 Alexander
Alexander


By CTE queries I mean this: http://stackoverflow.com/questions/25896706/recursive-cte-query
I think you can use them in Pony using raw queries
Alexander
The graphical part of diagram editor uses JavaScript, the code generation part uses Python
 Angel
Angel
Congrats! It looks awesome!
Angel
plain js?
Alexander
Curently it uses KnockoutJS for templates and Raphael for SVG generation. Right now we rewriting it in ReactJS+Redux+FlowType
Angel

 Lucky
Lucky
 Lucky
Alexander
Lucky
Alexander
Sure. What database do you use?
Lucky
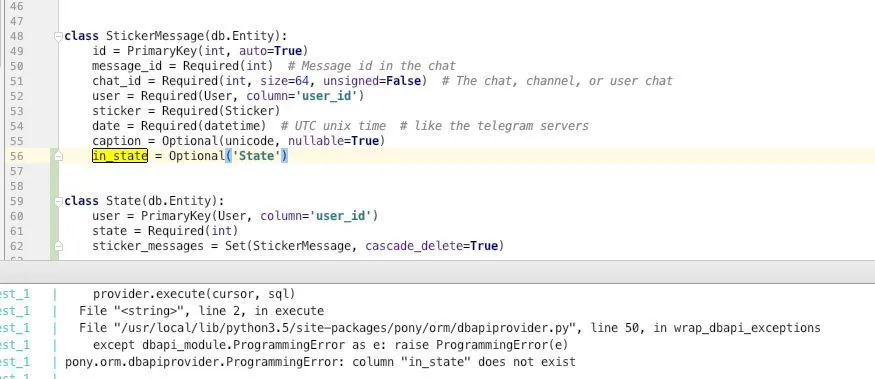
User has a id = PrimaryKey(int)
Angel
This is first class customer service!
Lucky
This is the schema: https://editor.ponyorm.com/user/luckydonald/Tags
Alexander
alter table "stickermessage" add column "in_state" int references "user"("id");
Lucky
Alexander
Thanks :)
Angel
I intend to read your project source. Any recommended reading before that?
 Alexey
Alexey
I intend to read your project source. Any recommended reading before that?
A bottle of Jack Daniels? 😄
Alexander
Do you mean sources of PonyORM?
Angel
yes sir
Alexander
Maybe documentation?
Alexander
You may be shocked while reading PonyORM sources, because currently they are not following PEP8 standard
Alexander
I used my own convention, which was convenient to me
Alexander
We plan to format it according to PEP8 before release 1.0
Lucky
Okey, now this is a tough one.
Context: One of my telegram bots, @StickerTagBot. This is the inline query search.
I have StickerMessages representing a sticker someone sent.
I want to filter them by user_id, and search the query_text.
Now the seach query should look in the .sticker.emoji field and the .string of any of the Tags (Sticker.tags, which is StickerMessage.sticker.tags[].string).
I got that working so far:
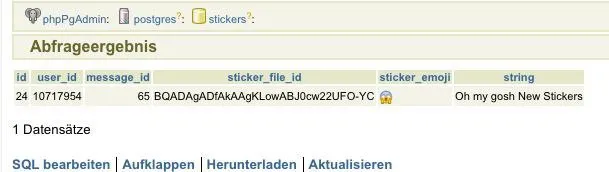
sticker_messages = orm.select(
st for st in StickerMessage
if st.user.id == user_id
for t in st.sticker.tags if query_text.lower() in t.string.lower() or query_text == st.sticker.emoji
).order_by(orm.desc(StickerMessage.date)).limit(50, offset=offset)
Now sticker_messages is a list of StickerMessage rows.
How can I make StickerMessage.sticker.file_id distinct here?
In other words, modify the query, so I get each StickerMessage.sticker.file_id only once (the newest, StickerMessage.date)?
This is my workaround:
known_ids = [] # is limited to 50 anyway.
for sticker in sticker_messages:
file_id = sticker.sticker.file_id
if file_id in known_ids:
continue
# end if
known_ids.append(file_id)
# do something with file_id
Lucky
Oh, and offset is a for pagination, it will be increased by 50, and that function called later again.
Alexander
Pony should add distinct by default if the result contains repeatable data. So, if you write:
select(st.sticker.file_id for st in StickerMessage if ...)
You should get distinct values
Lucky
 Lucky
Lucky
 Lucky
Lucky
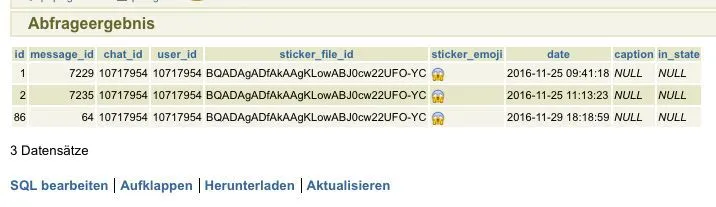
Sorry. My assumption was wrong.
That it is in there 3 times because of 3 tags, but actually because it was sent already 3 times.
Lucky
 Alexander
Alexander
If you select st.sticker.file_id instead of st you should see it once, I think
Lucky
Huh. Can it be that simple? I'll try.
Alexander
...but because of pagination you can get the same file_id on different pages. I'm not sure it is good to use pagination in this case.
Lucky
I have to, I can only send 50 entries at once.
Lucky
NotImplementedError: Ordering by attributes is limited to queries which return simple list of objects. Try use other forms of ordering (by tuple element numbers or by full-blown lambda expr).
Lucky
Hmm...
Alexander
.order_by(lambda: orm.desc(st.date))
Alexander
The IDE can warn you that st variable is not found, but don't worry about that
Lucky
 Lucky
Lucky
pony.orm.dbapiprovider.ProgrammingError: for SELECT DISTINCT, ORDER BY expressions must appear in select list
LINE 7: ORDER BY "st"."date" DESC
Lucky
Uh, this is really hard. I'm sorry...
Alexander
Ok, then PostgreSQL does not allow to combine ORDER BY x and SELECT DISTINCT y in the same query. Then maybe you can do DISTINCT part in Python:
messages = select(st for st in StickerMessage if ...).order_by(...)
file_ids = set(m.sticker.file_id for m in messages)
Lucky
Hm. Postgres SQL has a SELECT DISCTINCT(column1), column2 FROM table
Lucky
Because with the one above, I'll have to load all id's into memory first, and do cutting it to 50 for pagination later.
Lucky
Let me try to come up with a raw sql query.
Alexander
> SELECT DISCTINCT(column1), column2 FROM table
what does it do?
Lucky
> SELECT DISCTINCT(column1), column2 FROM table
what does it do?
 Lucky
Lucky
You can specify one (or possible multible?) of the colums you select to be distinct
Lucky
Lucky
Sorry.
SELECT DISCTINCT(column1) column1, column2 FROM table
SELECT DISCTINCT(column1) * FROM table
Alexander
I'm not sure it can be useful in your case
Alexander
I think the correct query is
pairs = select(
(st.sticker.file_id, max(st.date))
for st in StickerMessage
if st.user.id == user_id
for t in st.sticker.tags
if query_text.lower() in t.string.lower() or query_text == st.sticker.emoji
).order_by(-2, 1).limit(50, offset=offset)
file_ids = [ file_id for file_id, date in pairs ]
Lucky
This is looking promissing, yeah
Lucky
Yep. Thats it. Wonderfully working!
Can I write .order_by(desc(2), 1) instead of .order_by(-2, 1)?
Lucky
Does desc(2) make a -2?
Alexander
I think yes
 Alexander
Alexander
Cool
Lucky
 Lucky
Lucky
What is the difference between Optional and Nullable?
 Mark ☢️
Mark ☢️
Megaquestion
Mark ☢️
One of things that I can't understand
Lucky
Yay, I'm not alone!
Mark ☢️
Moreover, behaviour is different depending on the data type of the column!!
Mark ☢️
 Alexander
Alexander
The difference is for string attributes, which by default are optional, but not nullable. Otherwise it may be very annoying to search for empty string values, half of which is '' and another half is NULL
Mark ☢️
And what is the difference for nonstrings ?
Alexander
For non-strings, all Optional attributes are always nullable
Lucky
Okey, I was thinking Optional means you can leave it out when createing the object or something
Romet
so like blank in django orm?
Alexander
Yes
Alexander
Okey, I was thinking Optional means you can leave it out when createing the object or something
Yes, but also you can leave out Required attributes which have `default` option specified
Alexey
We described it here https://docs.ponyorm.com/api_reference.html?highlight=nullable#optional-string-attributes
Alexey
Does it explain enough?
Anonymous
I think I've found another bug but want to confirm here: If I have an entity with a volatile attribute, and I perform a select, then an update, then a to_dict() call, I get a KeyError inside a pony library function, A basic example is here: https://gist.github.com/chrisshroba/deb3bbff34261c88e1572a19b06123c3
Alexander
Thanks, fixed