Я так говорю потому что вместо конкретных проблем вы цитируете доки и говорите чо-то в духе "слышал, работает плохо". Без обид)
Вот смотри, ты не веришь разрабам и докам, все тестишь сам - молодец, мне бы столько свободного времёни. К тому же, не считаю себя умнее разрабов ceph, в плане его разработки, внутреннего устройства и работы. Поэтому если они пишут, что не стоит использовать ext4 потому то и потому - склонен верить
 Mike
Mike


 Mark ☢️
Mark ☢️
Аналогично
Mark ☢️
Я даже центос под ноды ставлю
Mark ☢️
Потому что это рекомендуемое. Хоть и говно
Mark ☢️
Но это тема друного чата
 J
J
Скопировал спецом)
J
We recommend against using ext4 due to limitations in the size of xattrs it can store, and the problems this causes with the way Ceph handles long RADOS object names. Although these issues will generally not surface with Ceph clusters using only short object names (e.g., an RBD workload that does not include long RBD image names), other users like RGW make extensive use of long object names and can break.
J
Под чистый рбд то есть ок.
VVSina
Гента + ceph + kvm. как раз 3 ноды. полёт нормальный.
 Александр
Александр
А то тут кое-кто не смог собрать и пытался понять как оно работает
Александр
:)
Александр
А не, тут нет его.
Anonymous
А не накидаете примеров настроек ceph, чтобы выжать из него по максимуму, с возможностью пережить ребаланс в момент дневной нагрузки
J
Не поможет)
Подбирать нужно под каждый конкретный кластер.
Anonymous
А что именно подбирать? Какие ручки крутить? У нас небольшой кластер в основном под образы rbd, подключаемых к linux физическим машинам, и вот хотелось бы эти образы хоть как то ускорить
J
Речь сейчас об ускорении RBD или о безболезненной починке? Или и то и то?
Anonymous
Об ускорении rbd, чинить ничего не требуется
Anonymous
В частности у нас на rbd сидит парьицированная mysql база под zabbix
Anonymous
И вот как то уж очень медленно она ворочается на чтение
Anonymous
И нельзя сказать что база большая, всего-то 200GB
J
Ну, по сути тут производительность повышать можно только кэшированием всяким.
J
rbd cache readahead, bcache во writethrough режиме или Ceph Cache Tiers.
Anonymous
Это у нам по мере возможности все есть
Anonymous
Я имею в виду кеширование в памяти
Anonymous
А вот насчёт cache tier
Anonymous
В этой рассылке натолкнулся на изречение что оно и не работает вовсе
Anonymous
Если что у нас ceph jewel
J
Оно работает, но очень специфично.
Если база все время горячая, к ней все время есть обращения и если она поместится в быструю кэш прослойку целиком, то да, это поможет.
Но с таким же успехом можно вообще сделать пачку OSD прямо на ssd дисках.
Anonymous
И вот насчёт bcache тоже вопрос
Anonymous
Насколько быстро можно на нем ухлопать ssd
Anonymous
При частой перезаписи?
J
Смотря какие SSD и смотря какая нагрузка.
Но если журналы и так на SSD, например, то чо уж там бояться)
Anonymous
Журналы мы только планируем на ssd(нет столько бюджета что бы все и сразу сделать)
J
А ssd сами есть?
Anonymous
И тут же вопрос упадет ли у нас apply latency на osd при журналировании на ssd
Anonymous
?
Anonymous
Ssd заложены в бюджет только на следующий месяц
Anonymous
Так что сейчас их нет
Anonymous
Я просто неоднократно встречал высказывания что журналы на ssd не дают большого профита
Anonymous
Но это по идее странно
Anonymous
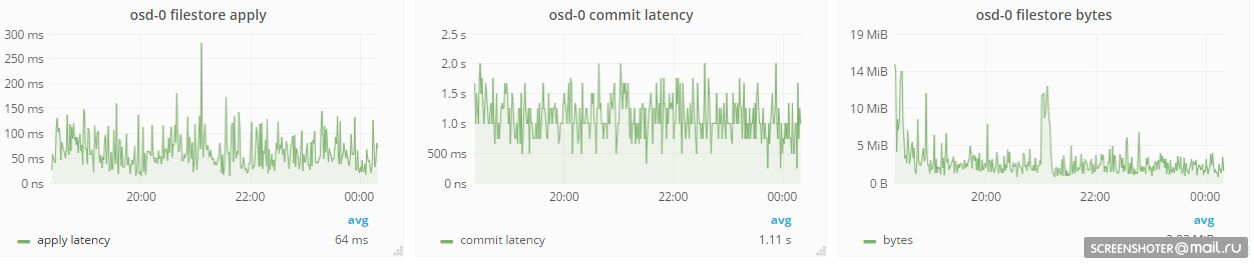
Я ожидаю существенного снижения apply latency сейчас оно у нас в районе 70-100ms
J
И тут же вопрос упадет ли у нас apply latency на osd при журналировании на ssd
Да, потому что транзакции будут считаться законченными сразу после того как в журналы всех OSD в placement группе запишется, диски ждать не придется.
Выходит, будет настолько быстрее насколько позволят SSD и сеть.
Anonymous
Угу большое спасибо за разьяснения
J
Хотя вот какой момент, я чо-то протупил.
J
Я то про commit latency тут.
Anonymous
Оо commit у нас секундами измеряется 1-2
Anonymous
Но если я все правильно понимаю он не так влияет как apply
Anonymous
На производительность rbd устройства
J
Стоп, я чего-то запутался.
Anonymous
Ну смотрите у нас на каждом osd apply latency в пределах 70-100ms
J
На ты можно же)
Anonymous
Commit latency на них где то 1-2 секунды(это когда я как понимаю происходит полный sync fs пороисходит)
Anonymous
При этом летннтность самого rbd устройства как раз 70-100ms
Anonymous
Если сравнивать с ssd простым бытовым это вообще тормоз
J
Наоборот.
В цефе commit latency - задержка на запись в журнал, грубо говоря, а apply - на слив в filestore.
J
Так что, странно что commit больше)
Anonymous
Разве?
J
Эт вообще не точно, а из головы вспоминал)
Ща прочту.
J
Ну вроде все верно я вспомнил.
Anonymous
 Anonymous
Anonymous
Возможно неверные термины я использую
J
А вот как даже.
commitcycle_latency:
—------------------------
Filestore backend while carrying out transaction, do a buffered write. In a separate thread it does call syncfs() to persist the data to the disk and update the persistent commit number in a separate file. This thread runs by default 5 sec interval.
This latency measures the time taken to carry out this job after the timer expires i.e the actual persisting cycle.
apply_latency:
—------------—
This is the entire latency till the transaction finishes i.e journal write + transaction time. It will do a buffer write here.
J
http://lists.ceph.com/pipermail/ceph-users-ceph.com/2015-July/002806.html
Anonymous
То что apply берется с служебного сокета osd и называется filestore.apply_letency
Anonymous
Получается все верно apply небольшой
Anonymous
А commit огромный
Anonymous
Потому как syncfs в нем дергается
Anonymous
У нас конечно оба этих параметра огромные
Anonymous
Дак все таки получается даст журнал на ssd снижение apply?
Anonymous
Или так как это все буферизированно, то ничего мы не получим?
J
А вот чо.
J
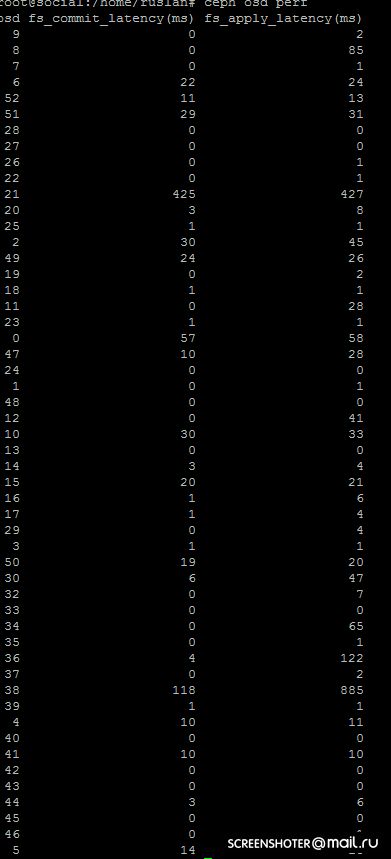
ЧТо показывает ceph osd perf? А то мне покоя это не даст.
Anonymous
Это все одно и тоже
Anonymous
Сейчас скрин запощу
Anonymous
 J
J
Ну так тут то commit latency ниже, выходит)
Anonymous
Тогда я не понимаю что за статистику ceph выдает в свои служебные сокеты