания того что вот это
10101011
это к примеру видео, а вот то
010010111
это текстовый файл (образно говоря) и все в таком ключе
Roman
вопрос чисто к документации формата этого сообщения, закодировать таким образом можно данные абсолютно любого вида любой сложности, и при посылке по сети можно читать по кусочкам, гениально и производительно
Roman
лол) 101010 это последовательность нулей и единичек, не более :) а что оно такое - решать тебе
B
ну вот а каким образом, как происходит этот "волшебный" процесс сборки в то что нужно?
Roman
если хочешь изобрести формат посылки видосов или текстовых файлов - пусть сначала идет буква - V - видос, T - текстовый файл, берешь 1 байт ASCII, потом длину, и потом уже знаешь и что это такое, и длину
B
всьо ни то
Roman
чиво
Roman
для ленивых есть json, на худой конец xml
Snusmumriken
Карочи, дело как всегда в формате.
Просто так определить формат того же бинарного файла не представляется возможным, без буквочек расширения или сигнатуры файла.
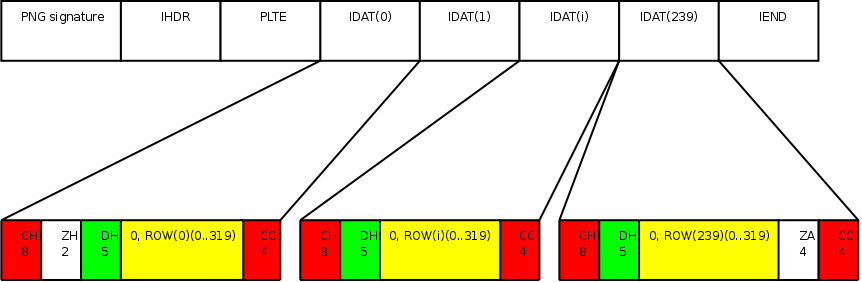
Например, у картинок PNG есть сигнатура PNG в сообщении. У zlib и deflate тоже есть свои сигнатуры. Это типа "уникальный идентификатор формата с опциональной мета-информацией" в начале файла.
Snusmumriken
А дальше может быть что угодно, в следствие формата.
Snusmumriken
 B
B
ага, яснопонятно
Snusmumriken
Каждый файл - мешанина битов которые можно раскодировать. Это всё что тебе нужно знать.
Кодировать - тоже можно. Преобразуй цифры в биты (string.char для чисел 0-255, и свои алгоритмы для многобитовых чисел)
 mva
mva
почему мне кажется что вы переизобретаете libmagic?
B
значит что к примеру с группой файлов разом работать не выйдет, потому как в конце может не быть возможности получить что нужно?
Snusmumriken
Предупреждаю, что не все форматы имеют сигнатуры.
И выбор сигнатуры должен быть специфическим.
Например, у меня есть свой формат RUDP-сообщений (для пересылки UDP-сообщений большими пачками).
Можно быстро определить, является ли данный пакет RUDP-пакетом, вырезав из него несколько бит.
Snusmumriken
 mva
mva
в 70% случаев можно определить файл по первым 10 байтам :)
Snusmumriken
Угу, автоопределители всяких MIME-типов так и делают.
Но это прокатывает далеко не всегда.
mva
повторю отсылку на libmagic :)
mva
у неё целый пучок алгоритмов
Snusmumriken
Пучок, которого хватает не на всё, потому что я завтра могу изобрести новый формат.
Но да, под всё что распознаётся браузером - там есть детекторы. Но браузер сам по себе не так много умеет воспринимать.
Например, оно не знает что такое erx-формат. А некоторые люди пользуются им очень часто. И так просто его не распознаешь - он вообще закрытый и обфусцированный.
Snusmumriken
У себя на работе, для открытия doc-документов, есть lua-модуль связи с COM, который открывает документы фоном в ворде, вытряхивает данные из процесса ворда и идёт дальше. И это - следствие стрёмности реализации формата, мол, такое решение быстрее, чем мудрить свои декодеры.
Но сама суть довольно смешная. Например, скрипт которому присылают тысячи вордовых документов в день на парсинг. Ворд открывается и закрывается каждую секнуду.
Roman
Возможно, torch поможет с этим :)
Snusmumriken
Там в качестве основной виртуалки не luajit.
B
Просто что интересно, каким макаром работают всякие компрессоры
Snusmumriken
Хех, когда я пытался изобрести формат сжатых файлов, я делал его как связный список:
[мета-информация файла (например, длина)]
[бинарные сжатые данные]
[мета-информация следующего файла]
[бинарные сжатые данные]
Быстро узнать всё содержимое - просто.
Считываем мета-информацию с начала файла, пока не наткнёмся на сигнатуру конца мета-инфы.
Парсим, декодируем, получаем длину бинарных данных.
Перемещаем курсор чтения файла на длину сжатого файла (перескакиваем через все бинарные данные, ибо у нас есть длина),
Считываем следующий заголовок..
Повторить N раз до конца файла.
Добавить ещё один файл тоже просто: дописываем в конец ещё один заголовок, и ещё одни сжатые данные.
Удалять уже сложнее, нужно переписывать файл.
Зато деревья - просто. В заголовок пихаем путь файла типа /folder/folder2, а при чтении заголовков - восстанавливаем древо-структуру. Правда, перемещать файл внутри архива уже не получится.
mva
да из любых архивов, вроде как, удалять файлы можно только переписыванием...
Snusmumriken
Ну, я в какой-то момент изобрёл зип, да. Если хранить файлы в своём архиве с бинарными заголовками - его становится сложнее вскрывать. Ура, товарищи!
Snusmumriken
Кстати, на тему забавностей форматов.
Кто-нибудь сталкивался с rarjpeg'ами?
Ну, файл который можно открыть как картинку, а можно как архив.
Snusmumriken
Лурка пишет:
>Программы для просмотра изображений анализируют формат JPEG (и многие другие) с начала файла, конец игнорируют. Архиваторы напротив, определяют архив по наличию сигнатуры, которая может находиться где-то в середине файла, так как в начале файла может находиться SFX-модуль архива, который фактически и является приклеенным распаковщиком — по принципу сабжа. За счёт этих двух факторов можно невозбранно слепить картинку и архив в один файл, который приобретёт функциональность обоих кусков.
Надёжность метода хотя и велика, но не 100%: если в середине картинки внезапно встретится сигнатура архива, предваряющая какую-то лажу (а хвост картинки с точки зрения архиватора ничем другим с вероятностью чуть менее 100% быть не может), то архиватор обидится и ничего не разожмёт. Если анонимусу вдруг так не посчастливилось, то помогут (как нетрудно догадаться, тоже не на 100%) выбор другого архиватора или незначительные изменения картинки.
Экспериментальным путем получили симбиозы архива и файлов формата: .wav/.mp3/.aac/.amr, .jpg/.png/.gif, .torrent, .html.
Snusmumriken
Экскурс по бинарным данным можно считать закрытым? Всем желающим понятно происходящее?
Snusmumriken
повторю отсылку на libmagic :)
Тут важно не определить формат, а перевести его в программочитаемый вид и обратно. Libmagic только детектор. С файлом нужно ещё что-то сделать.
https://habrahabr.ru/post/186828/
Aleksandr
 B
B
а насколько это мазохизм если я буду нилить локальные цикловые переменные в конце циклов?
типа
for i = 1, 10 do
local aru = blabla
--magic
aru = nil
end
mva
ну, кроме лишних нажатий на клавиши и лишней работы интерпретатора/компилятора другого мазохизма тут, вроде, нет
Snusmumriken
Лишней работы интерпретатора тут практически нет, а вот лишние нажатия на клавиши - да.
Сборщик мусора сработает когда сработает.
1. Ты можешь сэкономить память и нагрузку на сборку мусора ценой скорости:
local aru
for i = 1, 10 do
if i%2 == 0 then aru = 'bla-bla' end
...
end
2. Тот вариант который ты используешь - несколько быстрее но жрёт больше памяти:
for i = 1, 10 do
local aru = i..'bla-bla'
...
end
Первый способ хорош для неимоверно огромных строк и если они меняются не каждый шаг цикла,
второй - когда строка каждый раз уникальна
Roman
Это уже очень интересно, хочешь сказать, каждый уровень вложенности для поиска переменной ворует скорость?
Roman
А то что lua debug все локальные видит одинаково - ничего не значит?