1С:Файловое хранилище
почему то представил бункер, весь залитый канализацией прорвавшейся, а внутри в ржавых сейфах дискеты 5.25. а особо важное на кассетах
 Sn00part
Sn00part


 Juriy
Juriy
 Juriy
Juriy
экие фантазии :)
Sn00part
не питаю иллюзий насчёт 1с
Sn00part
что то в одном ряду с заводом Омские шины
 Vladimir
Vladimir
они, кстати, заявляют, что по бенчмаркам уделывают ceph.
Vladimir
аж попробовать захотелось
Sn00part
а по функционалу они ceph уделывают?
Sn00part
не могу с ходу найти. что там внутри вкратце? глустер?
 Nick
Nick
virtuozzo storage - не теряет
Nick
вот только в реальной жизни 10 гигабит там уходит на три вдс, а дальше все
Vladimir
не могу с ходу найти. что там внутри вкратце? глустер?
не знаю. я только с виртуоззо контейнерами работаю
Vladimir
но из рекламного проспекта звучит красиво
 Михаил
Михаил
За извращениями пожалуйста в @cloud_flood
Sn00part
у нас постоянно российские компании что-то уделывают
Nick
ну и вообще ploop это такая, штука, которая с одной стороны хорошо, а с другой стороны больно дорого обходится
Sn00part
то мылору то 1с
Vladimir
ну, правды ради, контейнеры у них и правда неплохие
Vladimir
но со своими приколами :)
Vladimir
вот только в реальной жизни 10 гигабит там уходит на три вдс, а дальше все
а можно подробнее?)
Vladimir
но из рекламного проспекта звучит красиво
во, нашёл: https://virtuozzo.com/wp-content/uploads/vz7/doc/Virtuozzo7_Platform_Benchmarck_DS_EN_Ltr_20160720.pdf
Vladimir
это лучше в каком-нибудь соседнем чатике к @pavel_odintsov
ладно, сворачиваем оффтоп. извините )
 Mike
Mike
Поверю, что ceph может проиграть, например, scaleio, только scaleio это только блок и модули в ядре. А все остальное - придется городить рядом и терпеть перемещение данных между системами.
Mike
Когда рассматриваем систему в целом, вместе с openstack, например - выводы получаются другие.
Mike
Так же и с параллельными. С учётом, что это наши ребята. И верит рекламе, не хорошо.
Sn00part
ceph делают учёные, на большие бабки, плюс огромное коммьюнити и промышленные контракты. в такой ситуации 1с и другим крыть просто нечем. а зная эти все продукты изнутри, я бы с таким прикупом мизер бы не пошел
Sn00part
swapoff -a ; swapon - a?)
Sn00part
тогда все сломается. вот та утилита наверняка также делает
 Vlad
Vlad
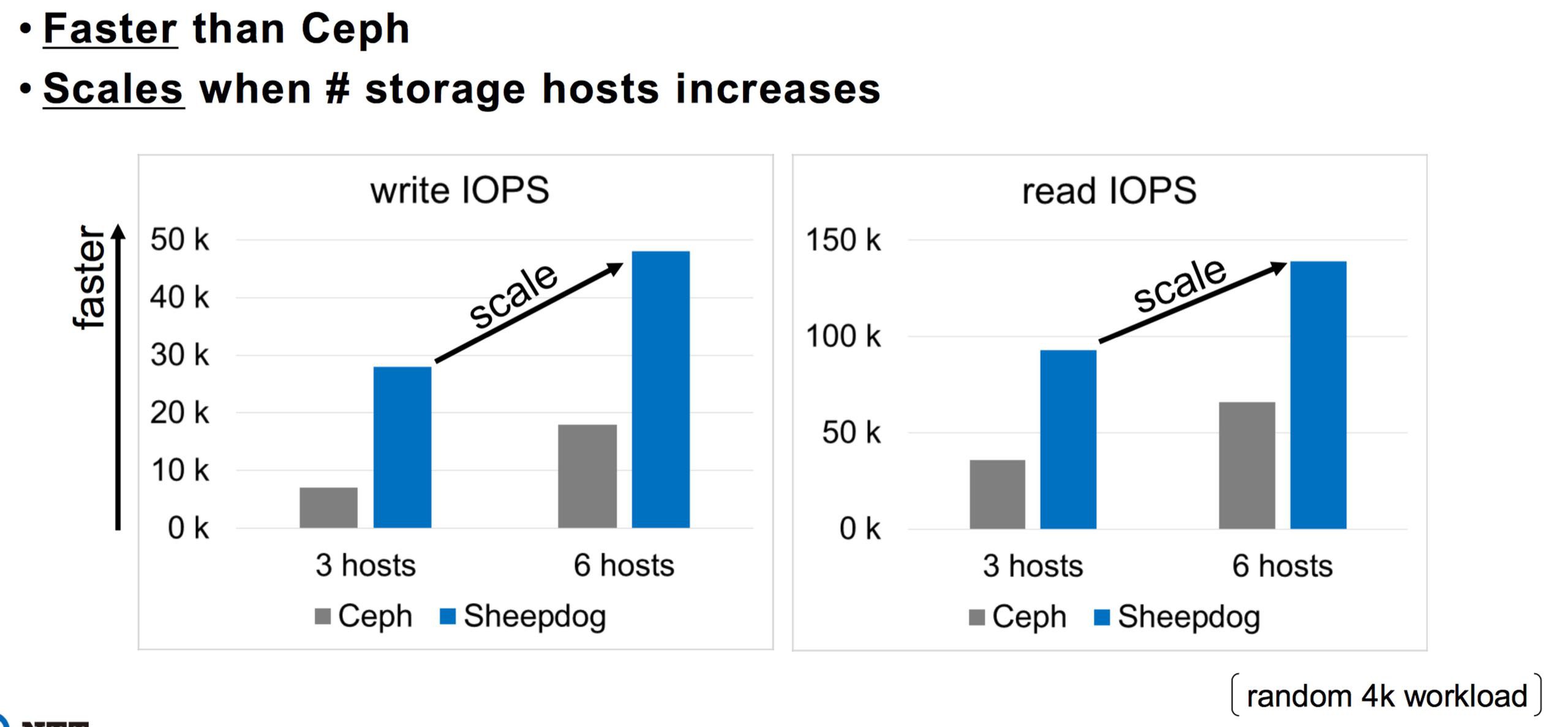
Кстати на sheepdog не пробовали делать кластер? Я пару лет назад делал - был быстрее ceph раза в три.
 Mark ☢️
Mark ☢️
Кстати на sheepdog не пробовали делать кластер? Я пару лет назад делал - был быстрее ceph раза в три.
Я возбудился. А он точно синкает когда нужно ? С тремя репликами ?
Mark ☢️
http://events.linuxfoundation.jp/sites/events/files/slides/COJ2015_Sheepdog_20150604.pdf
Vlad
https://sheepdog.github.io/sheepdog/_static/openstack-summit-2016-barcelona-vbrownbag-sheepdog.pdf
Vlad
 Vlad
Vlad
Я возбудился. А он точно синкает когда нужно ? С тремя репликами ?
я запускал с --nosync. Но у меня было два датацентра и дисковые кэши с батарейками. См. последний абзац: https://github.com/sheepdog/sheepdog/wiki/Why-The-Performance-Of-My-Cluster-Is-Bad
Mark ☢️
The qemu block driver communicates with only one gateway that is specified during the boot time of the qemu process. And the gateway node calculates object locations based on sheepdog's consistent hashing as you already noticed. It simplifies the assumption about hardware fault e.g., gateway node and qemu processes are executed on a same host so hardware fault can kill both of them at once. Although iSCSI can break this assumption, it has its own mechanism of multipath.
I'm not sure about your motivation of calculating the object location in the block driver, performance improvement?
Mark ☢️
Получается, что в шыпдоге нужно гатевей запускать на тех компах где куему и подключаться грубоговоря на локалхост. Превед миграция.
Mark ☢️
https://github.com/sheepdog/sheepdog/issues/358
Mark ☢️
На этом можно про шыпдог разговор и закончить тащемта
Mark ☢️
@SinTeZoiD это тебе для странички "почему не шипдог, хоть он и быстрее и проще". Там же и про отсутствие возможности настроить чтобы например хранил реплики принудительно в разных стойках
Vlad
миграция qemu в шипдоге работает
Михаил
Vlad
gateway это каждая нода в кластере
Mark ☢️
И когда он умрет, виртуалка повиснет
Mark ☢️
А в цефе не так
Mark ☢️
Поэтому логично было бы наверно гатевей на нове запускать
Vlad
да, шипдог больше чем цеф подходит для гиперконвергентных кластеров
Mark ☢️
да, шипдог больше чем цеф подходит для гиперконвергентных кластеров
Вот это слово мне не понятно вобще
Брандашмыг
для ги-пер-кон-вер-гент-ных
Vlad
это когда строадж и компьют нода совмещена, как в нутаниксе
Брандашмыг
хуле тут непонятного?
Mike
Почитал про овечесобаку. Лучше гластера, но хуже ceph.
Mike
Ибо file based, метаданные хранятся в inode - жесткая привязка к наличию файловой системы.
Метод хеширования простой как качерга - IP/volume name. Возможно может стать проблемой. Сложно сделать карты распределения, как в ceph.
Mark ☢️
Но почему он у них быстрее цефа ? Вот в чем вопрос
Mike
Но почему он у них быстрее цефа ? Вот в чем вопрос
Вопрос больше не в этом, а в том как они делали тест. Как был настроен ceph.
Mark ☢️
Там написано подробно
Mike
И когда были сделаны тесты. Не секрет, что write/read path в ceph не оптимизированы, хоть за последние полтора года скорость чтения подняли существенно.
Mike
Может кому будет интересно: http://florian.ca/ceph-calculator/
 Pavel
Pavel
Может кому будет интересно: http://florian.ca/ceph-calculator/
о, я такое делал только в форме скрипта
Mike
Да, надо бы запилить тоже себе, добавить больше параметров.
 Александр
Александр
А почему 3 ноды
Александр
Дичь ебаная
Mike
там есть кнопочка
Александр
Аа увидел да
Александр
Спасибо
Vladimir
Добрый день! ) А кто как борется c интенсивным ребалансингом всего CEPH кластера при добавлении новых OSD ? У нас в работе порядка 60 OSD, добавление одной OSD утилизирует кластерный канал до 8 гигабит и длится около 2-х часов ) Это при условиии, что средняя заполненность каждой OSD примерно 450GB из 1TB.
Vladimir
Сейчас вывод такой: при добавлении более 2-х OSD в рабочий кластер с 60 OSD (~450 GB утилизация каждой) сеть в 10G ляжет в легкую. Это конечно при условии, что у вас журналы на SSD + на бэкэнде диски 10K
Pavel
--osd_recovery_op_priority 1
—osd_max_backfills 1
—osd_recovery_max_active 1
—osd_recovery_threads 6
Vladimir
--osd_recovery_op_priority 1
—osd_max_backfills 1
—osd_recovery_max_active 1
—osd_recovery_threads 6
Первые три опции у нас есть, osd_recovery_threads нужно видимо попробовать.
VVSina
Ну и добавлять вначале с нулевым весом
Vladimir
Однако у меня есть ощущение, что они как-то странно работают на версии ceph 10.2.2
Pavel
да
VVSina
потом полегонечку... потихонечку..
Pavel
и постепенно прибавлять
Sergey
Threads можно и 2 сделать
Vladimir
Да, с весами и добавляли.. плавно,. Это для эксперимента ввели сразу с полным весом..