Почему ты думаешь что проблема именно в этом? Покажи ошибку сборки контейнера.
Разобрался) этот сайт не работает уже больше двух лет(дальше не проверял)
Ошибкой сборки на локалке так и не понял что послужило
А вот на vds на прод приложение не собиралось из-за того что не было места на диске 🤣
Почистил диск, обновил ноду и полетели
 精神に強い
精神に強い


 Null
Null
Разобрался) этот сайт не работает уже больше двух лет(дальше не проверял)
Ошибкой сборки на локалке так и не понял что послужило
А вот на vds на прод приложение не собиралось из-за того что не было места на диске 🤣
Почистил диск, обновил ноду и полетели
Только что проверил. Работает. apt вытягивает оттуда пакет.
То что ссылка на каталог выдаёт 404 ещё не говорит о том что по прямой ссылке пакета нет.
Null
Если интересно, то вот так он получает список доступных пакетов:
https://dl.google.com/linux/chrome/deb/dists/stable/main/binary-amd64/Packages
Вот прямая ссылка на пакет:
https://dl.google.com/linux/chrome/deb/dists/stable/pool/main/g/google-chrome-beta/google-chrome-beta_123.0.6312.28-1_amd64.deb
 👨💻
👨💻
Есть ли способ установить рандомный список шрифтов в инстанс браузера пупетира ?
https://pixelscan.net
Выдает мне мои 55 шрифтов, что скорее всего в винде или стандартным браузером установленено.
И чёт сколько не пытался, не могу понять, как обычные шрифты то рандомить при запуске браузера
Marto
всем привет. Ищу человека кто может написать скрипт под автоматический логин и валидацию данных с обратным ответом на мой сервер. Готов платить $$ за решение, просьба написать в ЛС
👨💻
page.on('request', async interceptedRequest => {
if (interceptedRequest.url() === 'https://url.com') {
console.log(interceptedRequest.response())
const responseJson = interceptedRequest.response();
data.push(responseJson);
}
interceptedRequest.continue();
});
как можно дождаться ответа от реквеста в новой версиси пупетира ?
чет как-то в доке жуть какая-то непонятная. Не получилось ее переварить
👨💻
Посмотрите page on "response"
я вот эти чудеса смотрю уже оч долгое время. Но я вообще ничего не понимаю
👨💻
page.on('response', async (responce) => {
if (responce.url() === 'https://urltowait.com') {
console.log(responce.status())
const data = await responce.text()
console.log(data)
}
}) ну вроде как мне responce.status() выдает статусы 200, но при этом
const data = await responce.text() не отрабатывает, вызывая ошибку
ProtocolError: Could not load body for this request. This might happen if the request is a preflight request.
Как такое решить можно ?
 Captain Maslori
Captain Maslori
page.on('response', async (responce) => {
if (responce.url() === 'https://urltowait.com') {
console.log(responce.status())
const data = await responce.text()
console.log(data)
}
}) ну вроде как мне responce.status() выдает статусы 200, но при этом
const data = await responce.text() не отрабатывает, вызывая ошибку
ProtocolError: Could not load body for this request. This might happen if the request is a preflight request.
Как такое решить можно ?
1. response а не responce
2. обратите внимание на сигнатуру второго параметра метода page.on: возможно, и я почти уверен, в переменную responce у Вас попадает объект запроса а не ответа
Captain Maslori
могу быть неправ т.к. puppeteer не трогал уже давно
👨💻
1. response а не responce
2. обратите внимание на сигнатуру второго параметра метода page.on: возможно, и я почти уверен, в переменную responce у Вас попадает объект запроса а не ответа
вот запроса body
page.on('request', async interceptedRequest => {
if (interceptedRequest.url() === 'https://url.com') {
const postData = await interceptedRequest.fetchPostData()
if (postData) {
const obj = JSON.parse(postData)
}
}
interceptedRequest.continue()
});
👨💻
1. response а не responce
2. обратите внимание на сигнатуру второго параметра метода page.on: возможно, и я почти уверен, в переменную responce у Вас попадает объект запроса а не ответа
так у меня вроде как раз и response
Насколько я понял, это политика CORS какая-то. она блокирует получения ответа, поскольку запрос был автоматический
Captain Maslori
Я обратного и не говорил
Погуглил, да, я неправ, там объект ответа должен быть
Captain Maslori
Для дебага советую объект ответа целиком посмотреть, а не только на статус
Статус-код ничего не гарантирует, это зависит от конкретного сайта
👨💻
Captain Maslori
page.on('response', async (responce) => {
if (responce.url() === 'https://urltowait.com') {
console.log(responce.status())
const data = await responce.text()
console.log(data)
}
}) ну вроде как мне responce.status() выдает статусы 200, но при этом
const data = await responce.text() не отрабатывает, вызывая ошибку
ProtocolError: Could not load body for this request. This might happen if the request is a preflight request.
Как такое решить можно ?
Здесь выводится тело запроса, его нет, поэтому ошибка, я же предлагаю посмотреть на сам объект ответа
console.log(responce)
👨💻
Captain Maslori
Здесь выводится тело запроса, его нет, поэтому ошибка, я же предлагаю посмотреть на сам объект ответа
console.log(responce)
М/б сайт что-то в хедерах отвечает
👨💻
так у меня вроде как раз и response
Насколько я понял, это политика CORS какая-то. она блокирует получения ответа, поскольку запрос был автоматический
это чето из корсов. других причин пока не смог найти. Но ща запросов пару кину
👨💻
CdpHTTPResponse {}
CdpHTTPResponse {}
CdpHTTPResponse {}
CdpHTTPResponse {}
а потом я ищу че это за штука такая и вижу надпись
/* Excluded from this release type: CdpHTTPResponse */
И понимаю, что обречен. тип нафига вообще включать какие-либо данные и класс. тупо отрубить его с концами
Null
page.on('response', async (responce) => {
if (responce.url() === 'https://urltowait.com') {
console.log(responce.status())
const data = await responce.text()
console.log(data)
}
}) ну вроде как мне responce.status() выдает статусы 200, но при этом
const data = await responce.text() не отрабатывает, вызывая ошибку
ProtocolError: Could not load body for this request. This might happen if the request is a preflight request.
Как такое решить можно ?
Тебе же прямо пишут из-за чего ошибка может быть. У preflight-запросов нет тела, а ты пытаешься его получить. Найди как отличить preflight-запрос от обычного, и не запрашивай у него тело.
Null
Preflight-запросы имеют метод OPTIONS. Поэтому тебе нужно проверить его, например так:
page.on("response", async (res) => {
const method = res.request().method();
console.log(`method: ${method}`);
switch (method) {
case "OPTIONS":
// no body
break;
case "GET":
const text = await res.text();
console.log(`Response body len: ${text.length}`);
break;
case "POST":
// ...
break;
}
});
Null
Так же тебе выдаст ошибку, если ты попытаешься получить тело у редиректа: 'Response body is unavailable for redirect responses'.
Можно сделать проверку:
if (isRedirect(res)) {
return;
}
// ...
function isRedirect(res) {
for (const key in res.headers()) {
if (key.toLowerCase() == "location") {
return true;
}
}
return false;
}
Или так:
if (res.request().redirectChain().length > 0) {
return;
}
👨💻
я пока столкнулся с тем, что у class HTTPRequest нет метода ожидания ответа, а у class HTTPResponse нет проверки на метод.
то есть приходится городить через слушатели как раз сложную логику.
У меня прикол в том, что сначала как раз идет option запрос, а потом post запрос. И все пытаюсь отследить именно post запрос.
А post запрос от long-polling запрос. То есть либо сразу ошибка приходит, либо 1-2 минуты ждет и получает ответ.
И нельзя тупо сделать
const finalResponse = await page.waitForResponse(
response =>
response.url() === waitingUrl && response.method() === "POST" // method() отсутствует тупо. то есть так нельзя.
)
поэтому пришлось городить вот так
const finalResponse = await page.waitForResponse(
response =>
response.url() === waitingUrl && response.status() === 422
, {
timeout: 3000
})
.catch((error: TimeoutError) => error); чисто по статусу. А есть все же лонг полинг идет, то просто напросто тайммаут срабатывает
👨💻
Preflight-запросы имеют метод OPTIONS. Поэтому тебе нужно проверить его, например так:
page.on("response", async (res) => {
const method = res.request().method();
console.log(`method: ${method}`);
switch (method) {
case "OPTIONS":
// no body
break;
case "GET":
const text = await res.text();
console.log(`Response body len: ${text.length}`);
break;
case "POST":
// ...
break;
}
});
вот это строчка интересная.. не додумался я до такого)
Спасибо большое
👨💻
есть какие-это эффективные способы удаления текста из textarea ?
export async function clearText(page: Page) {
const textarea = await page.$('textarea[data-testid="test-text-area"]')
await textarea?.click({count: 3})
await textarea?.press('Backspace')
} такое вот оформил, но не уверен, что это лучшее решение
Null
есть какие-это эффективные способы удаления текста из textarea ?
export async function clearText(page: Page) {
const textarea = await page.$('textarea[data-testid="test-text-area"]')
await textarea?.click({count: 3})
await textarea?.press('Backspace')
} такое вот оформил, но не уверен, что это лучшее решение
document.querySelector("SELECTOR").textContent = "";
👨💻
document.querySelector("SELECTOR").textContent = "";
Аа.. а вместо .textContent .value использовал. Оно визуально убирала, а физически оставалось. Все никак понять не мог, в чем прикол
👨💻
document.querySelector("SELECTOR").textContent = "";
Где это фронтед приколы изучить вообще можно ? Это действия над домом и возможные вариации всего этого ?
Null
Где это фронтед приколы изучить вообще можно ? Это действия над домом и возможные вариации всего этого ?
https://developer.mozilla.org/en-US/docs/Web/HTML/Element/textarea
 Андрей
Андрей
Всем привет, кто-то с wildberries через puppeteer работал, есть там у них какие-то защиты?
Eugene
Привет. Есть скрипты на puppeteer, которые крутятся на лямбдах. Задача скриптов - делать скрины всех входящих писем на 3 почтовых сервисах.
Проблемы:
- проверка ящиков инициируется кроном, а не в момент, когда приходит письмо. Из-за этого лямбда бегает в холостую, а время ожидания между пришедшим письмом и скрином может быть долгим
- возникают проблемы со скринами. не всегда хватает нужную область. Есть проблемы с непрогрузкой изображний писем, соответсвенно кривые скрины получаются на выходе
Идеальный сценарий:
- лямбда ранается, когда в почте новое письмо
- если есть пробелма с прогрузкой, перезагрузка страницы
- если что-то упало, то письмо проходится повторно следующей лямбдой (сейчас чекаются только непрочитанные, а упасть может в момент прочтения и назад в непрочитанное не вернется)
Ищу человека, кто возьмет текущее решение и допилит до ума. Сделает его максимально стабильным. Естественно за обговариваемое заранее вознаграждение
 gud3
gud3
Как вариант слушать через imap+socks входящие, при поступлении нового письма бросать ивент в sqs на триггер которого будет заасайнена лямбда.
Либо более не надёжный: всегда держать горячую сессию. Тобиш уйти с лямбды на сервер, где под каждый аккаунт будет свой браузер 24/7 обновлять страницу. Тут можно без очередей, лямбд и триггеров сразу делать скрин.
 Aleksey
Aleksey
всем привет!
Кто-нибудь сталкивался с ситуацией, когда единственный инстанс браузера открывается с параметром --incognito, но при открытие новой страницы все равно приводит к открытию неинкогнито а обычного браузера, в котором и открывается новая вкладка?
Slavik
Aleksey
Зачем тебе режим не инкогнито?
Мне как раз он и не нужен, мне нужен режим инкогнито. Забил на открытие новой страницы, просто стал юзать ту, которая по умолчанию в режиме инкогнито открывается - этого хватило для решения задачи.
Slavik
Ребят, как я могу очистить кэш браузера и могу ли вообще это сделать?
Captain Maslori
xpath почти не знаю, но мне кажется что селектор прописан в неправильном формате (а конкретно его начало)
NO WAR!
NO WAR!
Всем привет.
Буквально сегодня начал изучать Puppeteer, поэтому прошу понять и простить.
Пытаюсь залогиниться на сайте при помощи Puppeteer. Ввожу мэйл, нажимаю кнопку, страница перебрасывает на капчу. Капчу пройти не могу, всегда пишет "неправильный ответ".
Пытаюсь залогиниться через Гугл (есть такая опция). Открывается окно с Гуглом, ввожу руками мэйл, нажимаю кнопку "Далее", Гугл пишет "возможно браузер небезопасен. Попробуйте другой браузер".
Как это обойти и залогиниться?
 Sasha
Sasha
Начать с решения капчи. Ловить её и пересылать в сервис решения.
Null
Ребят, как я могу очистить кэш браузера и могу ли вообще это сделать?
const client = await page.target().createCDPSession();
await client.send('Network.clearBrowserCache');
//await client.send('Network.clearBrowserCookies');
👨💻
const client = await page.target().createCDPSession();
await client.send('Network.clearBrowserCache');
//await client.send('Network.clearBrowserCookies');
Такая же проблема возникла. Со 150 мб в памяти и прослушиванием запросов, переросло в 500 мб на вкладке...
Null
Такая же проблема возникла. Со 150 мб в памяти и прослушиванием запросов, переросло в 500 мб на вкладке...
Это как-то много. Кэш ещё можно и ограничить в размере, или полностью отключить. Но тогда повысится потребление трафика.
NO WAR!
Народ, нужно написать достаточно простое приложение. Думал даже сам справлюсь, но чувствую что на капчу потрачу слишком много времени.
Если кто-то готов взяться, пишите в личку.
👨💻
Это как-то много. Кэш ещё можно и ограничить в размере, или полностью отключить. Но тогда повысится потребление трафика.
ну у меня картинки постоянно новые приходят в окне. Они сами весят по 2-8 мб. Может они не очищаются
 Сергей
Сергей
try {
const selector = "#checkDoc > form > div.row > div.col-md-4 > label > img.captchaImg";
await frame.waitForSelector(selector);
const captchaElement = await frame.$(selector);
if (captchaElement) {
const capchaImg = await captchaElement.screenshot({ encoding: "base64", type: "png" });
const file = "capcha.png";
const path = appRootDir + '\\data\\sanction\\' + file;
fs.writeFileSync(path, Buffer.from(capchaImg, 'base64'));
} else {
console.error('Элемент не найден');
}
} catch (error) {
console.error('Ошибка при создании скриншота:', error);
}
Подскажите, почему screenshot не фокусируется на селекторе, а вместо этого скриншотит середину страницы.
Null
try {
const selector = "#checkDoc > form > div.row > div.col-md-4 > label > img.captchaImg";
await frame.waitForSelector(selector);
const captchaElement = await frame.$(selector);
if (captchaElement) {
const capchaImg = await captchaElement.screenshot({ encoding: "base64", type: "png" });
const file = "capcha.png";
const path = appRootDir + '\\data\\sanction\\' + file;
fs.writeFileSync(path, Buffer.from(capchaImg, 'base64'));
} else {
console.error('Элемент не найден');
}
} catch (error) {
console.error('Ошибка при создании скриншота:', error);
}
Подскажите, почему screenshot не фокусируется на селекторе, а вместо этого скриншотит середину страницы.
Насколько помню, такая проблема проявляется именно в iframe. Нужно самому получить bounding box у элемента и у фрэйма. И вычесть начало фрэйма из начала элемента. И сделать скриншот по координатам.
Null
try {
const selector = "#checkDoc > form > div.row > div.col-md-4 > label > img.captchaImg";
await frame.waitForSelector(selector);
const captchaElement = await frame.$(selector);
if (captchaElement) {
const capchaImg = await captchaElement.screenshot({ encoding: "base64", type: "png" });
const file = "capcha.png";
const path = appRootDir + '\\data\\sanction\\' + file;
fs.writeFileSync(path, Buffer.from(capchaImg, 'base64'));
} else {
console.error('Элемент не найден');
}
} catch (error) {
console.error('Ошибка при создании скриншота:', error);
}
Подскажите, почему screenshot не фокусируется на селекторе, а вместо этого скриншотит середину страницы.
Попробуй так:
const frameElement = await frame.frameElement();
const frameBox = await frameElement.boundingBox();
const elementBox = await captchaElement.boundingBox();
await frameElement.screenshot({
path: "screen.png",
clip: {
x: elementBox.x - frameBox.x,
y: elementBox.y - frameBox.y,
width: elementBox.width,
height: elementBox.height,
},
});
👨💻
кто-нибудь запускал puppeteer в docker ?
столкнулся с подобной задачей, но пока чет не нашел никаких решений этого
Aleksey
Aleksey
есть какие-то гайды, как это правильно сделать ?
Делайте отдельный образ, который крутит браузер и присоединяйтесь к нему с другой тачки через puppeteer connect(...)
Чтобы прям совсем не заморачиваться, просто скачайте browserless образ - там уже все настроено для этого
Aleksey
https://hub.docker.com/r/browserless/chrome
Aleksey
неслабо он весит, 3 гб образ..)
Там куча фич, типа параллелизма из коробки - мега удобная штука
👨💻
Там куча фич, типа параллелизма из коробки - мега удобная штука
то есть что-то вроде экономии оперативной памяти, но при этом разных браузеров ?
В текущем варианте просто создаю инстансы браузеров и дальше работаю с ними. Никаких проблем не вызывало
👨💻
вообще штука прикольная. Не ожидал, что настолько все легко тут будет. Установил в докер и параметр browserWSEndpoint оставил. И работай сиди.
Спасибо большое!
👨💻
 👨💻
👨💻
import puppeteer from 'puppeteer-extra';
из puppeteer extra делаю все штуки, поскольку использую много аддонов из этой либы. Но у нее просто нет такого параметра 🥲
Aleksey
Aleksey
Скачайте ее и присоединяйтесь к инстансу
👨💻
Скачайте ее и присоединяйтесь к инстансу
ну ща //@ts-ignore поставлю. Поидее движок же пупетира берет, поэтому параметр должен пройти. Они просто забыли его добавить, видимо
Aleksey
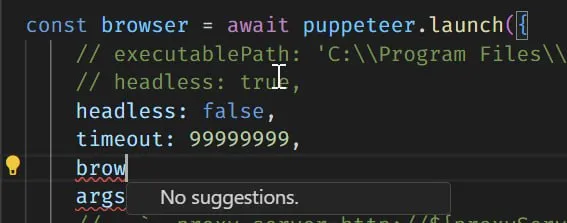
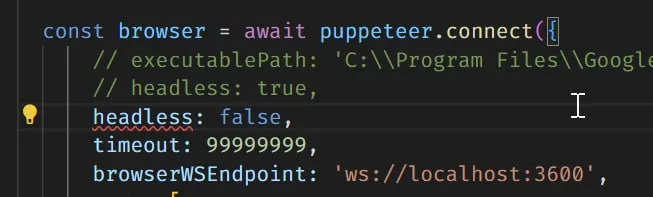
Просто надо юзать не лаунч() а коннект()
👨💻
 👨💻
👨💻
да уж, кажется это большая проблема. Нигде нет стартовых options
 Назар
Назар
да уж, кажется это большая проблема. Нигде нет стартовых options
почему нет? headless не нужно. потому что бразуер уже запущен и при запуске этот флаг указать нужно. А timeout это задержка перед стартом. Тоже можно при старте прописать этот флаг. Остальные есть.
👨💻
почему нет? headless не нужно. потому что бразуер уже запущен и при запуске этот флаг указать нужно. А timeout это задержка перед стартом. Тоже можно при старте прописать этот флаг. Остальные есть.
таймаут - это чтобы твой скрипт работал после окончания 30 секунд.
Пупетир если выполняет команды, то эти 30 секунд все равно идут. И если они пройдут, то браузер просто закроется.
👨💻
почему нет? headless не нужно. потому что бразуер уже запущен и при запуске этот флаг указать нужно. А timeout это задержка перед стартом. Тоже можно при старте прописать этот флаг. Остальные есть.
пока не нашел этого места нигде, в документации ни слова
Назар
это в документации докер image или хрома нужно искать.
Назар
https://docs.browserless.io/Docker/docker#connection-timeout
👨💻
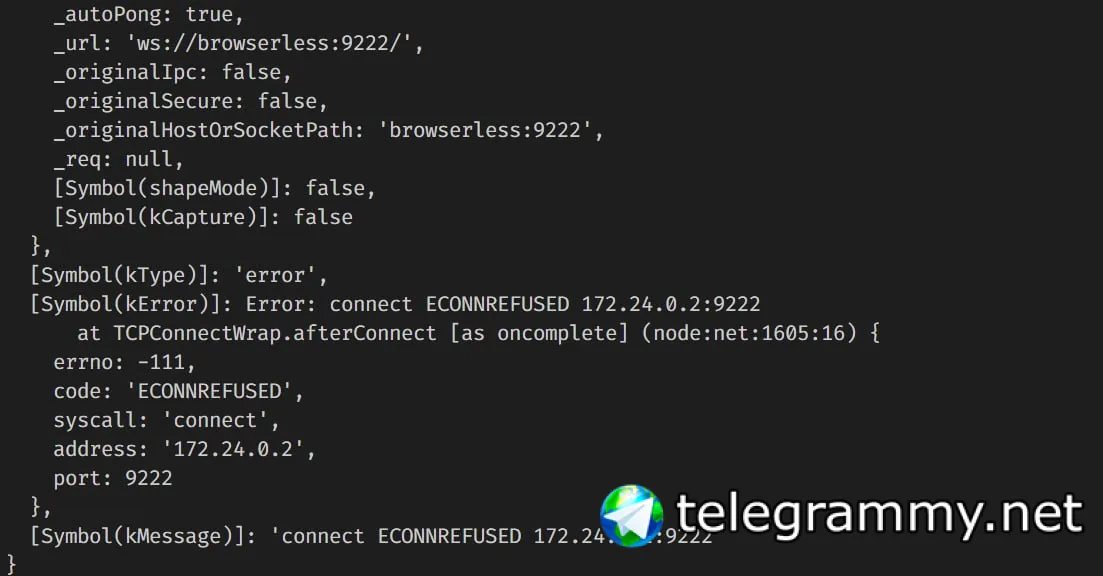
да уж, количество сервисов в yml файле все растет и растет
👨💻
 Назар
Назар