 Ben
Ben


I think I found an horrifying bug
Ben
not sure if from Pony or from Postgres
Ben
I am using the sum function from pony (orm.sum)
Ben
On a Decimal value
Ben
And it seems like it's processed as a floating point
Ben
because I get a floating point amount
 Alexander
Alexander
Hi, let me check...
Ben
In my example, I do the sum of 9 payments, with decimal amount
Ben
50000
2000
1000
4285.71
6428.57
0
142.86
-142.86
43285.71
Ben
and I call orm.sum(payment.amount for payment in Payment if payment.account = account)
Ben
and I get 106999.98999999999
Ben
If you need help reproducing the issue
Ben
or want a minimal snippet to reproduce let me know
Alexander
I tried a quick example with numbers that you provided and got Decimal('106999.99') as result
so maybe a code snippet will be useful to be sure we perform testing the same way
also, what Pony version do you use?
Alexander
Is it possible that you originally defined column as float, then change it to Decimal in Python code, but the database column is still real?
Ben
i use 0.7.11
Ben
tried with 0.7.10
Ben
I did make a change
Ben
let me check the database
Ben
actually no
Ben
didnt make a change on that column
Ben
Oh wait
Ben
it actually works with Postgres it seems
Ben
but doesnt with in memory SQLite
Ben
that I use for my tests
Alexander
Thanks, i was able to reproduce it on SQLite!
Ben
Amazing!
Alexander
SQLite has pretty rudimentary type support, and does not know anything about Decimal type. Because of this, in SQLite Pony stores values of Decimal type as strings, and convert them to Decimal when read them from the database.
But it seems SQLite at this moment still convert such string values back to float, because it treats columns with DECIMAL type as columns with NUMERIC affinity (see 3.1 Determination of Column Affinity https://www.sqlite.org/datatype3.html) and for NUMERIC affinity, "when text data is inserted into a NUMERIC column, the storage class of the text is converted to INTEGER or REAL (in order of preference) if the text is a well-formed integer or real literal, respectively"
It is a bit surprising to me that SQLite assigns NUMERIC affinity to DECIMAL column, I thought it was not this way when we implemented Decimal type support, but maybe I missed it from the beginning.
So, in order to fix this bug we need to change the column type we use in SQLite for Decimal, in order to force a column to have TEXT or BLOB affinity. Looking at "3.1. Determination Of Column Affinity", we need to name type for Decimal columns something like DECIMALTEXT, to force storing decimal values in a textual form.
This in itself is not enough to fix SUM function behavior. Standard SQLite SUM function will still convert values to REAL before summing them up. But it is possible to define custom aggregate function py_decimal_sum using create_aggregate
https://docs.python.org/2/library/sqlite3.html#sqlite3.Connection.create_aggregate
Then Pony can automatically call this function instead of standard SQLite SUM function when sum is perfomed on decimal column.
This function will convert text values to decimal values on the fly, and then return result as a text value. It will perform slower then builtin SUM function.
But anyway this is not a total solution, because if you do for example sum(decimal_column) * 2 then SQLite still convert decimal value to REAL, because it does not have support of decimal values and does not know how to do arithmetic operations with them
 Lucky
Lucky
Okey, pony orm doesn't support async yet, doesn't it?
Alexander
yes
Lucky
Anyone has experience with async?
From what I can gather the only place where that would be relevant to go async would really be waiting for the query to execute, right?
Alexander
async model model does not fit well with transactions
Lucky
Strange, as there are many libraries for that already?
https://github.com/timofurrer/awesome-asyncio#database-drivers
 Permalink Bot
Permalink Bot
Strange, as there are many libraries for that already?
https://github.com/timofurrer/awesome-asyncio#database-drivers
Permanent link to the timofurrer/awesome-asyncio project you mentioned. (?)
Lucky
Strange, as there are many libraries for that already?
https://github.com/timofurrer/awesome-asyncio#database-drivers
Most of them is based on SQLAlchemy, which I don't enjoy as much as pony
Alexander
Real sync application can have many thousands simultaneous coroutines. If each coroutine open a separate connection to database and start long-lived transaction, it will not be too efficient
IMO the correct approach is to have a separate database layer which accessed from async code through a queue. But it is hard to implement it in a generic way as a part of framework/library
 Jacob
Jacob
Do you know of any example applications that go from async to sync via a queue? I'm having a hard time picturing how that works.
 Alexey
Alexey
Real sync application can have many thousands simultaneous coroutines. If each coroutine open a separate connection to database and start long-lived transaction, it will not be too efficient
IMO the correct approach is to have a separate database layer which accessed from async code through a queue. But it is hard to implement it in a generic way as a part of framework/library
I think it worth writing a post about it, as many people need to understand pros and cons of async and the best practices of working with this. @cognifloyd do you think that would help you?
Jacob
Yes please!
 Jim
Jim
Hi if you already have called bind and generate_mapping with some database filename (sqlite), how do you switch to another database file. I'm looking for something like "db.unbind" and then recall "bind" with a different filename.
Alexander
Currently it is not possible to unbind database (it may change with migration release). But you can create new db instance. One way to do it is defining entities inside a functions:
def define_entities(db):
class Foo(db.Entity):
a = Required(int)
class Bar(db.Entity):
b = Optional(str)
db = Database()
define_entities(db)
db.bind(**params)
db.generate_mapping()
with db_session:
select(x for x in db.Foo)
db2 = Database()
define_entities(db2)
db2.bind(**params2)
...
The drawback is, IDE like Pycharm cannot understand what db.Foo is and which attributes it has
 ꧁Rhͪaͣpsoͦdͩoͦs93꧂
꧁Rhͪaͣpsoͦdͩoͦs93꧂
😁
Jim
thank you alexander for your help, It makes many changes since I use the db instance in various modules of the app. It"s au GUI app, for now I think I'll restart the app, I'll see it with the new relase
 Anzor
Anzor
Hi folks!
Just found this at https://github.com/ponyorm/pony/blob/orm-migrations/pony/orm/dbschema.py
Anzor
 Anzor
Anzor
 Permalink Bot
Permalink Bot
Hi folks!
Just found this at https://github.com/ponyorm/pony/blob/orm-migrations/pony/orm/dbschema.py
Permanent link to the file pony/orm/dbschema.py mentioned. (?)
Alexander
Thanks, it was a result of merge conflict. Fixed
Anzor
✋
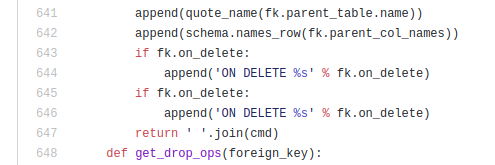
Another orm-migrations related issue. Currrently Entity._table_ attr is ignored while creating or altering a table. Is it ok or someone missed something?
Anzor
This is how migrate.operations.alter_table looks like
def alter_table(table):
schema = table.schema
quote_name = schema.provider.quote_name
return '%s %s' % ('ALTER TABLE', quote_name(table.name))
Jim
Hi, How do you check that binding is ok, something like : database.is_ready() ?
 Alexander
Alexander
You mean your bind arguments or connection?
Jim
I saw that I could have an OperationError if âuse a wrong ddb name (sqlite). I made a patch. I'd like to test my patch (fallback to another name) and so I'd like to test if database is ready.
Jim
when it's fallback
Alexander
Isn't db.provider is not None enough?
Jim
Tell me if it ils :-)
Alexander
Okay let me test it, few moments
Alexander
When you use bind function it actually tries to connect to the database. And if it doesnt - it shows an error.
Jim
ok I take it thanks
 Vitaliy
Vitaliy
Hello Alexander! As you may remember, I asked about the poor performance of bulk updates/inserts via Pony. I think I need to report that the Pony is perfect and that’s no problem there! 🙂 The reason was due to the large number of simultaneous threads that used the entire CPU core. I did some refactoring, and the scheduled tasks are now performed in the processes, so now the database performance is as fast as lightning 🙂
Alexander
Thank you Vitaliy for the good news! :)
 csa3d
csa3d
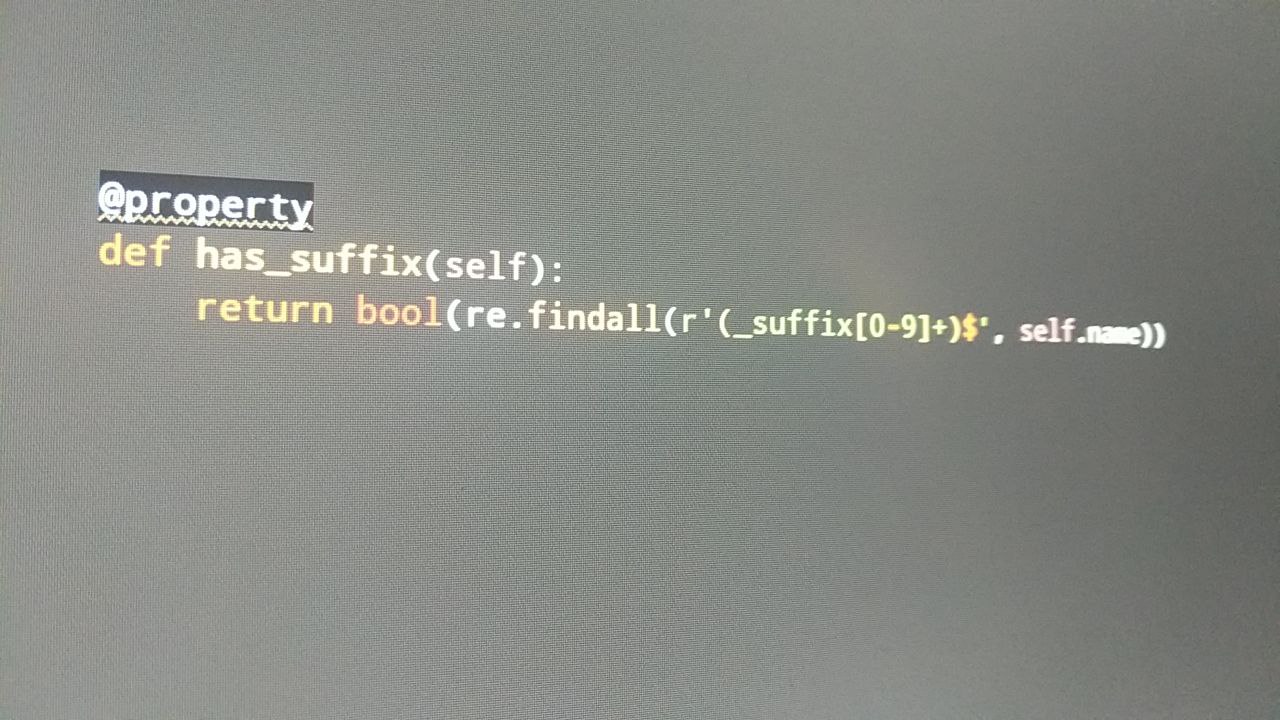
Can re.findall be used in an Entity property to return bool used to filter query?
csa3d
`@propertydef has_suffix(self):
Alexander
No, because I don't know how to translate it to SQL
csa3d
Ah, ok
Alexander
you can use raw sql fragments with database-specific functions
csa3d
 Anonymous
Anonymous
Guys, I am working on building a db which will have a special table type with many same tamles in them (is the plan) and then store references to the tables in another table. Can this be handles in Pony? And/or is it even good practice to do that; I have not done any such design me self before, but know other people have.
Matthew
What do you mean by same tamies?
Anonymous
sorry same tables
Anonymous
that is e.g., tableA, tableB and tableC are 3 table with same schema, just different data and table0 has a column e.g table_name with rows tableA, tableB, tableC in it
Matthew
what’s the benefit of creating multiple tables with the same schema?
Matthew
You could have a column in one table specifying the “type” of that row (A, B, C) and avoid the duplication
Jim
Or maybe inherit a,b,c from a X parent class and specify class type un table0
Matthew
I think inheritence is only worth it if you are creating variations from the same basic schema
Anonymous
The idea was that there is one attribute X of the table that could be places in the table name instead of in a column. Since the data will always be queried with a WHERE X=x0, the thinking was that this construction could speed things up and also the data will later be exported in groups of X=x0 also so it is kind of logical to divide it like that.
Matthew
I don’t think it is worth the added complexity to do that