 Alexander
Alexander


And for general patterns you can use raw sql fragments:
a = '_foo%bar%'
select(x for x in X if raw_sql('x.column1 LIKE $a'))
 Anonymous
Anonymous
That was quick. Thx!
Anonymous
Sorry for bothering again, but I have troubles on inserting data using pymysql.
After verifying my data with Marshmallow I've got back this data:
'test_von': DateTime(2020, 3, 1, 0, 0, 0, tzinfo=Timezone('UTC'))
The SQL statement says:
Date(2020, 3, 1)
The result:
AttributeError: 'Date' object has no attribute 'translate'
The field is created with this statement:
test_von = orm.Optional(date)
Any ideas what I'm doing wrong?
 Alexander
Alexander
Can you show your query?
Anonymous
INSERT INTO `releasedetails` (`page_id`, `product_version`, `release_typ`, `architekturaenderung`, `schulung`, `test_von`, `test_bis`, `beschreibung`, `release_index`) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s)
[87261375, 'EDIS_1.5', 'Major Release', False, False, Date(2020, 3, 1), Date(2020, 3, 4), 'Wahnsinns-Release', 3]
Alexander
I mean Pony query. Or you are using raw SQL?
Alexander
Also I'm not familiar with marshmallow and can't be sure how Date is compatible with date.
Anonymous
That's actually all I see from Pony. The previous statement is selecting the FK from an other table.
Marshmallow delivers as expected, because that's I get back:
Anonymous
'test_von': DateTime(2020, 3, 1, 0, 0, 0, tzinfo=Timezone('UTC')) can be handled by Pony Date(2020, 3, 1)
Anonymous
I only do not know there Date() comes from, but I guess it's from Pony - or?
Alexander
Pony has no Date type. It uses built-in date type.
By Pony query I mean smth like select(...) or Entity(attr1=1, attr2=2). Not SQL code.
Alexander
As I understand it, it's from marshmallow. Pony as well as database expect standard Python date type, not some marshmallow type
Anonymous
Sorry, my bad. I used Pendulum to parse my date input (which could be in several formats) and now switched to python-dateutil - and it works.
Sorry for the confusion.
 Andrey
Andrey
Hello, do you have any plans to integrate pony with aiopg? It will be useful for using pony in asyncio-based applications.
 csa3d
csa3d
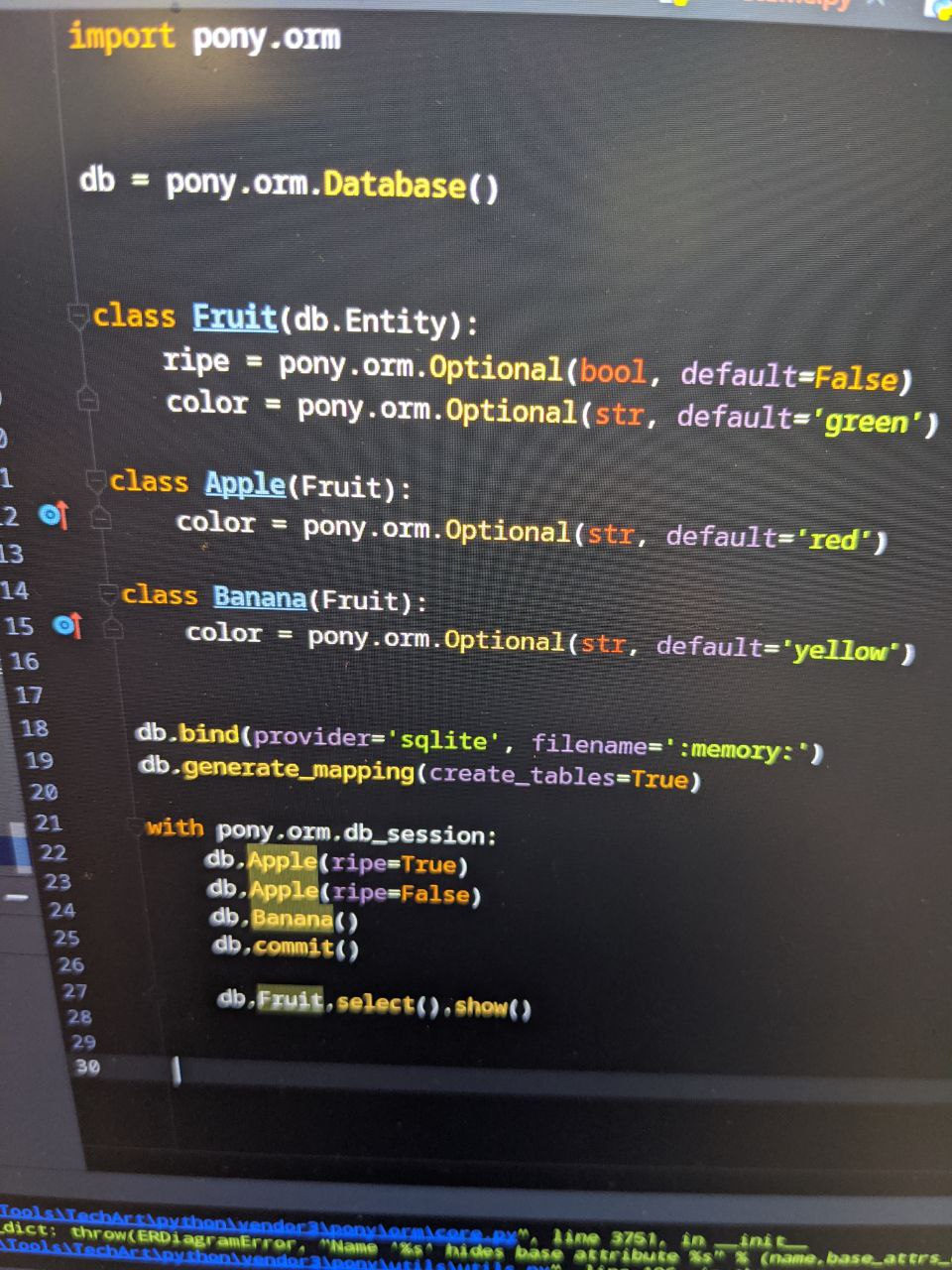
How would I best go about setting default value overrides in an inherited class?
csa3d
 Alexander
Alexander
We don't have any specific plans at this moment. It is not easy to integrate ORM with async frameworks.
For good database performance it is better to have as few concurrent transactions as possible and for transactions to be as short as possible.
With async frameworks it is typical to have a big number of long-lived concurrent coroutines. It is not efficient from the database point of view to have a large number of long-lived transactions.
I think it is better in async application to access database from a separate data access layer and communicate with it from async code using a queue. Then database access layer can use short sequential transactions
csa3d
Idea is to remove specificity having to know default when instantiating new record
Alexander
csa3d, you can handle it using __init__ methods:
class Fruit(db.Entity):
color = Optional(str)
def __init__(self, color='green'):
self.color = color
class Apple(Fruit):
def __init__(self, color='red'):
super().__init__(color)
Andrey
We don't have any specific plans at this moment. It is not easy to integrate ORM with async frameworks.
For good database performance it is better to have as few concurrent transactions as possible and for transactions to be as short as possible.
With async frameworks it is typical to have a big number of long-lived concurrent coroutines. It is not efficient from the database point of view to have a large number of long-lived transactions.
I think it is better in async application to access database from a separate data access layer and communicate with it from async code using a queue. Then database access layer can use short sequential transactions
Thank you. Is it possible to pass pony’s Query objects via such kind of queue?
csa3d
Alexander
Thank you. Is it possible to pass pony’s Query objects via such kind of queue?
No, because query should be executed inside a transaction (that is, inside a db_session). I think you need to convert Pony object to some JSON-like data and pass it through queue.
ORM object's attributes may be lazy. Sometimes the value of attribute is not loaded until you access that attribute, and at this moment implicit query goes to the database to load attribute value under the hood. This can be executed inside transaction. But if you are working with data outside of transaction, you cannot load lazy attributes anymore, so all necessary information should be loaded beforehand in the data access layer.
I think that implicit converting of ORM objects to plain JSON structures may be inconvenient, but it is a price of combining transactions and async code.
This is a trade-off actually. Pony uses transactions & IdentityMap pattern which may be very efficient for short synchronous transactions and provide great data consistency guarantees. Some other ORMs use simpler ActiveRecord pattern instead. They can abandon transactions and work with database without consistency guarantees. It can lead to some data corruption caused by unresolved write conflicts, but such ORMs can be used in transaction-less mode with async code. The example is Peewee ORM, I think you can use it with async frameworks. Maybe it suits your tradeoffs better for async application.
Maybe some time in the future we can support transaction-less mode in PonyORM too, but it required to massive changes in architecture, as currently Pony is heavily oriented toward consistent transactions
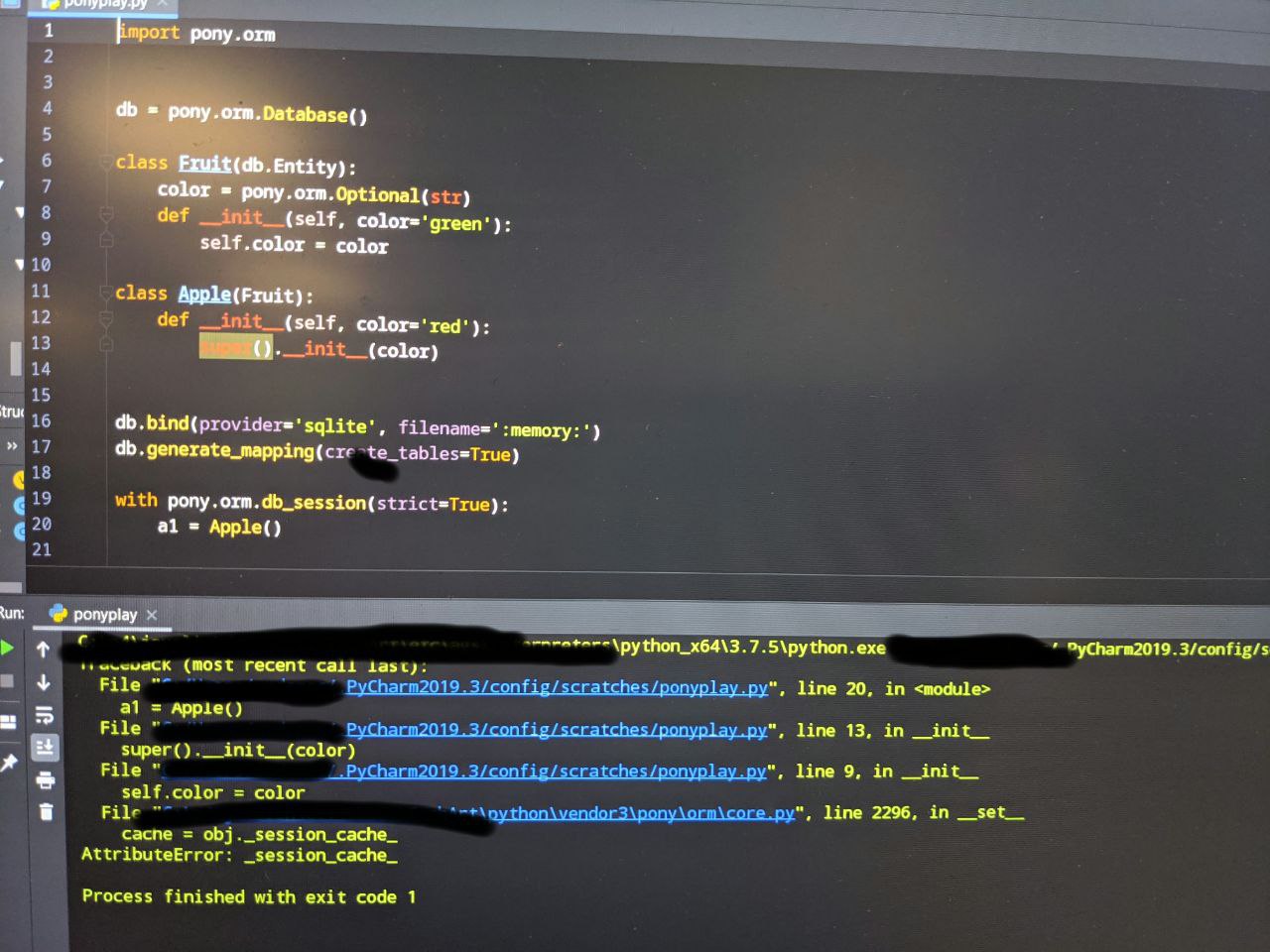 Alexander
Alexander
I forgot super().__init__() call in Fruit __init__ method
csa3d
Boom, ty
csa3d
Haven't considered super as an option here, this is great
 Jacob
Jacob
I'm using pony with a MySQL database. This database is (sadly) shared with other apps, so others are asking me: how many connections does pony establish in its pool?
Jacob
I don't see anything that lets me tune the size of the pool in the pony docs.
Jacob
I don't see anything about connection limits under pony.orm.dbapiprovider.Pool is that where I should be looking?
Jacob
So, if I'm reading right, there is one connection per thread right?
Jacob
Since I am only using one thread, that should mean the pool size will not ever be more than one. Right?
Anonymous
hi all
Anonymous
hope you're well
Anonymous
quick question
Anonymous
How do i update an item in an array ?
Alexander
Since I am only using one thread, that should mean the pool size will not ever be more than one. Right?
Yes, if your application is single-threaded, Pony will use at most one connection per process
Alexander
How do i update an item in an array ?
A usual way as you do in Python:
my_object.array_field[index] = item
my_object.array_field.append(item)
etc
Jacob
Anonymous
thanks @metaprogrammer but i want to update the table in the db, not just the array !
Alexander
Maybe I don't fully understand, what do you mean by array. Is it an object field of array type or what?
Anonymous
its a Set()
Anonymous
that i have declared on my schema
Matthew
my_object.my_set.add(x)
Anonymous
but for update ?
Matthew
update an object in the set?
Anonymous
yep
Matthew
How are you trying to get the individual object?
Anonymous
s = Scale.get(id=scale['id'])
s.set(**without_keys(scale, ['id']))
Anonymous
i tried this but it looses the context
Matthew
so you want to update all objects in the set?
Anonymous
the set is part of an dict, and some items of the set may change..
Matthew
Show your schema please
Matthew
the relevant part of it
Alexander
> i tried this but it looses the context
What do you mean? Did you get some exception?
Anonymous
I almost there. I have this error now
AttributeError: 'ScaleSet' object has no attribute 'append' // Werkzeug Debugger
Alexander
Use add instead
Anonymous
when i do this fb.comparisonQualScale.append(Scale(**scale))
Anonymous
thanks
Anonymous
Hello again,
i have an other error while updating my nested set:
pony.orm.core.UnrepeatableReadError: Value of Scale.source for Scale[UUID('9f04f012-22ed-4e5a-b0db-a20dc9998bbe')] was updated outside of current transaction (was: 'GCA', now: <ScaleSource.GCA: '{name: GCA-scale for Global Cortical Atrophy, range: [0, 39]}'>) // Werkzeug Debugger
Anonymous
the db orm is in a strange state ..
Alexander
What is the type of Scale.source?
Anonymous
a list
Alexander
You mean Set
Anonymous
yes
Anonymous
here is my function
Anonymous
@feedbacksRouter.route('/<uuid:feedbackId>', methods=['PATCH'])
@login_required
def path_feedback_by_id(feedbackId):
requestBody = request.get_json()
fb = Feedback.get(id=feedbackId)
comparisonQualScale = requestBody.pop('comparisonQualScale')
for scale in comparisonQualScale:
if 'id' in scale:
s = Scale.get(id=scale['id'])
s.set(**without_keys(scale, ['id']))
else:
fb.comparisonQualScale.add(Scale(**scale))
fb.set(**requestBody)
commit()
return jsonify({
'completion': 50,
'feedback': fb.serialize({
'launchDate': fb.analysis.created_at
})
})
Alexander
Can you show your models?
Anonymous
class Scale(db.Entity):
_table_ = 'Scale'
id = orm.PrimaryKey(UUID, default=uuid4)
feedback = orm.Optional('Feedback')
source = orm.Required(ScaleSource)
score = orm.Optional(int)
def serialize(self):
return self.to_dict()
class Feedback(db.Entity):
_table_ = 'Feedbacks'
id = orm.PrimaryKey(UUID, default=uuid4)
comparisonQual = orm.Optional(Choice)
comparisonQualScale = orm.Set(Scale)
createdAt = orm.Required(datetime, default=datetime.now)
updatedAt = orm.Required(datetime, default=datetime.now)
Alexander
What is ScaleSource.GCA?
Anonymous
an Enum
Alexander
Can you show the definition of ScaleSource entity?
Anonymous
class ScaleSource(Enum):
"""
Visual scales considered to asses brain atrophy and white matter
hyperintensities lesions.
"""
MTA = '{name: MTA-scale for Medial Temporal lobe Atrophy, range: [0, 4]}'
GCA = '{name: GCA-scale for Global Cortical Atrophy, range: [0, 39]}'
KOEDAM = '{name: Koedam score for Parietal Atrophy, range: [0, 3]}'
FAZEKAS = '{name: Fazekas scale for WM lesions, range: [0, 3]}'
WAHLUND = '{name: Wahlund scale for WM lesions, range: [0, 30]}'
Anonymous
this line creates havoc # s.set(**without_keys(scale, ['id']))
Alexander
At this moment Pony does not support Enum type for attributes, I'm surprised that you were able to define source attribute as
source = orm.Required(ScaleSource)
At this moment I suggest you to define attribute as orm.Required(str) and assign enum_value.name (like ScaleSource.GCA.name) to it
Anonymous
ok thanks for your advice, however the issue is that i try to update 2 tables at the same time
Anonymous
Scale and Feedbacks
Anonymous
i am new to pony, I don't get the diferencce between flush and commit