 Max
Max


Может ты на самом деле не string.find бенчал, а что-то другое 🤷♂
 Snusmumriken
Snusmumriken
Хех, хорошо
Snusmumriken
Ща
Max
Может ты на самом деле не string.find бенчал, а что-то другое 🤷♂
Как например в моём примере выше
Snusmumriken
 Snusmumriken
Snusmumriken
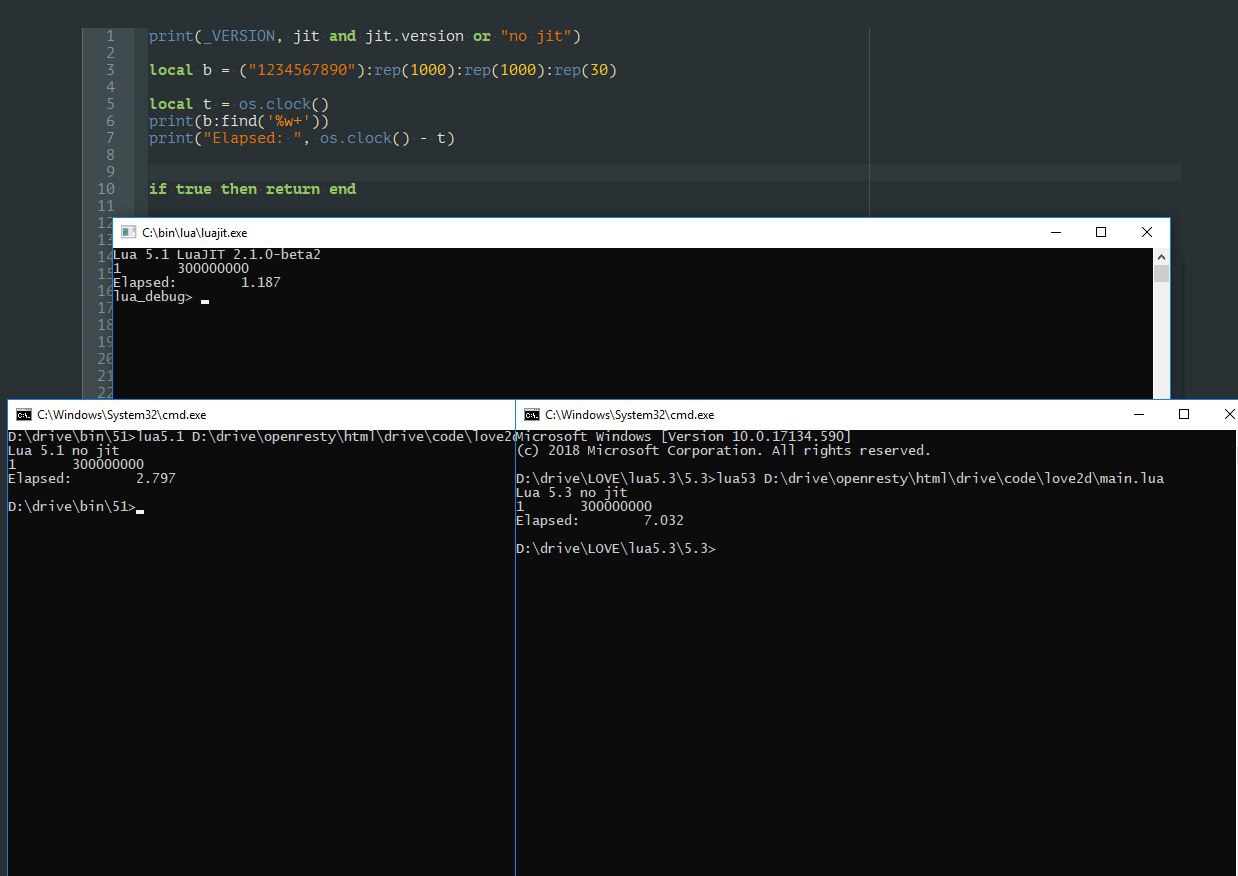
Тут ~300 метров, потому что lua5.1 внезапно отказалась обрабатывать ~500, отмазываясь нехваткой памяти. Врёт.
Все версии 32-разрядные.
Snusmumriken
Так что у луажыта на регулярке прирост всего в ~2.4 раза в сравнении с 5.1, и ~6 раз с 5.3, вот так вот.
Snusmumriken
Да, если что, я прогонял раза четыре каждый, пертурбации системы влияют незначительно, я не открывал параллельно многопоточную обработку видео и не стресс-тестировал цпу/память пока тестил 5.1.
 Anton
Anton
а возможно luajit выгрузить байткод в файл, а потом запустить без перекомпиляции?
Snusmumriken
Нет.
Snusmumriken
Ничего, оно быстро разогревается, всего 500к итераций.
Snusmumriken
И ты наверное имел ввиду не "байткод" а "скомпилированные трассы". Байткод — разумеется можно, но код превращается в байткод один раз на запуске, за две наносекунды. Оптимизировать его превращением в байткод нужно только если сверхчасто запускается новая вм.
 Serezha
Serezha
это ascii поиск или utf-8 ?
Snusmumriken
Очевидно ascii. Луа не поддерживает utf8-классы даже с либами. Там приходится городить
utf8.find(str, "а-яёА-ЯЁ0-9") как замену %w
Serezha
в 5.3 же обещали поддержку или нет?
Serezha
не знаю как у остальных участников чата а для веба аскии поиск вообще неактуален
Snusmumriken
Для веба ещё нужна декомпозиция и нормализация.
Serezha
даже в похапе регулярки корректно работают с ютф8
Snusmumriken
И чаво, находят русские буквы по \w?
Serezha
конечно
Snusmumriken
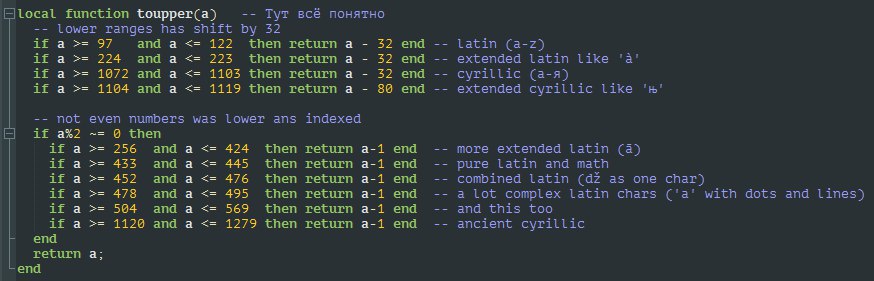
Точно-точно? Потому что табличка классов тогда бы весила обожемой сколько.
А ещё оно отличает ловеркейс той же кириллицы с апперкейсом?
Serezha
это какой то рокет саенс чтоли?
Serezha
уже лет 10 как проблемы детские ютф 8 решены во всех популярных языках
Snusmumriken
 Serezha
Serezha
я работаю в пыхе с юникодом
Snusmumriken
И напиханы все символы в unicode-табличке вразнобой стрёмными блоками, универсальных решений нет кроме как для каждого символа хранить табличку с бешеными флагами, кешировать их и делать ещё много нехороших вещей.
Serezha
согласись зачем нужен язык для веба который не может просто текст разбить на слова
Snusmumriken
А, это легко и без utf8, в любой кодировке.
Serezha
 Serezha
Serezha
это про пхп 7.3. он даже 4 байтовые эмоджи теперь поддерживает
Snusmumriken
И раньше были 4-байтовые символы, и с ними нормально работали.
Snusmumriken
Карочи, напоминаю для бобиков: строки офигеть какие сложные и объёмные. Луа разрастётся в ПЯТЬДЕСЯТ раз, если будет содержать в себе таблички с классами для юникода.
Serezha
в майскл постепенно поддержка улучшалась - есть спец тип таблиц utf8_mb4 для нормальной работы с эмоджами
Serezha
ну я про себя говорю - мне строки без ютф 8 не актуальны никак
 vvzvlad
vvzvlad
в тарантуле есть поддержка utf8
 Serhii
Serezha
Serhii
Serezha
в луа есть либы для ютф8 вот их и надо тестить имхо
Snusmumriken
Не нужно их тестить.
Snusmumriken
Я уже оттестил и всё написал
Snusmumriken
Serezha
так то нечестно сравнивать тупой аскии поиск с полноценными регулярками как во ВСЕХ остальных языках
vvzvlad
правда не уверен, что там есть все что надо
Serezha
иначе рождаются вот такие тикеты https://github.com/openresty/lua-nginx-module/issues/1495
Snusmumriken
так то нечестно сравнивать тупой аскии поиск с полноценными регулярками как во ВСЕХ остальных языках
 Snusmumriken
Snusmumriken
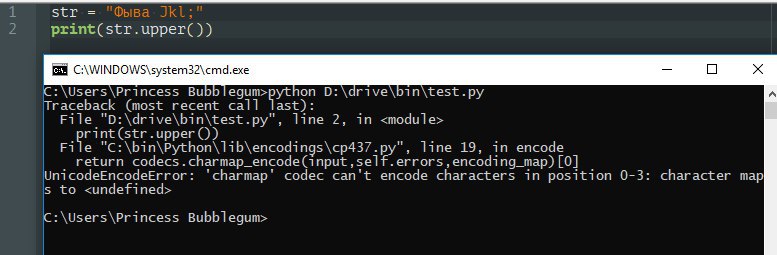
Он даже не может апперить русские буковки в utf8, прикинь?
Serezha
про питон не знаю это третий?
Snusmumriken
Я видел только два языка с по-настоящему полной поддержкой юникода: это жава и C#.
Serezha
вроде в третьем все окей
Serezha
в голанге сразу была полная поддержка
Serezha
там не надо вот так u”Строка” ?
Serezha
что то такое я видел в сроцах
Snusmumriken
То же самое.
Snusmumriken
Расслабься. Ты просто не представляешь НАСКОЛЬКО строки на самом деле сложные и объёмные, почитай и прогугли.
 Pavel
Pavel
python3.6
Python 3.6.1 |Anaconda custom (x86_64)| (default, May 11 2017, 13:04:09)
[GCC 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.57)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> s = "Привет"
>>> print(s.upper())
ПРИВЕТ
>>>
Snusmumriken
Жава, при подрубании модуля строк с нормальным юникодом, разжирается с условно десятка мегабайт оперативки до ~200 ))
Serezha
я знаю поэтому не вижу смысла мерять скорость на аскии текстах
Serezha
я работаю с русским языком в проектах активно
Snusmumriken
python3.6
Python 3.6.1 |Anaconda custom (x86_64)| (default, May 11 2017, 13:04:09)
[GCC 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.57)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> s = "Привет"
>>> print(s.upper())
ПРИВЕТ
>>>
Попробуй запустить скрипт в utf8.
Snusmumriken
Я тоже работаю, в луях, полёт нормальный ))
Комфорт чуть-чуть ниже чем обычно.
Serezha
быстрый поиск по строкам был векторизован еще в древних процессах вроде пентиум про
Snusmumriken
Это быстрый поиск байтов в байтовом массиве, ты понимаешь что это и в чём разница с регулярками?
Serezha
ютф8 все поломал - быстрая и корректная реализация действительно важна
Snusmumriken
Да нет, поломал не ютф8 а сама концепция регулярных выражений. Тут уже одними "векторами" не отделаешься, надо строить конечный автомат со стеком и поиском кучи альтернатив.
 Anonymous
Anonymous
Icu весит мегабайт 40 вроде
Anonymous
Это если нужен полноценный юникод
Serezha
Да нет, поломал не ютф8 а сама концепция регулярных выражений. Тут уже одними "векторами" не отделаешься, надо строить конечный автомат со стеком и поиском кучи альтернатив.
для простого поиска по строкам регулярки не нужны. но в луа вроде нет другого способа в стандартной либе
Serezha
а в том же пыхе огромное разнообразие методов для работы со строками без регулярок
Snusmumriken
Скажи мне мил-человек, что нужно чтобы сделать string.upper по всем возможным вариантам utf8-строки?
Serezha
не знаю мне для поиска это не нужно
Snusmumriken
Для поиска который условно string.find("Абвгдейка")?
Serezha
я потерял нить разговора сорри
Snusmumriken
Карочи, есть подозрение что ты нахватался верхов, не понимаешь как работают твои инструменты, но очень громко вопишь на тему "это всё должно быть так! везде есть и тут надо!". Сорян, но впечатление именно это.
Serezha
я из того поколения снус что застало кодировку 1251 в интернете
Serezha
и все траблы юникода
Snusmumriken
Я на своей основной работе в основном использую 1251. И конвертю входящий юникод в него.
Serezha
поэтому для меня поддержка юникода не пустой звук
Serezha
слишком часто вылезали в проектах вопросики кубики и прочий шлак
Serezha
поддержка как минимум трехбайтовых кодировок - мастхев - а в прошлом году вылезли проблемы с эмоджами в текстах так что теперь считаю что и четыре байта должны обрабатываться корректно
Snusmumriken
Так почему ты до сих пор не разобрался во внутренней структуре кодировок, схемах работы со строками и причинах, почему именно вылезали вопросики и кубики? Я тоже с этим сталкивался, я это фиксил. Я наблюдал лютые иероглифы при нескольких конвертациях cp1251->utf8->utf8 или чего-то такого.