 BinaryByter
BinaryByter


lol no idea
 Manuele
Manuele
the LSTM is more
BinaryByter
i haven't done a lot of ML tbh
Manuele
so, as i said, you know nothing about ML
BinaryByter
but saying that I have no idea of it is an understatement
Manuele
but saying that I have no idea of it is an understatement
knowing 2-3 definitions doesn't make you know it
BinaryByter
knowing 2-3 definitions doesn't make you know it
does implementing a NN make you know it?
Manuele
also, theory and practice are a lot different in ML
 Dima
Dima
Stap fighting
Manuele
does implementing a NN make you know it?
not only implementing it. you have to implement all the functions (too easy to use numpy), testing it, applying optimizations (and prevent exploding/vanishing gradient) and a lot of other things
Dima
BinaryByter
BinaryByter
github.com/Wittmaxi/Zeneural
Manuele
> 55 commits
Manuele
LOL
BinaryByter
yea I kinda fucked up a few times
Manuele
this is only a full connected NN lib
Manuele
std::vector? you know how much std::vector is slower than a float*?
Manuele
> no softmax
Dima
STL.... rip
Manuele
tested myself personally
Dima
throw away
Manuele
do you use openMP at least?
 Jussi
Jussi
Lol
Jussi
This guy was talking about C vs. C++ performance yesterday
BinaryByter
i'm still trying to implement it ( I have weird problems lol )
Jussi
Dpesnt even use aligned vectors
Dima
looool
Manuele
so stop putting shit on C and learn it
BinaryByter
@OxFFFFFFFF what are aligned vectors?
Manuele
maybe you'll find why a lot of people use it
Manuele
and i'm also a C++ programmer, so i'm not talking as a C fanboy
Manuele
i also prefer C++ to C
Jussi
Can I now show a real example of c code optimization?
Jussi
https://hastebin.com/fowitiwutu.cpp
Jussi
Here's a simple calculator of correlated pairs in a PNG image
Jussi
Here's a rather optimized version of same code:
https://hastebin.com/erumesanod.cpp
Jussi
The latter is about 80 times faster than the first one
Manuele
cool but it's nothing special, you simply use matrix/tensors as vectors
Dima
why no restrict pointer
Jussi
look at the code again lol
Manuele
uhm you are right
Jussi
I'm using data aligned vectors, float8_t takes 8 floats and can calculate all of them at the same time in cpu
Manuele
you should add shared to omp
Jussi
mm true
Jussi
c++ is way too bloated nowadays imo, that's why I cant understand people forcing it
BinaryByter
It's deep
Manuele
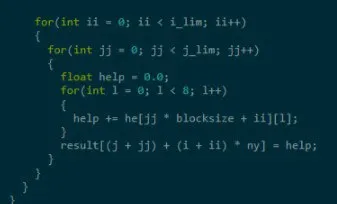
 Ибраги́м
Manuele
Ибраги́м
Manuele
The truth is...u don't learn C
the truth is that you need to learn C before you can learn c++ well
Manuele
because C++ is a C projection with OOP, but all the basic memory concepts are from C, like pointers and memory allocation
Ибраги́м
give your definition of bloat… anyway, .NET Core (that is not AOT) it's not so slower than C++. .NET Native is even faster than C++
98% of popular Cryptocurrencies is written in C++, not C#.
Ethereum was converted written in Go.
Note:
++ != #
Ибраги́м
the truth is that you need to learn C before you can learn c++ well
the truth is that you need to unlearn C before you can learn C++ well.
Manuele
98% of popular Cryptocurrencies is written in C++, not C#.
Ethereum was converted written in Go.
Note:
++ != #
i know they are different who do you think i am? anyway, .NET Native is pretty new, it's obv is not so diffused
Manuele
98% of popular Cryptocurrencies is written in C++, not C#.
Ethereum was converted written in Go.
Note:
++ != #
and, here the language doesn't matter
Manuele
since cryptocurrency are build for HPC
Manuele
so CUDA and OpenCL for Ethereum
Manuele
ASIC --> Verilog/VHDL for bitcoin
Manuele
so you can also use python as far as i care, the performance are given by these other languages/extensions on accelerators
Jussi
98% of popular Cryptocurrencies is written in C++, not C#.
Ethereum was converted written in Go.
Note:
++ != #
oh sorry I forgot that cryptos == whole world nowadays, Sorry! I will not bother you anymore
Manuele
the truth is that you need to unlearn C before you can learn C++ well.
you need to learn the basics of C, not of it's stl
Manuele
oh sorry I forgot that cryptos == whole world nowadays, Sorry! I will not bother you anymore
they are really annoying