 Pavel WTF
Pavel WTF


Thank you for replies.
 Artur Rakhmatulin
Artur Rakhmatulin
Hello!
Which rulles to work with to_json of Query objects?
[link to doc](https://docs.ponyorm.com/api_reference.html?highlight=json#Query.to_json)
when i try to corvert my Query object to json with to_json() i gex exception
The current user None which belongs to groups ['anybody'] has no rights to see the object ORDER[1088962] on the frontend
ORDER - is my entity
Artur Rakhmatulin
What is simple way to convert objects to json?
 Micaiah
Micaiah
to_json is getting replaced (i think). Will to_dict work?
 Alexey
Alexey
Hello!
Which rulles to work with to_json of Query objects?
[link to doc](https://docs.ponyorm.com/api_reference.html?highlight=json#Query.to_json)
when i try to corvert my Query object to json with to_json() i gex exception
The current user None which belongs to groups ['anybody'] has no rights to see the object ORDER[1088962] on the frontend
ORDER - is my entity
Hi Artur!
The `to_json()` method is part of PonyJS addon to Pony - an ability to get the database models at frontend. It is not released yet.
Currently the best option is to use https://docs.ponyorm.com/api_reference.html?highlight=to_dict#Entity.to_dict
Alexey
`to_dict` works and will work
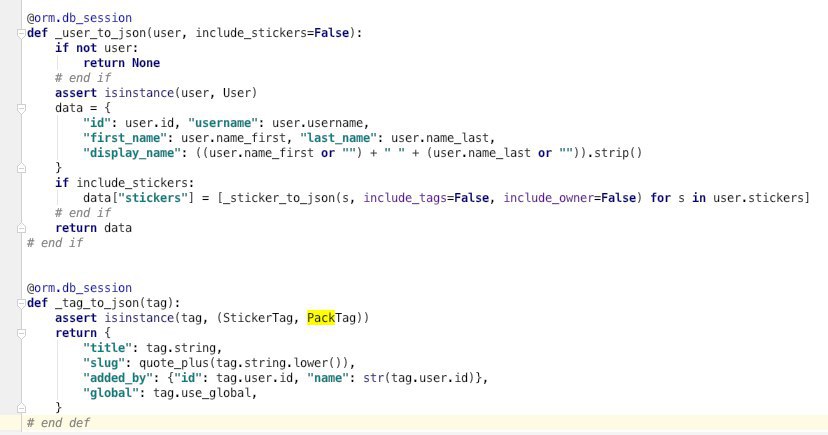
what we'd like to do is to offer a simple way of creating hierarchial JSON
Alexey
Here is an example:
Alexey
select(g for g in UniversityGroup if g.graduate_year == 2018).extract("""
number,
major,
department {
number,
name,
faculty { name }
},
courses foreach(c) orderby(c.name) {
id, name, credits
}
students foreach(s) where(s.gpa > 3.5) orderby(s.name) limit(10) {
id, name, gpa
},
""")
Alexey
as the result you'll get JSON
Alexey
currently you can use to_dict method and then convert it to JSON
Micaiah
select(g for g in UniversityGroup if g.graduate_year == 2018).extract("""
number,
major,
department {
number,
name,
faculty { name }
},
courses foreach(c) orderby(c.name) {
id, name, credits
}
students foreach(s) where(s.gpa > 3.5) orderby(s.name) limit(10) {
id, name, gpa
},
""")
Could there be a sort of Extract object that can be used in place of """..."""
Artur Rakhmatulin
`to_dict` works and will work
what we'd like to do is to offer a simple way of creating hierarchial JSON
Cool realisation, i will try it too!
Artur Rakhmatulin
 Alexey
Alexey
Could there be a sort of Extract object that can be used in place of """..."""
what is the use case of such Extract object?
Artur Rakhmatulin
Hmmm... what version include this fiture? 'Query' object has no attribute 'extract'
Alexey
it is the next thing we are going to work on after we release the migration tool
Artur Rakhmatulin
Ok :) Thank you
Alexey
😀
Pavel WTF
By the way, can you provide some examples or real project repos that use ponyorm?
Alexey
here https://libraries.io/pypi/pony/usage
 Lucky
Lucky
select(g for g in UniversityGroup if g.graduate_year == 2018).extract("""
number,
major,
department {
number,
name,
faculty { name }
},
courses foreach(c) orderby(c.name) {
id, name, credits
}
students foreach(s) where(s.gpa > 3.5) orderby(s.name) limit(10) {
id, name, gpa
},
""")
Pony ORM strives to be the most pythonic framework, but uses some completely new language just to generate json?
This strucks me as really a wrong in that scope.
Micaiah
I agree, I've been trying to think of a better way to do it but, I haven't yet.
Micaiah
Some sort of schema object might do
Lucky
Pony ORM strives to be the most pythonic framework, but uses some completely new language just to generate json?
This strucks me as really a wrong in that scope.
 Romet
Romet
 Romet
Romet
what on earth
Micaiah
keeps track of if statements, i've seen it done if there is a lot of conditional logic dictating when the function loses scope
Romet
you'd think indentation would be obvious enough
Micaiah
there might also be a plug in for an IDE which benefits from those kind of comments
Lucky
Romet
I'm not really being nitpicky, I just found it sort of amusing since I've never seen it before
Lucky
select(g for g in UniversityGroup if g.graduate_year == 2018).extract("""
number,
major,
department {
number,
name,
faculty { name }
},
courses foreach(c) orderby(c.name) {
id, name, credits
}
students foreach(s) where(s.gpa > 3.5) orderby(s.name) limit(10) {
id, name, gpa
},
""")
 Lucky
Romet
Lucky
Romet
telegram really needs to expand chat bubbles to full width..
Lucky
telegram really needs to expand chat bubbles to full width..
That's why I mostly also send a screenshot
Lucky
telegram really needs to expand chat bubbles to full width..
Also syntax highlighting would be awesome
Romet
definitely
Micaiah
syntax highlighting would be great
Micaiah
There is already some markdown support, idk why they don't allow
```python
to work
Lucky
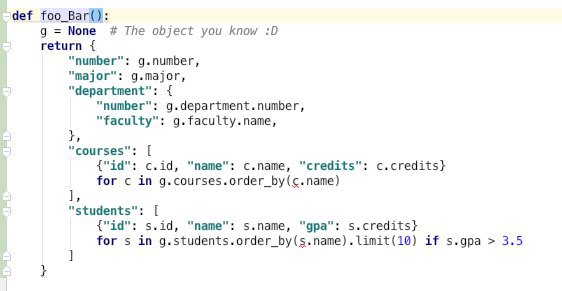
return {
"number": g.number,
"major": g.major,
"department": {
"number": g.department.number,
"faculty": g.faculty.name,
},
"courses": [
{"id": c.id, "name": c.name, "credits": c.credits}
for c in g.courses.order_by(c.name)
],
"students": [
{"id": s.id, "name": s.name, "gpa": s.credits}
for s in g.students.order_by(s.name).limit(10) if s.gpa > 3.5
]
}
Getting back to topic :D
I really don't think you guys should invent a new language just for that.
What are the reasons not to use python?
Lucky
Indeed, workaround is:
p for p in Pack if p.nsfw is True or p.nsfw is None
I meant
p for p in Pack if not (p.nsfw is True or p.nsfw is None)
as workaround for if not p.nsfw
back then.
 stsouko
stsouko
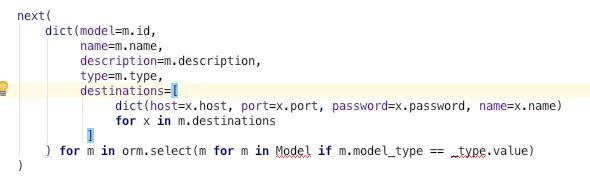
next(dict(model=m.id, name=m.name, description=m.description, type=m.type,
destinations=[dict(host=x.host, port=x.port, password=x.password, name=x.name)
for x in m.destinations])
for m in select(m for m in Model if m.model_type == _type.value))
stsouko
for JSONize I think this good
stsouko
pure python.
Lucky
I meant
p for p in Pack if not (p.nsfw is True or p.nsfw is None)
as workaround for if not p.nsfw
back then.
Nevermind. My condition should only remove p's if nsfw is really True.
So maybe
p.nsfw in [False, None]
could work too.
 Lucky
Lucky
Well... you asked about get, and select is entirely different story. Pony should translate select generator code to SQL, and cannot translate your function, because it doesn't know what equivalent SQL should be. I don't know it too :)
Also, the function that you wrote expects keyword arguments, not positional ones as you use inside the query.
1) I suggest you to write selects explicitly:
games = select(g for g in Game if (g.name == name or name is None) and (g.version == version or version is None))
2) You can also build query incrementally:
query = select(g for g in Game)
if name is not None:
query = query.filter(lambda g: g.name == name)
if version is not None:
query = query.filter(lambda g: g.version == version)
3) Probably even something like that should work:
def ignore_none(query, **kwargs):
for key, value in kwargs.items():
if value is not None:
query = query.filter(lambda x: getattr(x, key) == value)
return query
query = select(g for g in Game)
query = ignore_none(query, name='X', version='Y')
I didn't test it. Theoretically it should work, but there is an open issue 223, which describes a bug with getattr which is not fixed yet. You may follow approach (2) for safety
This .filter(lambda args: bool) in 2) is awesome.
packs = orm.select(p for p in Pack if not only_published or p.published)
Is now
packs = orm.select(p for p in Pack)
if only_published:
packs = packs.filter(lambda p : p.published)
# end if
Anonymous
Is there a way to create tables using a json file that handles field declaration?
Alexander
In principle, it is possible to create entity classes dynamically. Simplified example:
from pony.orm import *
from pony.orm import core
db = Database()
def define_person_entity(db):
attrs = []
attrs.append(('name', Required(str)))
attrs.append(('age', Required(int)))
Person = core.EntityMeta('Person', (db.Entity,), dict(attrs))
define_person_entity(db)
db.bind('sqlite', ':memory:')
sql_debug(True)
db.generate_mapping(create_tables=True)
with db_session:
p1 = db.Person(name='John', age=18)
p2 = db.Person(name='Mike', age=20)
persons = select(p for p in db.Person)[:]
You can use the same idea to generate entity definitions based on information from some configuration file
Micaiah
This schema library looks like it would be useful to JSON based Pony work, and has a similar API https://pypi.python.org/pypi/schema
Anonymous
Ty guys and awesome :)
 Serge
Serge
> from pony.orm import *
> from pony.orm import core
O_O?
Alexander
from pony.orm import * imports only the most popular content for typical scenaries: Database objects, fields like Required, Optional, Set, select function, etc. EntityMeta is not part of "basic" API, and must be imported explicitly.
Some people don't like import * syntax, so we want to replace it with explicit imports in documentation and examples. With explicit imports, the code looks in the following way:
from pony import orm
from pony.orm import core
db = orm.Database()
def define_person_entity(db):
attrs = []
attrs.append(('name', orm.Required(str)))
attrs.append(('age', orm.Required(int)))
Person = core.EntityMeta('Person', (db.Entity,), dict(attrs))
define_person_entity(db)
db.bind('sqlite', ':memory:')
orm.sql_debug(True)
db.generate_mapping(create_tables=True)
with orm.db_session:
p1 = db.Person(name='John', age=18)
p2 = db.Person(name='Mike', age=20)
persons = orm.select(p for p in db.Person)[:]
Lucky
Hey, again asking how the migration is progressing :D
But probalby have a problem it won't be able to tackle in the first version anyway.
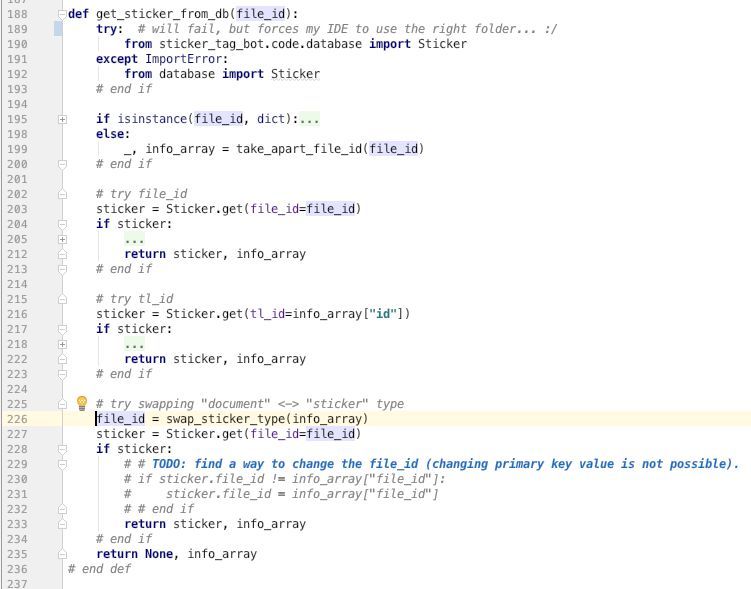
I need to change a primary key to normal (indexed) column.
More specific, in my database I was storing sticker per file_id, but telegram recently changed how they are calculated.
I am able to calculate the new file_ids from the old ones, but I can't update them, because the file_ids are primary key.
So I think adding a normal counter based PK would be the easiest way?
But it will be fun to update all the references.
Lucky
(actually there is a real id on telegram side, but I don't always have them, when puting stickers in the database)
Lucky
Hey, again asking how the migration is progressing :D
But probalby have a problem it won't be able to tackle in the first version anyway.
I need to change a primary key to normal (indexed) column.
More specific, in my database I was storing sticker per file_id, but telegram recently changed how they are calculated.
I am able to calculate the new file_ids from the old ones, but I can't update them, because the file_ids are primary key.
So I think adding a normal counter based PK would be the easiest way?
But it will be fun to update all the references.
 Lucky
Lucky
This is pseudo optimal, because some stickers ended up already twice in the database this way.
 Felipe
Felipe
Hi, I just started to use ponyorm in a little project 😊
Artur Rakhmatulin
hello :) good choise
 Святослав
Святослав
But most plugins for flask support peewee or sqlalchemy =\
Micaiah
PonyORM needs better plugin support
Micaiah
Although I don't neven know what Flask Pony would do, I've never felt like I needed it at least
Lucky
Although I don't neven know what Flask Pony would do, I've never felt like I needed it at least
Me neither.
And I use flask for everything :D
Alexander
@luckydonald the first version of migration tool will not be able to change primary keys. I think you can use the following approach: create a separate database with fixed Sticker definition and write a script which connects to both databases and copies data from one database to another one
Святослав
I have an idea for explicit set composit_key/index per column ordering:
class A(Entity):
field_one = orm.Required(int)
field_two = orm.Optional(str)
orm.composit_index(field_one, field_two) # ... ("field_one", "field_two)
orm.composit_index(field_one, core.desc(field_two)) # ... ("field_one", "field_two" DESC) ...
Святослав
It will be usefull use api like this
Alexander
So you suggest to allow using desc when specifying composite indexes. I think it is possible
Святослав
Yea!
Lucky
So you suggest to allow using desc when specifying composite indexes. I think it is possible
I just know about postgres, but there you can also index stuff like LOWER(column)
Alexander
Well, actually it can be arbitrary expressions... In the future we should support it as well, but before that I want to finally release migrations
Lucky
Is there already documentation or something else to read about that will work for the user?
Alexander
Not yet. In short, we will replace
db.bind(**settings.db_params)
db.generate_mapping(create_tables=True)
to
db.connect(**settings.db_params)
and allow a developer to define the following script migrate.py in his project folder:
import settings
from models import db
db.migrate(**settings.db_params)
Then a developer can run
python migrate.py make
to generate new migration file,
python migrate.py apply
to actually perform migration
or python migrate.py sql
to show sql of the migration
It is also possible to call python migrate.py make --custom to create a file of migration in which it is possible add arbitrary UPDATE or ALTER TABLE command manually.
The details of API will be revealed soon