банальна берем тест fio и гоняем на количество потоков, увеличение производительности будет с каждым потоком.
зависит от количества осд
 Mark ☢️
Mark ☢️


 Anonymous
Anonymous
если у тебя софт внутри виртуалки генерит один поток, хоть ты 100500 ОСД поставить, скорость будет единтичной
Anonymous
и упрется в скорость записи primary OSD+реплики
Mark ☢️
ну не совсем
Mark ☢️
потому что писнул 4 метра в ПАМЯТЬ первого осд. НЕДОЖДАЛСЯ СИНКА. пошел писать второй блок и тд
Anonymous
я из-за этого и говорю, что ceph и thread=1 и depth=1 это писец зло
Mark ☢️
а потом в конце когда будет мегасинк (если будет вобще) но должен. то будет ожидаться параллельно
edo1
А какие цифры получаются в реале на однопоточной нагрузке?
Mark ☢️
что есть реал ?
Anonymous
Mark ☢️
ну и даже так -- оно там прописывается на магнитные как-бы в фоне. а когда гость даст команду на синк -- хуяк -- а оно уже на блинах
Anonymous
А какие цифры получаются в реале на однопоточной нагрузке?
thread=1 depth=1 30-40 МБ, при 30-40 IOPS'ов, тоесть блоком 1 Мб и это с тремя репликами
Anonymous
с 2 репликами будет ~50
Mark ☢️
попробуй с одной репликой -- охереешь
Mark ☢️
я так понял это связано тупо с задержкой по сети
Mark ☢️
между осд которая
edo1
Это совсем без ssd? Сеть какая?
Anonymous
рандомно, порядка 150 IOPS'ов, как раз упирается в HDD
Anonymous
это с журналами на SSD
edo1
А чтение?
Mark ☢️
а журналы какого размера ?
Anonymous
да все тоже самое
Anonymous
10-20 Гб картина одинаковая
Anonymous
соственно это и послужило написанию blustore
edo1
Так чтение не должно деградировать от числа реплик
Anonymous
теже БД, на Ceph ну ни как нормально не работают из-за такой особенности
Anonymous
Так чтение не должно деградировать от числа реплик
Открою тайну :)), чтения в Ceph происохдит медленнее чем запись
Anonymous
имеется ввиду последовательно
Mark ☢️
Открою тайну :)), чтения в Ceph происохдит медленнее чем запись
да, но чтение суперхот данных в виртуалках и так кешируется неплохо
Anonymous
ты меня еще про кэш спрашивал...тут ваще на лекцию хватит )
Mark ☢️
фап-фап-фап. ага. а что на практике ?
Anonymous
да, но чтение суперхот данных в виртуалках и так кешируется неплохо
ну как правило тесты все через drop cache гоняются..
Mark ☢️
ну как правило тесты все через drop cache гоняются..
тесты говенные. меряют ворст случай. а не реалистичный. ты же не проце не выключаешь кеш когда бенчмарки делаешь ?
Anonymous
тесты говенные. меряют ворст случай. а не реалистичный. ты же не проце не выключаешь кеш когда бенчмарки делаешь ?
Открываем любую доку по замеру производительности и видим там drop cache memory
Mark ☢️
это им не поможет если тест долгий
Anonymous
это и дает реалистичные тесты без учета кэшей
Mark ☢️
ну тогда да. прост кеши каг-бы пиздец помогают
Mark ☢️
тащемта если синки вызываются тогда когда хотел аффтар (на каждый врайт?) то хоть с кешем хоть без него.
edo1
Пж зовёт синк только на запись в лог
Mark ☢️
ну щас ага
Mark ☢️
а потом то он всеравно в основное место где таблицы синкает. только редко
Anonymous
вот тут поподробнее
тупо нет места для file cache :))). Да я на примере Oracle просто говорю
Anonymous
там еще и ASM, так что все мимо Posix IO
Mark ☢️
тупо нет места для file cache :))). Да я на примере Oracle просто говорю
ну тогда к ораклу. один хрен я уверен если они и используют о директ -- то у них свой кеш на чтение стопудово есть в оперативе
Mark ☢️
ну не пейджкеш тоесть. а свой собственный.
Mark ☢️
вот не похер
Mark ☢️
для цефа
Anonymous
если рассматривать чтение, то более менее продакшеновский софт читает отличной от depth=1, как правило 32, в связи с этим проблемы чтения не так сильно чувствительны.
Mark ☢️
пожалуй да
Anonymous
а вот с записью реально проблемы, т.к. основная масса СУБД (даже к некоторым NOSQL относится) пишут свои логи thread=1 и depth=1
Anonymous
и кэш тут не помогает, так как почти на каждый записанный блок СУБД делает fsync
Mark ☢️
поцггрес + асинк_коммит=Труе
Mark ☢️
но тут кагбы ничо не сделаешь...
Anonymous
поцггрес + асинк_коммит=Труе
несовсем, он их просто более большими блоками начинает писать и все равно делает fsync )
Mark ☢️
и как это рещает проблему?
Anonymous
один поток превращается в 4 (если 4 диска)
Anonymous
страйп же
Mark ☢️
дак проблема в мегабайтах в секунду или в иопсах ?
Anonymous
и в том и другом
Anonymous
 Anonymous
Anonymous
edo1 для тебя )
Anonymous
@edorus1
Mark ☢️
Mark ☢️
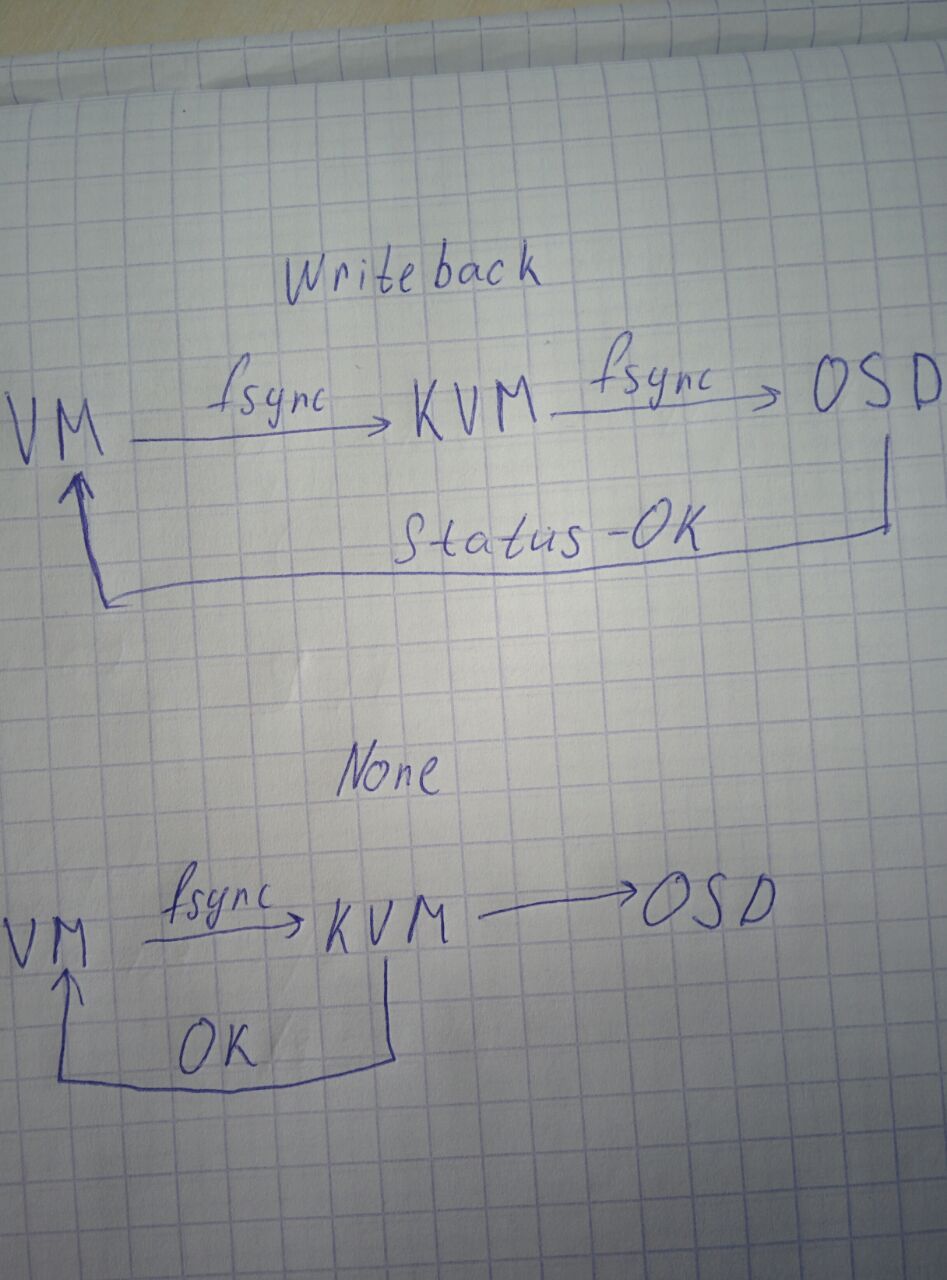
под лейблом ноне нарисован кеш=ансейф
Mark ☢️
кеш ноне вобще в цефе не реализуем. ибо это означает кароче о_директ и пропуск пейджкеша. какой нафиг пейджкеш в рбд
Anonymous
так, а с cache=writeback живая миграция в qemu считается unsafe?
Anonymous
если нужна сохранность данных и живая миграция - юзать write through?
Anonymous
ну да не понятно нарисовал, но суть будет такая же, т.к. да, none в librbd не реализован, вот и команда fsync завернется на KVM
Anonymous
из-за этого при некоторых особенностях cache none быстрее, чем cache writeback