снапшоты пишут, что нельзя снимать
Снапшоты чего ?
 Mark ☢️
Mark ☢️


 Alex
Alex
Молча. Бекап делается через borg, при необходимости монтируем нужный архив и обычным cp льём на cephfs или в любое другое место
Mark ☢️
Ну да. Согласен. Пяка
Mark ☢️
Но можно выкрутиться подключив довекот к снапшоту и вытянув с него чо надопосредством имапного протокола
Mark ☢️
Т. Е. Перетаскиванием папочки мышкой
Mark ☢️
Сложнее да
Alex
Но можно выкрутиться подключив довекот к снапшоту и вытянув с него чо надопосредством имапного протокола
Я думаю будет люто тупить если сделать 20 снапшотов.
Mark ☢️
Mark ☢️
В качестве архива ибо монтируется
Mark ☢️
И жмет не хило
Mark ☢️
Хм. Гляну
Mark ☢️
https://github.com/bup/bup
Mark ☢️
Вот такое встречал. Но не юзал
Alex
Первый проход был долгим, так как на бекапе тормознутый гластер, с мелкими файлами не алё у него. Но потом очень шустро. 310 гиг за 15-20 кладёт в архив
Alex
https://borgbackup.readthedocs.io/en/stable/
Alex
Я его юзаю в данном случае. А так все от задач
Alex
Когда уже кто-то запилит курс по ceph с pool mirror, cephfs, cache tiring, rgw для продакшена и как для этого всего сделать disaster recovery?
Mark ☢️
https://www.qct.io/solution/index/Storage-Virtualization/QxStor-Red-Hat-Ceph-Storage-Edition
Alex
Сейчас RH продвигает активно GlusterFS. Ceph у них имеет слабый приоритет. Сегодня был разговор с человеком из шапки
 Anonymous
Anonymous
а гластер не разваливается? правда-правда? ;)
Anonymous
когда мы его юзали, там багов был вагон
Anonymous
но их активно чинят, да
 Dmitry
Dmitry
Они и ансибл
Dmitry
Активно чинят
Dmitry
Еще активней ломают правда
Anonymous
да, вот ансибл это 5+
Anonymous
ломать core модули - наши все
 Logan
Logan
в ансибл такое количество багов, что я не понимаю, что с ним делать вообще
то ли не пользоваться, то ли найти некий волшебный билд и пользоваться только им
Mark ☢️
Qcow2 на cephs - это пиздец ? Ну. Чтобы снапшоты виртуалок работали...
Mark ☢️
А то ебучий либвирт не умеет в снапшоты в rbd
kiosaku
proxmox?
 Mikhail
Mikhail
https://github.com/bup/bup
bup недоделан и заброшен, не умеет удалять старые бекапы,
borg неплох, еще zbackup есть
 Vlad
Vlad
А то ебучий либвирт не умеет в снапшоты в rbd
По opennebula снапшоты в rbd работали уже два года назад
Anonymous
Mark ☢️
По opennebula снапшоты в rbd работали уже два года назад
Надо не снапшот диска, а снапшот виртуалки
Евгений
Qcow2 на cephs - это пиздец ? Ну. Чтобы снапшоты виртуалок работали...
У меня пара виртуалок так работает. Особой разницы не увидел.
Anonymous
Там был разговор про mds и inodes. если mds работают в ином режиме и в кластере (один демон mds + еще один mds на другом сервере) таже фигня? Например так: fsmap e52: 1/1/1 up {0=nx4=up:active}, 1 up:standby-replay. В конфе ceph.conf добавлено (mds standby replay = true). и да, centos 7, kraken, bluestore (все как вы любите)
Dmitry
А где билд dokan для вин взять? Не находу чтото собранный
Dmitry
Он вообще пилится? Что то давно новостей по нему не видел
Dmitry
Нахожу*
Anonymous
поживее filestore
Anonymous
тесты гарантируют
Anonymous
и не зажирает ядра и память под 100%
Anonymous
с очередями
Anonymous
у меня обычные sas-sata вперемешку
Anonymous
без ssd
Anonymous
так что разница ощутима
Alex
Там был разговор про mds и inodes. если mds работают в ином режиме и в кластере (один демон mds + еще один mds на другом сервере) таже фигня? Например так: fsmap e52: 1/1/1 up {0=nx4=up:active}, 1 up:standby-replay. В конфе ceph.conf добавлено (mds standby replay = true). и да, centos 7, kraken, bluestore (все как вы любите)
Это режим называется горячий резерв. Если правильно настроено, то на резервном mds будет подтягиваться горячий кэш с активного, для быстрого переключения клиентов. Но по факту с клиентами будет всегда работать только один mds. И все вышесказанное про inode относится к данной ситуации. Есть варианты разные ceph fs привязывать к разным mds, но я пока это не тестировал. Слишком мало фидбеков от людей кто юзает cephfs не на кошечках и слишком много капитанства от тех кто ее "юзал" )))))
Anonymous
т.е. по логике, если сдох один, второй продолжит? или тоже подавится и свалится?
Alex
т.е. по логике, если сдох один, второй продолжит? или тоже подавится и свалится?
В идеале второй подхватит, на клиенте будет небольшой фриз по IO. Но если активный mds упал по причине трима журнала или чего-то подобного, то второй подхватится, но может не обслуживать запросы клиентов.
Anonymous
считаю что два лучше чем один. пока гоняю в своем проде, будем посмотреть как живут. перед эксплуатацией делал краштесты, просадка io была, но в целом переключался и работал дальше. спасибо за ответ
Alex
считаю что два лучше чем один. пока гоняю в своем проде, будем посмотреть как живут. перед эксплуатацией делал краштесты, просадка io была, но в целом переключался и работал дальше. спасибо за ответ
Два это однозначно нужно, чтоб они работали именно в стендбай-реплей. А у вас клиенты ядерные или fuse модуль используется?
Mark ☢️
 Mark ☢️
Mark ☢️
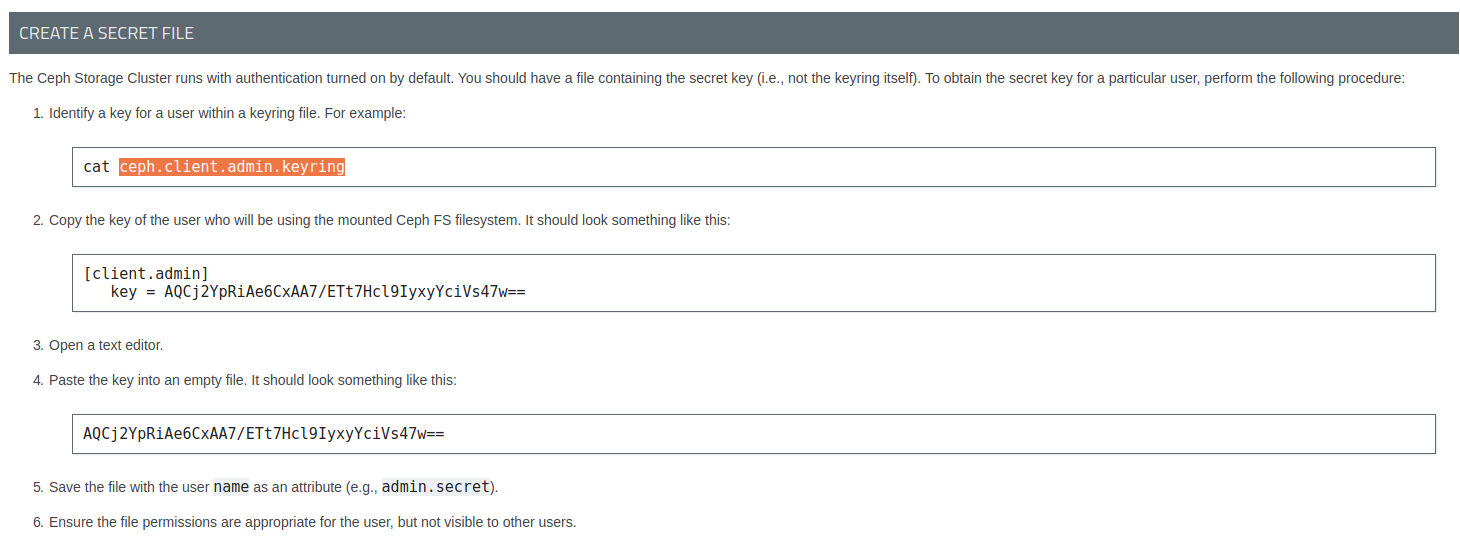
Возможно, я тупой, но я не могу понять пункт 5
Mark ☢️
слишком абстрактно
Anonymous
ядерные. кластер на centos 7, клиенты sles 12. через fuse пробовал на 11 но не фартануло, т.к. клиента никто не сделал. поэтому выдаю через nfs на старые
Anonymous
да, узкое горло, но с этим мирюсь
Alex
да, узкое горло, но с этим мирюсь
А можешь скинуть вывод команды ceph daemon mds.<name> perf dump mds
С активного и резервного. Хочу сравнить со своим хамеровским
Alex
Я его выше кидал
Anonymous
это на одной
Anonymous
щаз кину на пастебин
Anonymous
а то некрасиво наверно сюда
Anonymous
или можно?
Anonymous
https://pastebin.com/zMwfiAhn
Anonymous
https://pastebin.com/SHFGweuX
Евгений
А где билд dokan для вин взять? Не находу чтото собранный
Я с гитхаба собирал. Там билд-скрипт косоват, но можно разобраться
Mark ☢️
sudo mount -t ceph 10.80.20.99:6789:/ /qwe -o name=admin,secret=XXXXXXXXXXXXX
Mark ☢️
и всё зависло
Mark ☢️
команда маунт тоесть зависла
Mark ☢️
Я и ДИОД
Mark ☢️
забыл mds задеплойить