 Alexander
Alexander


I think not yet
 dovaogedot
dovaogedot
Even unsafely?
✔️ I know what I am doing.
 Alexander
Alexander
There are some bytecode changes that we didn't look and and obvious not implemented
dovaogedot
Ну оно при установке ругается на то, что версия не знакома. Я думал может просто в исходниках убрать проверку и собрать :D
Alexander
you can try, but no guarantees at this moment
dovaogedot
 dovaogedot
dovaogedot
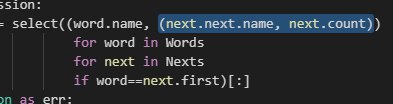
 Thore
Thore
what do i need to do in order to make objects with a UUID attribute json serializable? currently it fails with: TypeError: keys must be str, int, float, bool or None, not UUID
Thore
i'm using the to_json method from pony.orm.serialization
 Vitaliy
Vitaliy
 Matthew
Matthew
what do i need to do in order to make objects with a UUID attribute json serializable? currently it fails with: TypeError: keys must be str, int, float, bool or None, not UUID
Use to_dict() method on the entity. Use a dict comprehension to cast UUID to string. Then use json.dumps
Thore
mhm, i'm currently writing a custom JSONEncoder
Thore
but json.dumps seems to serialize one step too far, i actually want a properly prepared dict because flask/connexion is taking care of the json encoding later
Thore
if i do json.dumps myself it will be double-encoded
Thore
it seems a custom to_dict() method for my model is the best way to go
Thore
mh, even better would be to properly tell the flask/connexion json serialiser how to serialize the UUID attribute
Thore
managed to come up with a to_json_dict() method for my model that prepares the attributes properly
 Xavier
Xavier
Hi, I'm having a problem with ponyorm and I'm not able to detect where it fails. I'm doing an insert usign the ponyorm model but the insert don't apear on the postgres log. The return of the insert have a None by id
Alexander
Hi! You mean db.insert(...)?
Xavier
if i do json.dumps myself it will be double-encoded
No, using the model name, in this case TransactionLog
Alexander
When you do obj = TransactionLog(foo=x, bar=y) this just creates object in memory, it will be saved later. You can force insert by calling flush(), after that you will have id value
Xavier
but outside the db_session method should do the insert on the postgres?
Alexander
Yes, if it is the most outer db_session
Xavier
I'm not able to see the data via select on a psql
Alexander
Do you use some async framework?
Xavier
no, the more strange in this program is that I'm usign sockets
Xavier
Can this be related?
Matthew
Can you show your code?
Alexander
Program which work with sockets may use some async framework for that, like asyncio. Pony has problems with asyncio and similar frameworks. But if this program just use threads, it is fine
Xavier
the sockets are the python3 native sockets
Alexander
I suspect there is another db_session which is too wide in scope, like, wraps all your application
Xavier
Yes, if it is the most outer db_session
I noticed thats the problem. On the main function of the program i have a db_session , so i supose because of this makes the pony don't writes because don't exit the context
Xavier
I suspect there is another db_session which is too wide in scope, like, wraps all your application
Yes that is , on the main
Alexander
You should remove it
Xavier
I will move the code that requires this on a function to avoid this
Xavier
thank you to show me why this fails
Alexander
Sure
 Genesis Shards Community
Genesis Shards Community
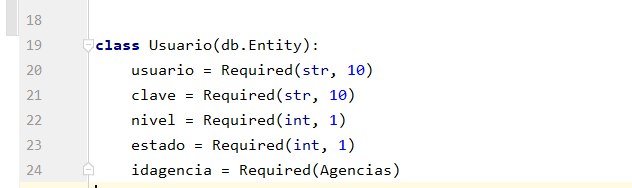
hi, helpme! please, error with nivel = Required(int, 1)
Genesis Shards Community
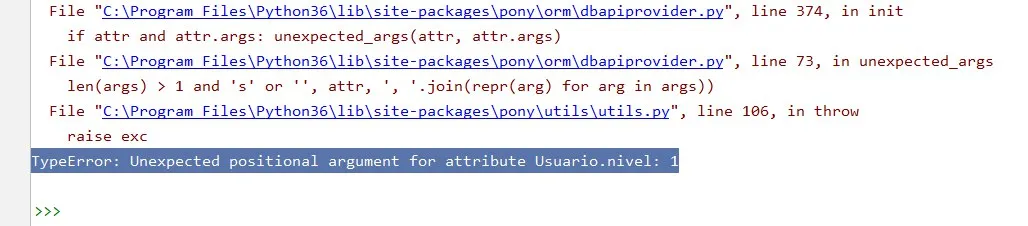
TypeError: Unexpected positional argument for attribute Usuario.nivel: 1
Genesis Shards Community
 Genesis Shards Community
Genesis Shards Community
 stsouko
Genesis Shards Community
stsouko
Genesis Shards Community
why?
stsouko
If U want default value, U need to use keyword argument: default=1
 Roman
Roman
Hi!
I'm writing a Python library to work with ConceptNet (http://conceptnet.io/) offline. There is an existing library from ConceptNet creators, but it requires PostgreSQL to be installed, which is not convenient for linguists. So, I rely on SQLite+Pony. I'm loading the dump by creating ORM objects. The problem is that there are 34074917 edges in the dump. Loading 100000 edges took 7 minutes.
Here is my PC info:
Operating System: openSUSE Tumbleweed 20190814
Kernel Version: 5.2.8-1-default
Processors: 4 × Intel® Core™ i5-3320M CPU @ 2.60GHz
Memory: 15,3 GiB of RAM
300 GiB SSD drive
By extrapolating I got 39 hours to load the dump. That's too much.
Is there a faster way? For example, store everything in memory, and save DB after the filling?
 Lucky
Lucky
 Alexander
Alexander
Alexander
Alexander
Hi!
I'm writing a Python library to work with ConceptNet (http://conceptnet.io/) offline. There is an existing library from ConceptNet creators, but it requires PostgreSQL to be installed, which is not convenient for linguists. So, I rely on SQLite+Pony. I'm loading the dump by creating ORM objects. The problem is that there are 34074917 edges in the dump. Loading 100000 edges took 7 minutes.
Here is my PC info:
Operating System: openSUSE Tumbleweed 20190814
Kernel Version: 5.2.8-1-default
Processors: 4 × Intel® Core™ i5-3320M CPU @ 2.60GHz
Memory: 15,3 GiB of RAM
300 GiB SSD drive
By extrapolating I got 39 hours to load the dump. That's too much.
Is there a faster way? For example, store everything in memory, and save DB after the filling?
Hi Roman! I'm not exactly understand what requires so much time. What do you mean by "load the dump", is it inserting new rows to the database, or reading data from database to memory?
Lucky
You should not load all objects to test them in memory. Try to formulate your query to retrieve only objects which need updating
It’s just “crawl the oldest pack again”, so with enough time it will be the whole database.
How can I unload an object?
Alexander
Objects are unloaded after db_session exit, but if you still hold reference to one of them in some global variable, it will hold other objects as well, because objects are interrelated via relationships. So, if you work with different db_sessions and does not hold references to objects in global variables, they should be unloaded automatically. You can also use option db_session(strict=True) to force object unloading even if you hold some reference in a global variable
Roman
Hi Roman! I'm not exactly understand what requires so much time. What do you mean by "load the dump", is it inserting new rows to the database, or reading data from database to memory?
Hi @metaprogrammer.
Here is the example of a row from CSV file:
/a/[/r/Antonym/,/c/ab/агыруа/n/,/c/ab/аҧсуа/] /r/Antonym /c/ab/агыруа/n /c/ab/аҧсуа {"dataset": "/d/wiktionary/en", "license": "cc:by-sa/4.0", "sources": [{"contributor": "/s/resource/wiktionary/en", "process": "/s/process/wikiparsec/1"}], "weight": 1.0}
Here is the ER diagram for my library: https://editor.ponyorm.com/user/iqt/conceptnet_lite/designer
Here is the page, where you can download the gzipped CSV dump: https://github.com/commonsense/conceptnet5/wiki/Downloads
I read file line by line using standart CSV module and create the objects in a for loop.
Roman
The file of SQLite db grows ~0.1 MiB/s, but I do not call commit explicitly.
Roman
@metaprogrammer I can send you the code if you want to replicate. It's dirty, so I didn't push it to GitHub yet.
Lucky
Objects are unloaded after db_session exit, but if you still hold reference to one of them in some global variable, it will hold other objects as well, because objects are interrelated via relationships. So, if you work with different db_sessions and does not hold references to objects in global variables, they should be unloaded automatically. You can also use option db_session(strict=True) to force object unloading even if you hold some reference in a global variable
Can I somehow find out how many objects are cached?
There are multiple jobs running on the celery worker, and I couldn’t yet figure out which one is the one with the memory leak.
Lucky
Objects are unloaded after db_session exit, but if you still hold reference to one of them in some global variable, it will hold other objects as well, because objects are interrelated via relationships. So, if you work with different db_sessions and does not hold references to objects in global variables, they should be unloaded automatically. You can also use option db_session(strict=True) to force object unloading even if you hold some reference in a global variable
Does the (strict=True) also work with
with orm.db_session:
…
?
Lucky
so like with orm.db_session(strict=True):
Lucky
How can I make sure that there are no db_session already active?
Alexander
How can I make sure that there are no db_session already active?
There is no official way, but you can use internal API for that:
if orm.core.local.db_session is not None:
# we already have db_session
print("Objects cached: %d" % len(db._get_cache().objects))
Alexander
Hi @metaprogrammer.
Here is the example of a row from CSV file:
/a/[/r/Antonym/,/c/ab/агыруа/n/,/c/ab/аҧсуа/] /r/Antonym /c/ab/агыруа/n /c/ab/аҧсуа {"dataset": "/d/wiktionary/en", "license": "cc:by-sa/4.0", "sources": [{"contributor": "/s/resource/wiktionary/en", "process": "/s/process/wikiparsec/1"}], "weight": 1.0}
Here is the ER diagram for my library: https://editor.ponyorm.com/user/iqt/conceptnet_lite/designer
Here is the page, where you can download the gzipped CSV dump: https://github.com/commonsense/conceptnet5/wiki/Downloads
I read file line by line using standart CSV module and create the objects in a for loop.
You can avoid creating object in memory while populating database from CSV file by using db.insert method:
with db_session:
...
for a, b, c in some_data:
id = db.insert(table_name, column1=a, column2=b, column3=c)
...
to be even more efficient, you can use low-level database connection:
# for postgresql replace ? to %s
sql = "INSERT INTO my_table (column1, column2, column3) values(?, ?, ?)"
with db_session:
connection = db.get_connection()
cursor = connection.cursor()
for a, b, c in some_data:
cursor.execute(sql, (a, b, c))
or
# for postgresql replace ? to %s
sql = "INSERT INTO my_table (column1, column2, column3) values(?, ?, ?)"
with db_session:
connection = db.get_connection()
cursor = connection.cursor()
params = []
for a, b, c in some_data:
params.append((a, b, c))
cursor.executemany(sql, params)
Roman
You can avoid creating object in memory while populating database from CSV file by using db.insert method:
with db_session:
...
for a, b, c in some_data:
id = db.insert(table_name, column1=a, column2=b, column3=c)
...
to be even more efficient, you can use low-level database connection:
# for postgresql replace ? to %s
sql = "INSERT INTO my_table (column1, column2, column3) values(?, ?, ?)"
with db_session:
connection = db.get_connection()
cursor = connection.cursor()
for a, b, c in some_data:
cursor.execute(sql, (a, b, c))
or
# for postgresql replace ? to %s
sql = "INSERT INTO my_table (column1, column2, column3) values(?, ?, ?)"
with db_session:
connection = db.get_connection()
cursor = connection.cursor()
params = []
for a, b, c in some_data:
params.append((a, b, c))
cursor.executemany(sql, params)
Well, the problem with cursor.executemany is that I do normalization during the CSV file reading. Let say for example we have those lines:
r0 n0 n1
r0 n0 n2
After reading the first line we need to create r0, n0, n1 and e0(r0, n0, n1). After reading the second line we should fetch ids of r0, n0 and create n2 and e1(r0, n0, n2). As you see, we cannot just collect all the nodes and relations, because some nodes and relations were already created before.
Please have a look at schema: https://editor.ponyorm.com/user/iqt/conceptnet_lite/designer
Roman
@metaprogrammer Why even after "PRAGMA synchronous = OFF" SQLite db file gets updated constantly even without explicit commits? I guess, Pony ORM forces it to do this. Isn't it?
Roman
Ok, got it: SQLite inserts the data when it sees that select was called. As I call select and insert in a cycle, db updates constantly.
Still have no ideas...
Matthew
is the dump the same for all users?
Matthew
so they are all generating the same sqlite file?
Roman
Yes.
Matthew
Generate it once and let users download it rather than force them to generate it?
Roman
Generate it once and let users download it rather than force them to generate it?
I agree with you, I want to do that.
But I also don't want wait for 2 days in case I made some mistake (misspelled field name, for example).
Matthew
I don’t see any obvious way to speed it up since you are normalizing the data
Matthew
I suggest you run it on 5% of the data
Matthew
and then see that it is loaded properly
Matthew
then generate the full database when the code is working correctly
Roman
Well, that's the best thing I can do, I guess. Thanks, @matthewrobertbell!
Matthew
Good luck!
Matthew
(maybe rent a fast server with fast disk to run this on)
Anonymous
Good morning and happy Sunday
Lucky
if I have a class Bar extending Foo,
would Bar.get(id=2) and Foo.get(id=2) return the same class?
Alexander
yes
Alexander
if it is Foo
Lucky
So it would select the correct class, basically ignoring what’s left of the .get