 yopp
yopp


хм
yopp
коннекшенов чота 4к стало внезапно: https://yopp.in/Vm6
 Sergey
Sergey
Есть уже где-то список фич 3.4? Релиз в ноябре, еслм верить их JIRA. Пока нашёл только
Sergey
Release Notes - MongoDB
https://jira.mongodb.org/secure/ReleaseNote.jspa?projectId=10380&version=17091
Sergey
Наконец-то обещают case insensitive indexes
 Vasily
Vasily
добрый день, хочу удалить дубликаты из коллекции. Нашёл метод db.collection.ensureIndex({my_key:1}, {unique: true, dropDups: true})
нашёл даже примеры, где на коллекцию с дубликатами применяют этот метод и всё работает как надо - дубликаты удаляются.
Однако, когда я запускаю у себя этот метод, сообщается об ошибке ""errmsg" : "E11000 duplicate key error collection:" ну и указывается на первое встречающееся значение my_key, которое встречается в коллекции больше одного раза.
не подскажете, в чём я ошибаюсь?
 mardybm
mardybm
я думаю сначала нужно удалить дубликаты, а потом уже цеплять индекс
mardybm
как вариант можно создать вторую пустую коллекцию с этим индексом и перелить в нее документы из первой коллекции
Vasily
)) небанально, но сработает
почему-то не могу найти другого метода быстрого удаления дубликатов, кроме объявления индексов, мне в основном это кажется странным
Vasily
в любом случае, спасибо за совет!
 Anonymous
Anonymous
dropDups не работает уже давно.
Anonymous
Just in case.
Vasily
да, заметил потом, спасибо
вообще довольно распространённая, как мне кажется, задача, удалить документы из коллекции, в которых дублируется определённое поле. Теперь я понял, что нужно было заранее предусматривать такое и устанавливать индексы, которые бы не позволяли записывать подобные документы, но почему сложно найти простой механизм удаления дубликатов, я пока не уяснил.
Vasily
я согласен, что моя постановка вопроса, быть может, некорректна, и задача решается на этапе проектирования коллекций. Мне скорее просто важно оставить в коллекции любой из документов с повторяющимися bar. И, на мой взгляд, не совсем корректно сводить пример к _id, так как это ключ по умолчанию.
MXLTN
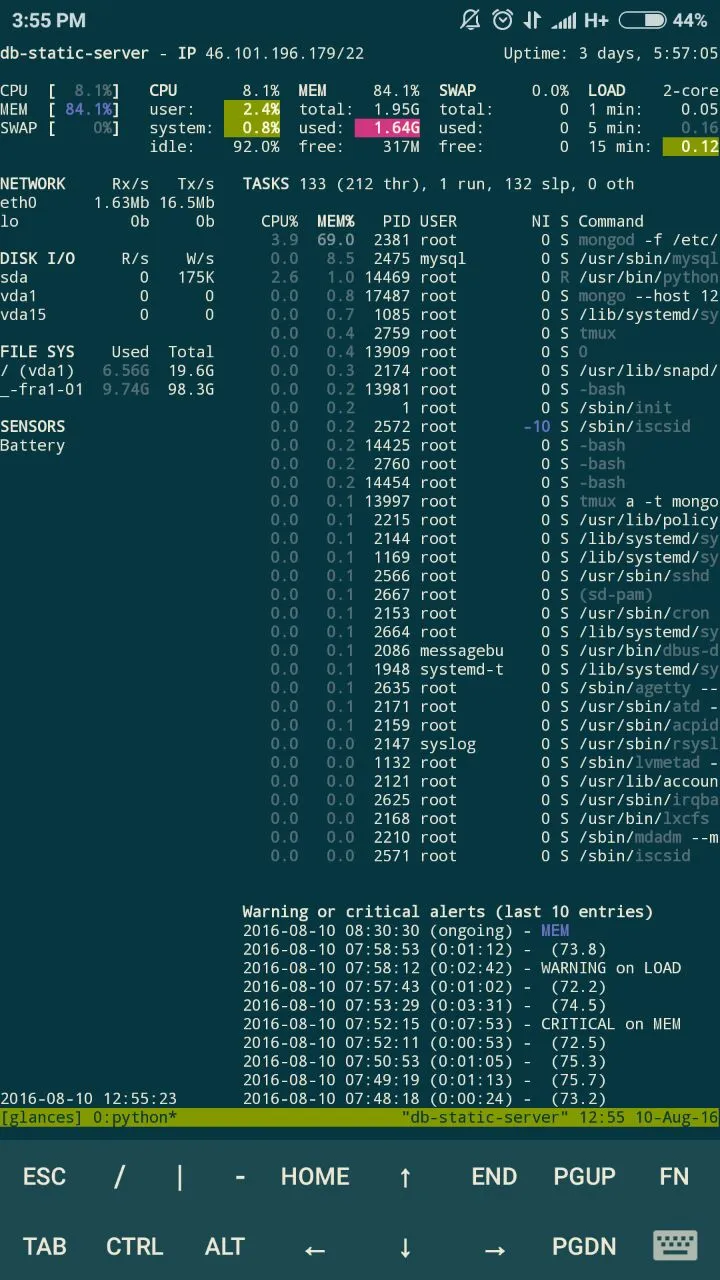
Привет, почему монга со временем сжирает 99% памяти? Каждый день приходится перезапускать
MXLTN
Монгодб килится
MXLTN
Куда смотреть?
Anonymous
Я вот тоже каждый день перезапускаю, но не из-за памяти.
yopp
эм
MXLTN
В доке написано, что оно хавает 65% от оперативки - 1гб или 1гб смотря что больше
MXLTN
У меня 2гб
MXLTN
Оперы всего
Anonymous
А кто убивает процесс-то?
MXLTN
Оно стабильно сжирает 95%
Anonymous
Ты уверен?
yopp
В доке написано, что оно хавает 65% от оперативки - 1гб или 1гб смотря что больше
если у тебя WT, это кеш самого WT
yopp
сама монга ещё может нормально жрать памяти вне WT
yopp
ну вот, там в документации написано что никто не гарантирует что монга не сожрёт больше
yopp
а она сожрёт
MXLTN
Но как бы безконтрольно
MXLTN
Аж до процесс киллд
yopp
killed это ось прихлопнула процесс, так как ядру не хватило памяти
MXLTN
 yopp
yopp
mysql и монга на одном хосте с 2 гигами памяти?
yopp
норм
MXLTN
Ну вот сейчас 84
MXLTN
Да но сиквел почти не юзается
yopp
включи своп
yopp
если не хочешь добавлять памяти
MXLTN
На сколько гб в этом случае имеет смысл свопа?
yopp
вощем-то из-за отсуствия свопа монгу тебе и убивают
MXLTN
Ск свопа можно выделить?
yopp
обычно выделяют половину памяти
yopp
можно ещё http://lwn.net/Articles/317814/
yopp
но ваще, если монге надо столько памяти, я бы добавил памяти
yopp
сколько индексы занимают?
MXLTN
Не знаю как узнать
yopp
https://docs.mongodb.com/manual/tutorial/ensure-indexes-fit-ram/
MXLTN
Per collection?
yopp
там слева есть отличное меню, в котором можно обнаружить db.stats()
MXLTN
Посчитал, где-то 700мб
yopp
ну вот
yopp
тебе памяти надо больше
yopp
если индексы не влазят в память всё очень плохо
yopp
а ещё надо место на горячие страницы
MXLTN
А как знать что они не влазят? 700мб влазит в 1.9гб
MXLTN
Как оценить в отношении того сколько нужно самой монге
yopp
2 гига памяти при учёте что 700 мегабайт только одни индексы это уже в притык
MXLTN
Понял
MXLTN
Спасибо
yopp
Как оценить в отношении того сколько нужно самой монге
есть понятие working set, это типа сколько суммарно занимают «горячие» документы и индексы
MXLTN
А горячие документы как-то измерить можно?
yopp
примерно прикинуть по avgobjsize и какое количество документов из коллекции используется
yopp
IO какое преобладает? R/RW/W?
yopp
если R то можно грубо 4 * размер индексов
yopp
хотя в любом случае, без метрик, это всё катание какашек
yopp
яб просто пока перетащил на тачку в 8 гигами памяти и посмотрел бы
yopp
скорее всего 8 гигов за уши хватит на ближашее время
yopp
монга очень чувствительна к количеству памяти
MXLTN
хотя в любом случае, без метрик, это всё катание какашек
А метрики, внутренние монговские статсы?
yopp
да
yopp
можно взять прометея, если на MMS денег жалко
yopp
об этом в доке мне кажется везде написано
MXLTN
Prometheus.io?
MXLTN
Общий вопрос, насколько хороша монго для больших объёмов документов? Ну вот например 200к и это только начало, через год уже будет за 5 млн доков, стоит уже задумываться над каким-то другим решением или при правильной настройке монга может схавать?