 DaySandBox
DaySandBox


Removed msg from Павел. Reason: new user + forwarded
 Павел
Павел

 Fedor
Fedor
😁😁😁
Fedor
Павел
ну мы же онтопик типа, люди хотели сравенения ) а тут каг бы картинка про то, что это разные вселенные (параллельные в основном), хотя конечно много можно сравнивать.
Хотя, Ceph ближе к ZFS, чем к любой дгугой файловой системе (если уместно ZFS называть просто файловой системой), как минимум на уровне работы самого OSD с диском (скорее всего с оглядкой на ZFS и делали), те же LZ4 компрессия на лету, CoW и связанное с этим снэпшоты, клоны, send-receive функционал
Павел
единственно, что ZFS у меня добавляет свреху до 100 мкс на одну операцию ввода-вывода (реально меньше 70мкс для SSD диска со средней lat 35мкс), а ceph OSD 500-700 мкс )
Fedor
Павел
где? на Ceph в один поток на OSD 4k блоками где-то получается 1200-1500 IOPS при random write, в 16-32 потока 10-15к случайной записи по 4к блока, чтение там хорошо работает, легко можно упереться в потолок сети (у меня это 3,2GiB/s или около 29Gbit/sec) уже на блоках по 64к, фактически на мелких блоках молотит где-то 30-50к операций в секунду, т.е. средний lat меньше 0.5мс
Fedor
Неплохой наборчик.
Fedor
Фио кстати умеет симулировать процентное распределение нагрузки
Павел
кстати да, не плохо по результатам, рядом с нормальными цифрами для ceph. Если бы еще RDMA без глюков работал, хоршо бы помогло, а так TCP стэк свое жрет тоже, процентов 10-15% реально ужирает, не говоря о процессорном времени на переключении контекстов. У меня при тестировании на одну SSD (OSD) cpu sw заклинивает под 200к в секунду
Павел
Кстати о ZoL вспомнилось, оно бывает замирает на sync операциях, вот именно когда саму команду дергаешь, подвисает она и ждет в TASK_UNINTERRUPTIBLE (т.е. не убьешь его) и их может наплодится пакован, и load можно увидеть в 100-200 )
P.S. Несколько раз встречалось, например, при обновлении ядра, там есть скрипт update-initramfs - в нем дергается команда sync в одном месте, вот может подвиснуть, которая помогает тестировать отдельные OSD и смотреть на то как оно себя ведет
Павел
Фио кстати умеет симулировать процентное распределение нагрузки
 Fedor
Fedor
а перцентили для SLO вручную считать? :)
Павел
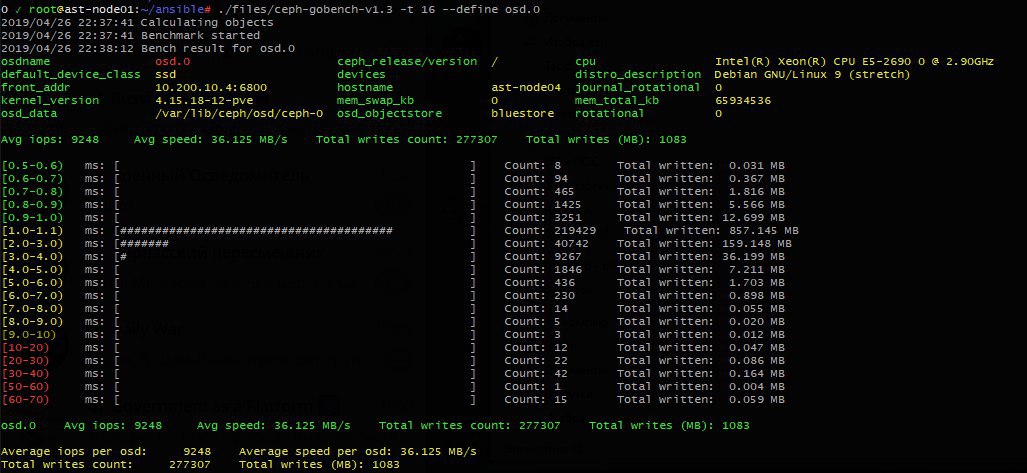
ой ну ладно, сложно ли, тем более, что это реальный тест по OSD. Мне нужно понимать пределы, общее распределение, так сильно нагляднее, особенно если для тюнишь конкретную систему и сравниваешь куда смещается
Павел
где выпадения
Fedor
это на 16секундном интервале тестирование?
Павел
нет, минута. Параметр — это количество потоков, т.е. 16 потоков
Fedor
попробуй минут 10-15 записи, чтобы кеш забить
Fedor
посмотри, как оно себя будет вести
Павел
можно, да
Fedor
чего куда подскочит и сместится
Павел
там кэш чей забить мне надо? там кэш отключен
Fedor
у тебя кеш записи присутствует в системе?
Fedor
в самом цефе
Fedor
или он директ синк(по терминологии зфс)
Павел
тем более операциями по 4k даже в 32 потока (около 50мб в секунду) кэш особо не забьешь, оно будет сбрасываться точно быстрее
Fedor
пиши по мегабайту блоками :)
Павел
директ, конечно. Тем более это же DC SSD с кондеями
Fedor
и с локалхоста
Павел
а смысл по 1М тестить? оно упрется просто в скорость шины (около 400МБ), т.е. меньше 400 iops, да и наглядности мало, такой нагрузки не бывает в реале и она не цеф тестирует, он 400 операций легко пропихнет
Павел
сча покажу, а то теоритизирую )
Fedor
что ж у тебя за шина такая
Павел
sata3 же — 6 Gbit/s
Fedor
6 гигабит чтоль?
Fedor
понятно
Fedor
ну так у тебя же рейд
Павел
нет, нельзя рейд и CEPH
Fedor
ты ведь не экспандером его расширял
Fedor
я не про физический рейд
Fedor
а скорее про методы записи
Павел
в смысле репликация?
Fedor
скорее, аналог страйпа
Павел
нет, я тестирую OSD, т.е. репликация отключена, чтобы увидеть пределы по производительности конкретных хостов, дисков и все такое
Fedor
ну понятно.
Fedor
для сифы хороший лейтенси
Павел
в смысле size репликации = 1 )
Fedor
я даж удивлён немножк
Павел
ну дык а я про что )
Павел
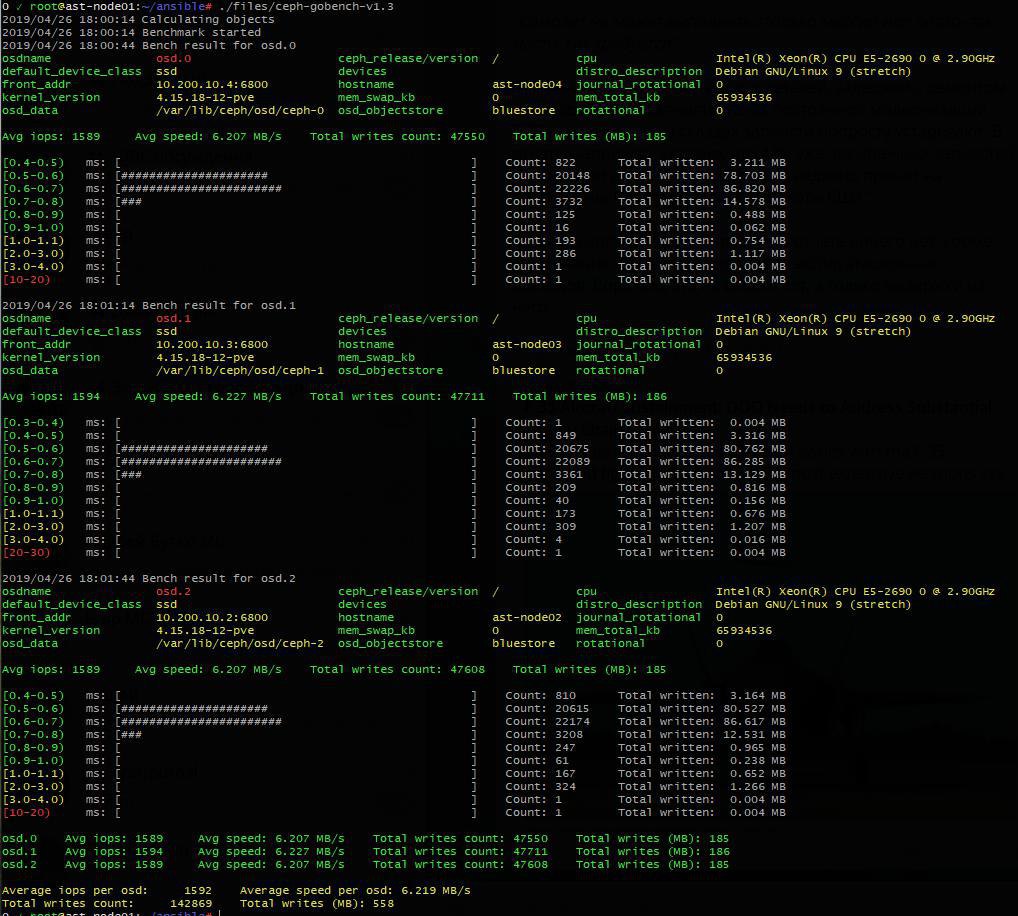 Павел
Павел
это вот тест в один поток по трем OSD чтобы увидеть, что оно даже ровненько
Павел
т.е. proof of concept )
Fedor
а эт ты не синхронно ли сейчас в них заливал данные с коммитами?
Fedor
синхронные
Павел
не очень понял, у CEPH все операции синзронные, других нету по архитектуре
Павел
причем WA там около 11 )))
Fedor
1.5к иопс на ноду..
Павел
не очень понял )
Fedor
ладно. :)
Павел
если операции в среднем делаеются за 0,6 миллисекунды — то это где-то около 1500 IOPS )
Fedor
миллисекунды
Fedor
ну это да.
Павел
а в чем вопрос?
Fedor
да я уж посмотрел :)
Павел
сами диски у меня выдают где-то 24-25к IOPS на 4к в один поток с sync
Fedor
в транзакциях захлёбывается вся эта штука.
Fedor
а знаешь.. проведи тест. вынеси ка одну из нод и посмотри, что будет. :)
Павел
вот реальный WA у CEPH на bluestore — где-то около 6-7
Павел
т.е. 35мс (lat sync у SSD)*6 ~ 200мс (правда там в несколько потоков может, но будем считать так) + сеть на TCP ~80-90мс + ну и сам код на себя ужирает 300-400 мс (не меньше)
Павел
кстати, сеть через RDMA дает +20мс всего, но на таких масштабах цифер это не очень существенно, но где-то 10-15% можно вытянуть, если бы оно там не глючило )
Павел
там с RDMA переключений контекстов еще меньше, что опять же ускоряет исполнение самого кода OSD
Павел
но код конечно у ceph та еще радость (
Павел
но, в защиту скажу, что у конкурентов (типа glusterfs, если можно его хотя бы близко так рассматривать, корректнее наверное сказать, что нет и конкурентов то), там совсем печаль в коде )))
Павел
вот так и живем ))
Fedor
Вот не тонуло бы оно в транзакциях.
Павел
в каком смысле? где оно должно тонуть, о чем речь?
Fedor
в каком смысле? где оно должно тонуть, о чем речь?
Ceph не подходит для высокнагруженных систем.
Павел
Эх... Там много что не подоходит, не говоря уж про то, что высокая нагрузка - это всегда специальная штука, там нет общего решения, кроме — "нафиг вы её делаете" :) нужно обходить и не делать высокой нагрузки. 99% ситуаций с высокой нагрузкой — кривой код и запросы без индексов в БД.
Павел
Я бы сказал так, ceph не очень подходит для высоких iops записи в один поток... Ну и это "внезапный дипскраб, хуже татарина" :) (т.е. не гарантированный отклик, если твои данные попали на пг в дипскрабе - у тебя резко lat скакнет)
Fedor
Эх... Там много что не подоходит, не говоря уж про то, что высокая нагрузка - это всегда специальная штука, там нет общего решения, кроме — "нафиг вы её делаете" :) нужно обходить и не делать высокой нагрузки. 99% ситуаций с высокой нагрузкой — кривой код и запросы без индексов в БД.
Не все нагрузки поддаются оптимизации :) например, банальная телеметрия(не прометеевская) с сотен тысяч хостов.