 Maxim
Maxim


выглядит примерно так же
 mva
mva
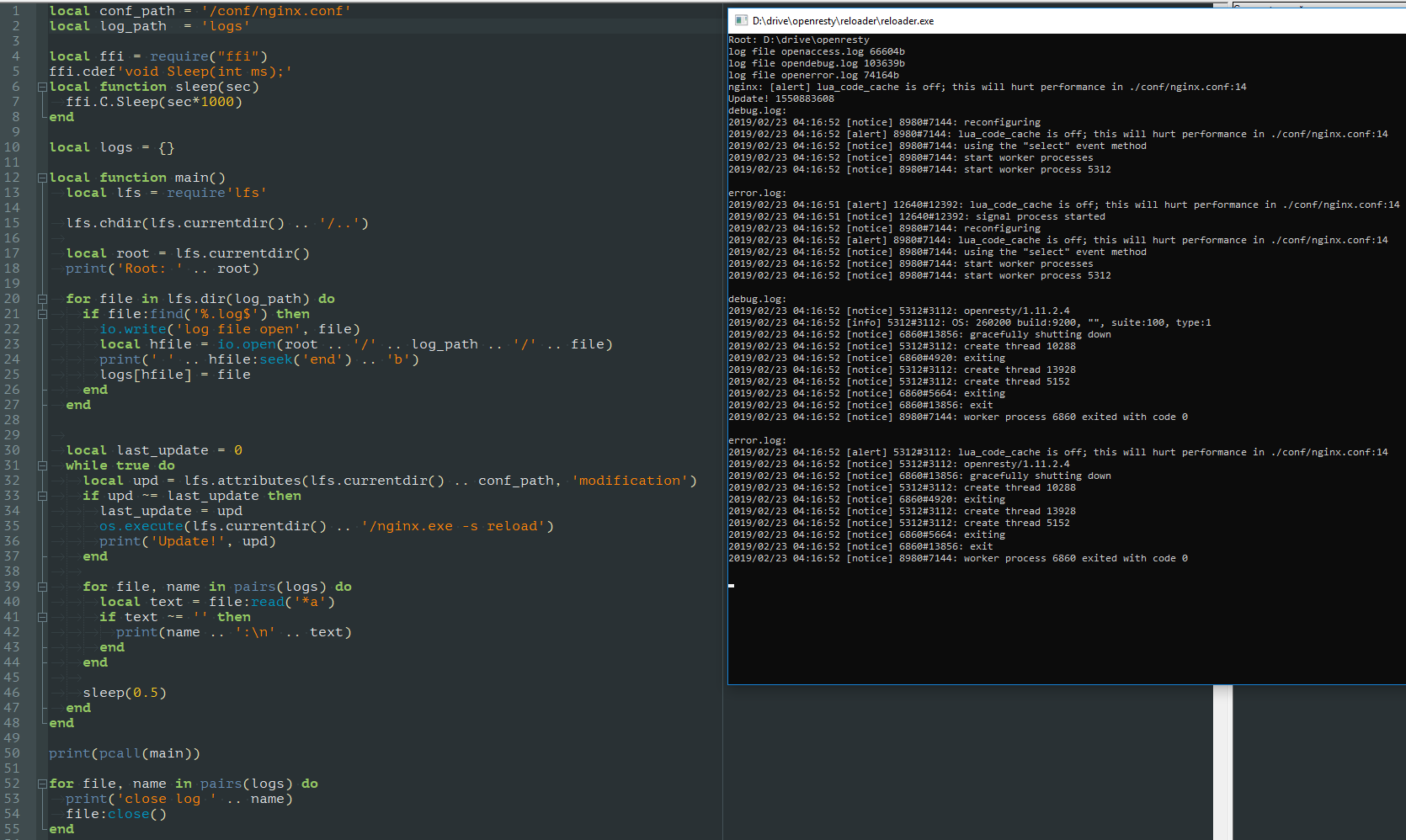
 Snusmumriken
Snusmumriken
фу-ты, ну-ты. Я то уж понадеялся, что там у тебя супер-конфиг для NgX с вставками *_by_lua. А там скрипт, который дёргает nginx -s reload ;) Так я и сам умею 😃
Ну он дёргает по изменениям.
Некоторые пишут shell-скрипты, которые каждую секунду дёргают релоад.
mva
по ушам за такое бить надо :)
Snusmumriken
Да нет, помнится, в документации к нгинксу написано что это норма.
Snusmumriken
А так — извини что не оправдал ожидания, можно было бы круче : )
Допустим, все либы грузятся в shared_dict (переопределённый require), а по сигналу (зашли на определённый урл) — очищаются. Но тут не получится перезагрузить сам конфиг, и это решается просто убиранием кеша луа-скриптов.
Snusmumriken
Ох уж эти контейнеры. Воткнул контейнер и рад, больше ничего не надо.
Snusmumriken
На самом деле не совсем.
Разворачивание и контроль через конфиги — попроще будет (после освоения инструмента), а вот со скоростью — там же виртуализация, она процентов двадцать мощности сжирает. И память кушает.
А вот в наше время, всё bat-никами конфигурировали! А особо умные — sh-никами!
 Dmitry
Dmitry
всех с праздником и чистого неба над головой
Maxim
На самом деле не совсем.
Разворачивание и контроль через конфиги — попроще будет (после освоения инструмента), а вот со скоростью — там же виртуализация, она процентов двадцать мощности сжирает. И память кушает.
А вот в наше время, всё bat-никами конфигурировали! А особо умные — sh-никами!
соглашусь с тем что nginx в контейнере может иметь оверхед по сравнению с nginx прибитым гвоздями к серверу, лично не измерял но раз об этом говорят - значит может быть, но для нашего проекта этот оверхед как экономия на спичках, нам пофигу на эти милисекунды с большой колокольни )
Maxim
А так — извини что не оправдал ожидания, можно было бы круче : )
Допустим, все либы грузятся в shared_dict (переопределённый require), а по сигналу (зашли на определённый урл) — очищаются. Но тут не получится перезагрузить сам конфиг, и это решается просто убиранием кеша луа-скриптов.
для windows, я считаю, у тебя отлично получилось, про sleep ты объяснил подробно и с примерами, на твердую пятерку с плюсом, так что не нужно извиняться
Maxim
@Snusmumriken рассказываю как на нашем проекте мы стараемся не делать. В течении длительного времени мы все задачи решали с помощью php, nginx использовали только для того что бы передать запрос в php-fpm и вернуть ответ, использовали как прокси сервере. но потом мы столкнулись с целым батальоном проблем и отрядом сложностей. например: мы хранили одну картинку в нескольких вариантах по расширению, типа img.png, img.jpeg, img,webp и т.д., а так же мы хранили все обрезки этих картинок так же в нескольких вариантах, поэтому мы не могли точно определить сколько места нужно на диске для картинок, одна картинка в 200Кб превращалась в 2Мб если сложить все её варианты и обрезки, а это считай что требуется в 10 раз больше места на диске чем если бы хранили только один исходник, следующая проблема была с редиректами, когда то давно мы захуячили консольную команду которая ходила в БД за данными по редиректам, создавала redirects.conf для nginx и bash скрипт перезагружал конфигурацию nginx, один в один как у тебя скрипт для windows, только мы еще добавили проверку конфигурации что бы при рестарте nginx не завалился и продолжал работать со старой конфигурацией если новая конфигурация содержит ошибки, мы нарвались на человеческий фактор в этом решении, так как у нас около 10000 редиректов это не удивительно если в одном из этих редиректов наш бравый СЕОшник может допустить ошибку и конфигурация будет нерабочей, ну и соответственно не будет применена, в общем сеошник допустил ошибку заполняя эти редиректы (тупо два одинаковых from создал случайно) и nginx долгое время работал на старой конфигурации, а сеошник получал пиздюлей от руководства за то что его план не работает, а виноват в этом был автор схемы) и таких проблем в архитектуре приложения было очень много, одно из другого вытекающее. ну и как вишенка на торте это тяжелые запросы в базу данных, обработка данных и возврат результата пользователю был очень долгим и крайне раздражал руководство.
Запахло жареным, мы сжали булки и начали скрипеть мозгами так сильно что дрожали стекла в окнах кабинета.
Snusmumriken
Ох блин, ты выспался, а это всё ещё не ответ на вопрос : )
Итак, есть два основных варианта организовать работу, с запросами, считаемыми внешней стороной:
1. Короткие запросы. Это когда мы делаем запрос на сервер, тот, пока считает — возвращает ответ-заглушку, например с ID данного запроса, и говорит браузеру: "пока я обрабатываю — спрашивай меня, не готово ли, посылая мне данный ID".
Пример, как это можно реализовать:
location /api/.* {
content_by_lua_block {
local args = ngx.decode_args(query_str, 0)
-- если нас просят сделать запрос -
-- возвращаем ID данной операции
if not args.id then
local id = GUID()
redis:set("request_"..id, ngx.req.body)
ngx.say(id)
return
end
-- если нас спрашивают, готов ли ответ -
-- проверяем, есть ли он в бд и возвращаем
local response = redis:get("response_" .. args.id)
if response then
ngx.say(response)
else
ngx.say(json.encode{status = "не готово, повтори позже"})
end
}
}
Соответственно, запросы к api могут выглядеть так:
var id = request('site.com/api/service')
А потом ты такой
setInterval( function() {
var body = request('site.com/api/service?id=' + id )
if (JSON.parse(body).status == "done"){
parseResponse(body)
}
}, 2000)
Тут браузер, при каждом запросе, начинает опрашивать сайт по таймеру, и когда придёт ответ — он его выведет, обработав жаваскриптом или ещё как-то.
И второй способ, — длинные запросы, когда пока идёт длительная обработка запроса, соединение не обрывается, браузер ждёт минуту-другую-третью пока не придёт ответ от сервера. Я уже описывал этот способ, он с циклом и ngx.sleep(), пока в базе не появится ответ.
Есть ещё третий способ, через вебсокеты, но сомневаюсь что вы делали что-то подобное, это стрёмно и тянет на "полноценное приложение" а не веб.
Snusmumriken
У вас ведь база — связующее звено, да?
Луа записывает запросы в базу, сервисы читают его там, обрабатывают и записывают ответ в ту же базу же, да?
Snusmumriken
Итак, вопрос знатокам: какой из этих способов используется у вас, и почему?
А если не используется — то что используется вместо этого? Конкретный алгоритм : )
Maxim
У вас ведь база — связующее звено, да?
Луа записывает запросы в базу, сервисы читают его там, обрабатывают и записывают ответ в ту же базу же, да?
Вот сейчас надеюсь ответить на твой вопрос на примере наших редиректов. nginx встречает запрос пользователя и передает его lua скрипту который проверяет наличие урла для редиректа в редиске - это получается один redis:get(URL), если есть данные по этому ключу то lua делает редирект по урлу который вернулся из redis, если данных в redis нету и запрос redis:get ничего не вернул то lua передает управление запросом назад в nginx. lua не пишет ничего в redis в данном случае, только читает и in-memory DB. А вот в эту in-memory DB данные о том с какого URL на какой URL редиректить посутпают из PHP, то есть PHP пишет в redis при успешной записи в БД, а lua из redis читает. Мы стараемся сделать так что бы nginx как можно меньше соприкасался с тяжелыми кейсами.
Snusmumriken
Ага, вот сейчас более-менее понятно. Вот примерно это я и хотел, простой пример схемы работы : )
Ура! Снус получил ответ! Ты молодец!
То есть, у вас простой поллинг, браузер делает кучку запросов на сайт, пока не получает ответ, а в качестве системы сообщений и балансировщика — бд.
Snusmumriken
Кстати, почему нгинкс не грузите? Луаджыт-скриптики вполне себе быстрые, на них можно ставить и тяжёлые кейсы.
У leafo целый движ есть, быстренький!
Snusmumriken
Во, ещё очень страшный вопрос.
Чому не использовали специализированное ПО для месседжей, типа RabbitMQ? Оно специально запилено для такого, типа повышенная отказоустойчивость, очереди, балансировка, статистика и всякое такое.
Ну и да, лонг-поллинг таки экономичнее. Выгоднее держать одновременно кучу запросов, чем постоянно открывать-закрывать соединения. Выставляешь таймауты http-запросов минут на десять и вперёд ))
А то с поллингом на бумаге всё получается очень красиво: "мы обрабатываем миллиард запросов в секунду", не учитывая что 90% создаваемых запросов — очередная попытка получить ответ с минимальными действиями, но на практике, лонг типа быстрее и економичнее, меньше трафика, меньше дёрганий динамической памяти, а ещё куда меньше логов и сами логи прямее : )
Snusmumriken
В общем, если будет время/желание — поэкспериментируйте.
Anonymous
Чем опенрести отличается от нгинха?
Snusmumriken
Опенрести == нгинкс + луа_мод, с некоторыми допилками и оптимизациями луёвой стороны.
Есть и просто луа_мод для нгинкса, но там не настолько круто
Anonymous
Спасибо
Anonymous
То есть все те же задачи можно решить без опенрести?
Anonymous
Просто скомпилировав с мод_луа?
Maxim
Ага, вот сейчас более-менее понятно. Вот примерно это я и хотел, простой пример схемы работы : )
Ура! Снус получил ответ! Ты молодец!
То есть, у вас простой поллинг, браузер делает кучку запросов на сайт, пока не получает ответ, а в качестве системы сообщений и балансировщика — бд.
Не у нас браузер не делает кучу запросов, он сделал один запрос, nginx передал lua, lua спросил у редиски и принял решение вернуть в nginx или сделать редирект, больши никаких запросов никуда не делаем
Maxim
Во, ещё очень страшный вопрос.
Чому не использовали специализированное ПО для месседжей, типа RabbitMQ? Оно специально запилено для такого, типа повышенная отказоустойчивость, очереди, балансировка, статистика и всякое такое.
Ну и да, лонг-поллинг таки экономичнее. Выгоднее держать одновременно кучу запросов, чем постоянно открывать-закрывать соединения. Выставляешь таймауты http-запросов минут на десять и вперёд ))
А то с поллингом на бумаге всё получается очень красиво: "мы обрабатываем миллиард запросов в секунду", не учитывая что 90% создаваемых запросов — очередная попытка получить ответ с минимальными действиями, но на практике, лонг типа быстрее и економичнее, меньше трафика, меньше дёрганий динамической памяти, а ещё куда меньше логов и сами логи прямее : )
RabbitMQ мы используем для совсем тяжелых задач, например мы скачиваем с удаленных ресурсов картинки и бэкапим эти картинки с помощью рабочих RabbitMQ
Maxim
Во, ещё очень страшный вопрос.
Чому не использовали специализированное ПО для месседжей, типа RabbitMQ? Оно специально запилено для такого, типа повышенная отказоустойчивость, очереди, балансировка, статистика и всякое такое.
Ну и да, лонг-поллинг таки экономичнее. Выгоднее держать одновременно кучу запросов, чем постоянно открывать-закрывать соединения. Выставляешь таймауты http-запросов минут на десять и вперёд ))
А то с поллингом на бумаге всё получается очень красиво: "мы обрабатываем миллиард запросов в секунду", не учитывая что 90% создаваемых запросов — очередная попытка получить ответ с минимальными действиями, но на практике, лонг типа быстрее и економичнее, меньше трафика, меньше дёрганий динамической памяти, а ещё куда меньше логов и сами логи прямее : )
мы стараемся сделать так что бы ответ на запрос пользователю пришел очень быстро, мы не делаем много соединений и не держим эти соединения
Maxim
То есть все те же задачи можно решить без опенрести?
рекомендую использовать конетейнер OpenResty в место сборки nginx вручную, экономит время
Maxim
То есть все те же задачи можно решить без опенрести?
А почему, кстати, не хотите использовать OpenResty? вы же собираете nginx, так какая вам разница что собирать nginx или OpenResty? вы же не лично там мешки перекладываете из вагона в вагон
Anonymous
Я просто поинтересовался. Когда модуль писали для предобработки, использовали нжинх, с луа, но не опенрести. Видимо апстрим было проще патчить.
Anonymous
Щас я не пишу ничего для нжинх
Anonymous
Спасибо
Maxim
Кстати, почему нгинкс не грузите? Луаджыт-скриптики вполне себе быстрые, на них можно ставить и тяжёлые кейсы.
У leafo целый движ есть, быстренький!
мы не грузим nginx тяжелыми задачами типа "сходить в БД", мы стараемся что бы nginx как можно меньше обращался к диску, максимум к ОЗУ может обратиться. вообще обращение к диску и все эти I/O операции очень сильно дорого обходятся, стараемся минимизировать обращения к файловой системе и не допускать кейсов когда нужно ждать ответа
Snusmumriken
мы не грузим nginx тяжелыми задачами типа "сходить в БД", мы стараемся что бы nginx как можно меньше обращался к диску, максимум к ОЗУ может обратиться. вообще обращение к диску и все эти I/O операции очень сильно дорого обходятся, стараемся минимизировать обращения к файловой системе и не допускать кейсов когда нужно ждать ответа
(на самом деле нет, если использовать нгинксовые io-методы, они не являются дорогими, асинхронщина, лонг-поллинг)
Maxim
(на самом деле нет, если использовать нгинксовые io-методы, они не являются дорогими, асинхронщина, лонг-поллинг)
если задачу не решить без обращения к диску то конечно же мы используем io методы, тут без вариантов
Snusmumriken
Но у вас этим занимается не нгинкс, хотя мог бы, на самом деле.
Maxim
Но у вас этим занимается не нгинкс, хотя мог бы, на самом деле.
наша цель - отдать ответ в браузер как можно скорее, а как это будет реализовано руководству не интересно. Партия сказала "НАДА!" - комсомол ответил "ЕСТЬ"!
Snusmumriken
Хех, дык в том-то и дело, что минимизируя прослойки и упрощая архитектуру, приложение становится быстрее. Самое быстрое почти равняется самым простым, по крайней мере по количеству сущностей.
Исключения — корутинноподобная асинхронщина и "правильно организованная" многопоточность, это обычно таки быстрее но слегка сложнее.
Maxim
Хех, дык в том-то и дело, что минимизируя прослойки и упрощая архитектуру, приложение становится быстрее. Самое быстрое почти равняется самым простым, по крайней мере по количеству сущностей.
Исключения — корутинноподобная асинхронщина и "правильно организованная" многопоточность, это обычно таки быстрее но слегка сложнее.
так и делаем. быстрее всего nginx + lua работают если не обращаются к диску, а читают из ОЗУ, быстрее не бывает
Snusmumriken
Ладно, ладно, всё, не вмешиваюсь. Просто советую поэкспериментировать, попробовать выдвинуть в луа чуть больше логики (и даже io-операции) на тестовой сборке и померять/попробовать заддосить.
Главное — использовать нгинксовый io а не луёвый, хотя там вроде и так переопределены стандартные методы на асинхронные, но я не уверен.
Maxim
Ладно, ладно, всё, не вмешиваюсь. Просто советую поэкспериментировать, попробовать выдвинуть в луа чуть больше логики (и даже io-операции) на тестовой сборке и померять/попробовать заддосить.
Главное — использовать нгинксовый io а не луёвый, хотя там вроде и так переопределены стандартные методы на асинхронные, но я не уверен.
оооооо, ты себе не представляешь какие я тут эксперименты ставлю, мне нравится как lua быстро работает, особенно магия с корутинами и одновременными запросами - это гениально
Snusmumriken
А уж как разогреется — так прям ваще каеф, да.
Snusmumriken
У луаджита есть косяк в том, что в одну виртуальную машину не стоит пихать слишком много логики, там что-то с трассами и их количеством. Но вот с небольшим и средним кол-вом логики (на уровне условно <5к строк трассирующегося кода) — справляется отлично, после разогрева — на уровне близком к сишке.
Ты хотел предельно быстрых запрос-ответов (в т.ч. с логикой)? Вот оно.
Maxim
У луаджита есть косяк в том, что в одну виртуальную машину не стоит пихать слишком много логики, там что-то с трассами и их количеством. Но вот с небольшим и средним кол-вом логики (на уровне условно <5к строк трассирующегося кода) — справляется отлично, после разогрева — на уровне близком к сишке.
Ты хотел предельно быстрых запрос-ответов (в т.ч. с логикой)? Вот оно.
у нас правила: больше 30 строк - расстрел, код выполняет больше одной задачи - расстрел, прыжок на месте рассчитывается за попытку улететь - расстрел солеными огурцами с занесением в личное дело! так точно!
Snusmumriken
у нас правила: больше 30 строк - расстрел, код выполняет больше одной задачи - расстрел, прыжок на месте рассчитывается за попытку улететь - расстрел солеными огурцами с занесением в личное дело! так точно!
Тут лимиты таки не на 30 строк. Представь бочку. В эту бочку можно налить 250 литров жидкости. Если больше — она переполняется, отказывается закрываться и так далее.
А у вас типа расстрел за то, что кто-то заливает больше половины стакана.
Я понимаю условно "за заполнение больше чем на 3/4", но не за 0.002% : )
Складывается впечатление, будто виртуальной машине и вовсе незачем разворачиваться, вам и нано-скрипта на том же пыхе хватит, который уже встроен и по умолчанию развёрнут в нгинксе.
 Artem
Artem
>> нано-скрипта на том же пыхе хватит, который уже встроен
это как?
Snusmumriken
 Artem
Artem
он никуда не встроен, пыха сама по себе)
Snusmumriken
Оки
Snusmumriken
а я таки поднял openresty, вместо того сервера))
Намана, а я поднял и то и другое и третье.
И даже нано-хттп-сервер, для апи.
Artem
nanohttpd?
Snusmumriken
Надо добавить подсветочку в нгинксопросмотровщик, хе-хе.
Snusmumriken
И возможность пользовательской заливки всякой фигни драг-н-дропом, чтобы меня потом посадили за чьи-то фотки центральных процессоров
Anonymous
Как работает корутиносервер?
Snusmumriken
Ну ты смотри.
Подключается клиент. Под него заводится корутина.
Пока сервер принимает мессагу/обрабатывает/возвращает ответ — после каждого этапа (или, если этап задерживается, например, клиент на момент приёма тела передал только его кусок) — корутина yield'ится, и обрабатывается корутина следующего клиента.
Код корутины (client:update) выглядит синхронным, но на самом деле это не так.
Anonymous
Отлично
Anonymous
А есть в луа что-то типо asyncio.gather
Anonymous
Питоновского
Anonymous
Когда сам можешь зашедулить массив корутин?
Snusmumriken
Когда сам можешь зашедулить массив корутин?
Нет, тут есть список корутин которые я шедулю ручками.
Автоматики нема.
Можешь написать, это просто, но придётся хранить список тасков в глобал-спейсе/замыкании, и как-то обновлять.
Anonymous
Ну, понятно. Спасибо
Anonymous
Ну, можно в тредлокале
Anonymous
Тогда и скоп будет локальный
Snusmumriken
Ну, в замыкании.
Anonymous
Меня так выбешивает хайп вокруг кооперативной многозадачности на самом деле
Anonymous
Все эти асинк аваит
Anonymous
Новый геморрой для отладки
Snusmumriken
Но обновлять всё равно придётся. Типа:
local tasks = require'corotask'
local foo
tasks:add(
function()
bla-bla
coroutine.yield()
bla-bla
return bla
end,
function(returned) -- success
foo = returned
end
)
while true do
tasks:update()
end
Anonymous
В дотнете хорошо сделано
Anonymous
На макросах
Snusmumriken
В дотнете хорошо сделано
Меня напрягает другое: корутины в скриптах провоцируют бешеное количество лямбд, замыканий, кодогенерации бла-бла.
Так-то в корутинах главное — наличие какого-то шедулера и отсутствие изменений каких-то переменных, которые одновременно используются несколькими корутинами, потому что тогда начинается "хз в какой момент какой корутиной что-то изменилось и всё сломалось".
Ну, обычные правила здравого смысла, типа "логически разделяем всё что можно".
Anonymous
К лапше из лямбд я привык, когда осваивал схемовский call/cc