 Anonymous
Anonymous


Okay. My initial thought was to create queue of point files that fail and then process through those committing after each entry. That way i was only slowing the process down when duplicates were involved. Is there a better or prefered way to prevent duplicate entries?
Anonymous
I can post my Entity definitions and the function that is doing the work if that is useful information.
Matthew
How do you define a duplicate entry? If it matches the primary key?
Anonymous
class Point(db.Entity):
id = PrimaryKey(int, auto=True)
file_name = Required(str, unique=True)
device_name = Required(str)
point_name = Required(str)
data = Set('PointData')
type = Optional(PointType)
class PointData(db.Entity):
time_data = Required(datetime,6)
value = Required(str)
point = Required(Point)
PrimaryKey(point,time_data)
Anonymous
yes
Anonymous
the composite primary key of PointData
Matthew
Are you inserting from a single process / thread or multiple?
Anonymous
single
Anonymous
I have about 5,000 CSV files for a given period of time that I process through.
Matthew
Have you tried doing an exists() query for each PointData insert?
Anonymous
I've been handling it in memory for the past few months, but I'm looking to move beyond that.
Matthew
Could PointDatas for the same Point be spread across multiple CSV files?
Anonymous
I thought about that, but I wasn't sure about the performance hit. Duplicates are unlikely unless someone tries to load the same file a second time. I thought that I'd be better off just blasting them and then going back through the failures. If the hit isn't bad from exists() though I can do that.
Anonymous
Yes. sort of
Anonymous
I run a report each month that gives me the CSV files for the previous month.
Anonymous
There should only be one CSV file per point during a given month though and that is all that I am processing at a time.
Matthew
I think it's likely that exists() would be cheap. If not, you can dedupe in python (maybe a dict with the primary key combo as a key) on a per file basis.
Matthew
the exists() should be quick because it is doing an index lookup
Anonymous
Okay. I will give that a shot. Thanks
Matthew
No problem
Matthew
if PointData.exists(lambda pd: pd.point == my_point and pd.time_data == my_time_data):
# create the PointData
Matthew
that should work
Anonymous
Thanks again. I was just reasoning my way through that. I appreciate the help
Matthew
No problem, I've done similar projects before and I don't remember performance ever being an issue.
Anonymous
I'm currently testing pony 0.7.2 for usage at Dematic
One test seeks to assert that a postgresql and sqlite behave identical for a number of orm.db_session calls. This works perfectly in isolation.
However when I'm trying to switch from one provider to another as a part of a loop, pony bites back with the message that: "'Database object was already bound to %s provider'" (ll 547 in core).
I then looked at the code and found that db.disconnect does not set database.provider = None
(def disconnect(...):... line 599.
Is it me doing something wrong?
Anonymous
db.disconnect should set database.provider to "None" shouldn't it?
Anonymous
I also see that the db.schema does not reset when calling db.disconnect().
Anonymous
The python object "db" was created by a module in global name space. By repacking the python object into a function that instantiates the db as a new object, the problem has been resolved.
Anonymous
However I was still surprise that db.disconnect() doesn't clear out completely.
Alexander
Hi! According to current design, a Database object cannot be "unbinded" from the provider. The disconnect method just closes a DBAPI connection to a database server.
The reason for that behavior is that some properties can be set only after we know specific database server. For example, I may be interested in knowing MyEntity._table_ property which contains a table name for this specific entity. This table name may be different for different databases: MYENTITY in Oracle and myentity in other databases. So, the hypothetical unbind method should also 'reset' all such properties to its initial state, and it may be hard to do.
Currently we suggest to create db object inside a factory function, and make separate instance of db object for each database
Anonymous
Your suggestion is the solution I went for.
Anonymous
So far I'm very impressed with pony.
Alexander
Thanks, please let us know what improvements you'd like to see in pony. This could help us to make it even better ;)
Anonymous
Will do :-)
Matthew
Hi,
I am getting very bad performance in the view of my web app, I have narrowed it down to code like this:
in for loop:
product = Product.get(lambda p: p.attr1 == x and p.attr2 == y)
using sql_debug, I see it's doing a select query with LIMIT 2, which I suspect is making postgres scan the whole table in every loop, any idea why there's a LIMIT 2?
Matthew
A lookup using the default limit 2 = 30ms, with limit 1 it's 10ms
Matthew
from running the generated query manually in psql
Matthew
product = Product.select(lambda p: p.attr1 == x and p.attr2 == y).limit(1)[😏 or [None])[0] is approx 3x faster than the get, correctly issues a limit 1
Matthew
with a correct index, it's a lot faster, but still a 3x difference between limit 1 and limit 2
 stsouko
stsouko
The get method assumes that no more than one object satisfies specified criteria. Pony attempts to retrieve more than one object in order to throw exception if multiple objects were found. Sometimes the query condition is wrong and a very big number of objects satisfy the criteria. Pony adds LIMIT 2 in order not to load all that objects to memory.
Matthew
Does it take composite_keys into account? That could be an optimisation when you know the database restricts the possible results to be max 1
Matthew
Or maybe a get parameter / get version that only does limit 1?
Alexander
Hi, this form should take composite key into account:
Product.get(attr1=x, attr2=y)
Matthew
Hi, this form should take composite key into account:
Product.get(attr1=x, attr2=y)
I tested this with a composite_key present on attr1 and attr2, it is still LIMIT 2
Alexander
Hmm, that's strange. How do you define the composite key? Is it composite_key(attr1, attr2) in entity definition? Remember that composite_index is not sufficient, because composite_index is not unique
Matthew
yes it is composite_key(attr1, attr2)
Alexander
Looks like a bug... I'll try to fix it
Matthew
This is with SQLite by the way
Alexander
Ok, it should work with any database
Joery
Any update on this?
Joery
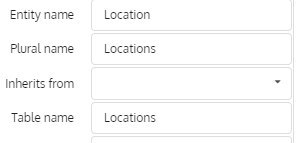 Joery
Joery
No. We'll fix it tomorrow
Joery
Suggestion: Add an Unsigned checkbox to the editor
Roman
Sorry, I fixed, it but we had hard refactoring and we needed time to test it all. I will ping then it would done(very soon)
 Alexey
Alexey
Suggestion: Add an Unsigned checkbox to the editor
Hi Joery,
Where do you suggest adding this?
Joery
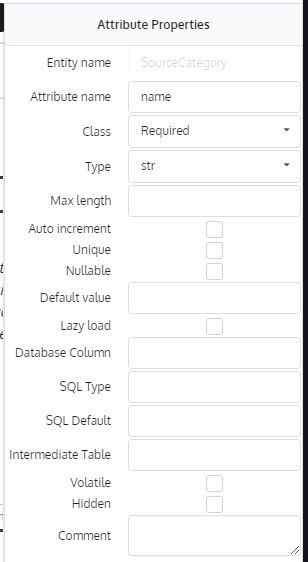 Joery
Joery
@alexeymalashkevich
 Alexander
Alexander
I tested this with a composite_key present on attr1 and attr2, it is still LIMIT 2
Hello. I just fixed this bug. Already released on GitHub.
Matthew
Hi, great! Does it work with lambda style queries, or only **kwargs style get?
Alexander
Only for kwargs.
Alexander
It's too complex to analyse lambda.
If you know that you are searching by unique key - kwargs is enough.
Matthew
Agreed :) thanks!
Matthew
Is a new release planned soon?
Alexander
I think tomorrow.
Alexander
Didn't have enough time to make a release today - documenting new features takes time
Joery
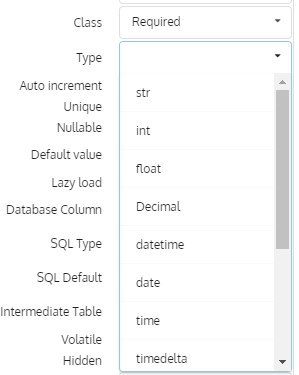 Alexander
Alexander
In Pony unicode and str mean the same (unicode), for easer porting of application code to Python3. You can use str in models with meaning "unicode"
Joery
class Example(db.Entity):
test_attribute = Optional(int, size=8, sql_default=0, default=0)
The editor generates the sql_default attribute as an integer, but shouldn't it be a string?
Joery
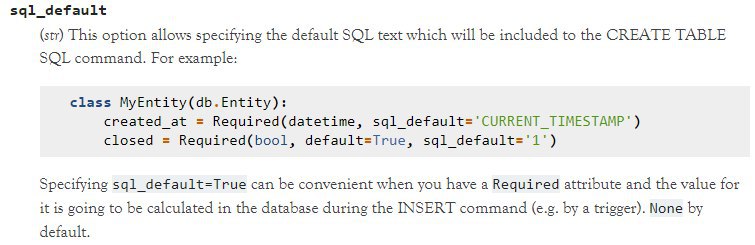 Alexander
Alexander
It should. Thanks for reporting, this is a bug
 kwerty
kwerty
Hi guys. Do you have best practice or templates for new project which use pony orm ? I mean where I must to store models and where others?
kwerty
I need your advice.
Matthew
I start with a single file for a flask + pony project until it gets larger or I need to access the models outside the web app, then I move the models to a models.py
Anonymous
I once made the mistake of using a single models.py file for multiple applications. I needed just a few of the models in each. But when I called db.bind it created all of the models in my database (not just the ones I imported from models.py) and I ended up with clutter. So, don't do what I did :)
kwerty
thanks
 Henri
Henri
Is it possible to set a required field in before_insert?
class Article(db.Entity):
slug = Required(str, 200, unique=True)
title = Required(str, 255)
def before_insert(self):
self.slug = self._slugify_url_unique(self.title)
stsouko
use __init__()